 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCai Xu
Multimodal Fusion on Low-quality Data: A Comprehensive Survey
Apr 27, 2024
Multimodal fusion focuses on integrating information from multiple modalities with the goal of more accurate prediction, which has achieved remarkable progress in a wide range of scenarios, including autonomous driving and medical diagnosis. However, the reliability of multimodal fusion remains largely unexplored especially under low-quality data settings. This paper surveys the common challenges and recent advances of multimodal fusion in the wild and presents them in a comprehensive taxonomy. From a data-centric view, we identify four main challenges that are faced by multimodal fusion on low-quality data, namely (1) noisy multimodal data that are contaminated with heterogeneous noises, (2) incomplete multimodal data that some modalities are missing, (3) imbalanced multimodal data that the qualities or properties of different modalities are significantly different and (4) quality-varying multimodal data that the quality of each modality dynamically changes with respect to different samples. This new taxonomy will enable researchers to understand the state of the field and identify several potential directions. We also provide discussion for the open problems in this field together with interesting future research directions.
TruthSR: Trustworthy Sequential Recommender Systems via User-generated Multimodal Content
Apr 26, 2024Sequential recommender systems explore users' preferences and behavioral patterns from their historically generated data. Recently, researchers aim to improve sequential recommendation by utilizing massive user-generated multi-modal content, such as reviews, images, etc. This content often contains inevitable noise. Some studies attempt to reduce noise interference by suppressing cross-modal inconsistent information. However, they could potentially constrain the capturing of personalized user preferences. In addition, it is almost impossible to entirely eliminate noise in diverse user-generated multi-modal content. To solve these problems, we propose a trustworthy sequential recommendation method via noisy user-generated multi-modal content. Specifically, we explicitly capture the consistency and complementarity of user-generated multi-modal content to mitigate noise interference. We also achieve the modeling of the user's multi-modal sequential preferences. In addition, we design a trustworthy decision mechanism that integrates subjective user perspective and objective item perspective to dynamically evaluate the uncertainty of prediction results. Experimental evaluation on four widely-used datasets demonstrates the superior performance of our model compared to state-of-the-art methods. The code is released at https://github.com/FairyMeng/TrustSR.
Trusted Multi-view Learning with Label Noise
Apr 18, 2024Multi-view learning methods often focus on improving decision accuracy while neglecting the decision uncertainty, which significantly restricts their applications in safety-critical applications. To address this issue, researchers propose trusted multi-view methods that learn the class distribution for each instance, enabling the estimation of classification probabilities and uncertainty. However, these methods heavily rely on high-quality ground-truth labels. This motivates us to delve into a new generalized trusted multi-view learning problem: how to develop a reliable multi-view learning model under the guidance of noisy labels? We propose a trusted multi-view noise refining method to solve this problem. We first construct view-opinions using evidential deep neural networks, which consist of belief mass vectors and uncertainty estimates. Subsequently, we design view-specific noise correlation matrices that transform the original opinions into noisy opinions aligned with the noisy labels. Considering label noises originating from low-quality data features and easily-confused classes, we ensure that the diagonal elements of these matrices are inversely proportional to the uncertainty, while incorporating class relations into the off-diagonal elements. Finally, we aggregate the noisy opinions and employ a generalized maximum likelihood loss on the aggregated opinion for model training, guided by the noisy labels. We empirically compare TMNR with state-of-the-art trusted multi-view learning and label noise learning baselines on 5 publicly available datasets. Experiment results show that TMNR outperforms baseline methods on accuracy, reliability and robustness. We promise to release the code and all datasets on Github and show the link here.
Reliable Conflictive Multi-View Learning
Feb 28, 2024Multi-view learning aims to combine multiple features to achieve more comprehensive descriptions of data. Most previous works assume that multiple views are strictly aligned. However, real-world multi-view data may contain low-quality conflictive instances, which show conflictive information in different views. Previous methods for this problem mainly focus on eliminating the conflictive data instances by removing them or replacing conflictive views. Nevertheless, real-world applications usually require making decisions for conflictive instances rather than only eliminating them. To solve this, we point out a new Reliable Conflictive Multi-view Learning (RCML) problem, which requires the model to provide decision results and attached reliabilities for conflictive multi-view data. We develop an Evidential Conflictive Multi-view Learning (ECML) method for this problem. ECML first learns view-specific evidence, which could be termed as the amount of support to each category collected from data. Then, we can construct view-specific opinions consisting of decision results and reliability. In the multi-view fusion stage, we propose a conflictive opinion aggregation strategy and theoretically prove this strategy can exactly model the relation of multi-view common and view-specific reliabilities. Experiments performed on 6 datasets verify the effectiveness of ECML.
Self-supervised Heterogeneous Graph Pre-training Based on Structural Clustering
Oct 19, 2022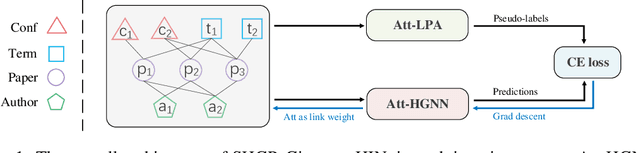

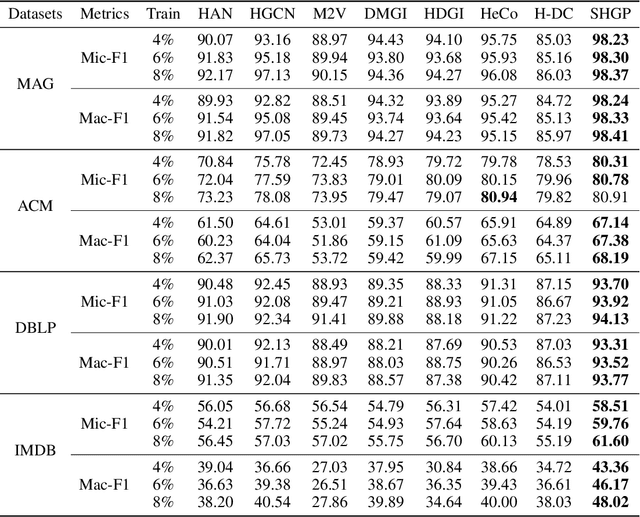
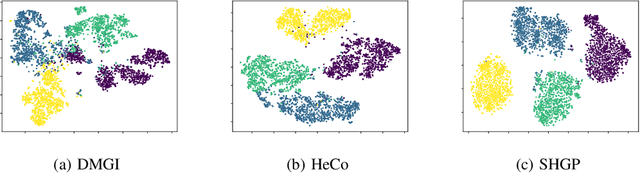
Recent self-supervised pre-training methods on Heterogeneous Information Networks (HINs) have shown promising competitiveness over traditional semi-supervised Heterogeneous Graph Neural Networks (HGNNs). Unfortunately, their performance heavily depends on careful customization of various strategies for generating high-quality positive examples and negative examples, which notably limits their flexibility and generalization ability. In this work, we present SHGP, a novel Self-supervised Heterogeneous Graph Pre-training approach, which does not need to generate any positive examples or negative examples. It consists of two modules that share the same attention-aggregation scheme. In each iteration, the Att-LPA module produces pseudo-labels through structural clustering, which serve as the self-supervision signals to guide the Att-HGNN module to learn object embeddings and attention coefficients. The two modules can effectively utilize and enhance each other, promoting the model to learn discriminative embeddings. Extensive experiments on four real-world datasets demonstrate the superior effectiveness of SHGP against state-of-the-art unsupervised baselines and even semi-supervised baselines. We release our source code at: https://github.com/kepsail/SHGP.
Multi-Agent Cooperative Bidding Games for Multi-Objective Optimization in e-Commercial Sponsored Search
Jun 08, 2021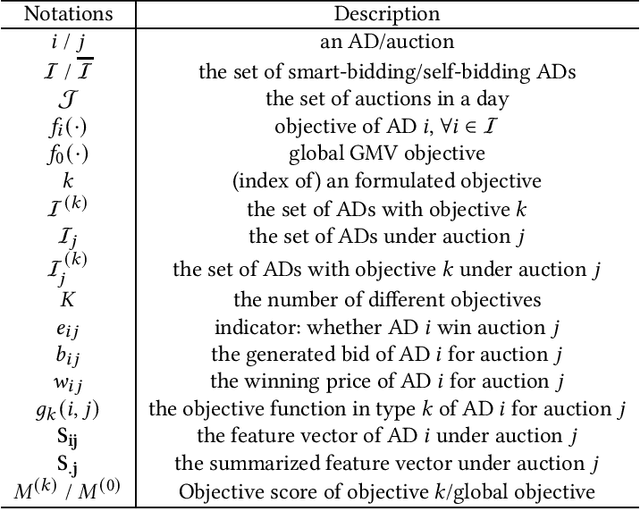

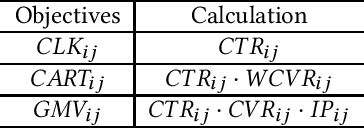
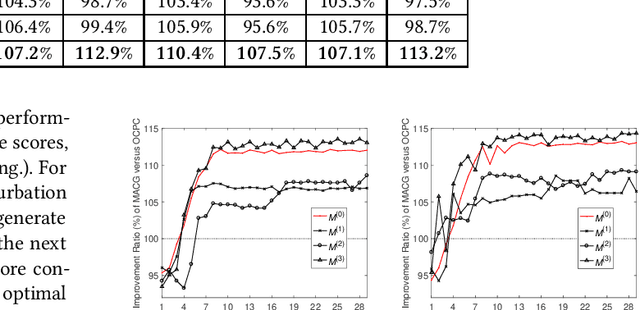
Bid optimization for online advertising from single advertiser's perspective has been thoroughly investigated in both academic research and industrial practice. However, existing work typically assume competitors do not change their bids, i.e., the wining price is fixed, leading to poor performance of the derived solution. Although a few studies use multi-agent reinforcement learning to set up a cooperative game, they still suffer the following drawbacks: (1) They fail to avoid collusion solutions where all the advertisers involved in an auction collude to bid an extremely low price on purpose. (2) Previous works cannot well handle the underlying complex bidding environment, leading to poor model convergence. This problem could be amplified when handling multiple objectives of advertisers which are practical demands but not considered by previous work. In this paper, we propose a novel multi-objective cooperative bid optimization formulation called Multi-Agent Cooperative bidding Games (MACG). MACG sets up a carefully designed multi-objective optimization framework where different objectives of advertisers are incorporated. A global objective to maximize the overall profit of all advertisements is added in order to encourage better cooperation and also to protect self-bidding advertisers. To avoid collusion, we also introduce an extra platform revenue constraint. We analyze the optimal functional form of the bidding formula theoretically and design a policy network accordingly to generate auction-level bids. Then we design an efficient multi-agent evolutionary strategy for model optimization. Offline experiments and online A/B tests conducted on the Taobao platform indicate both single advertiser's objective and global profit have been significantly improved compared to state-of-art methods.