 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Huang
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024
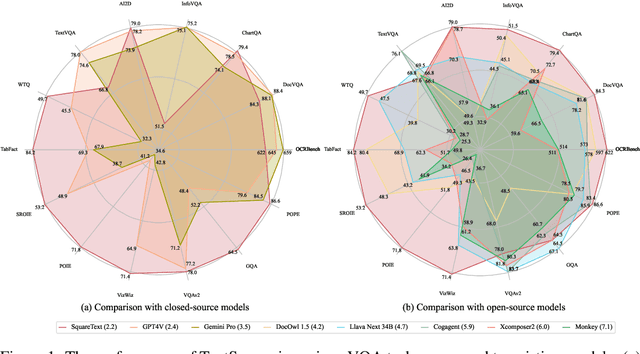

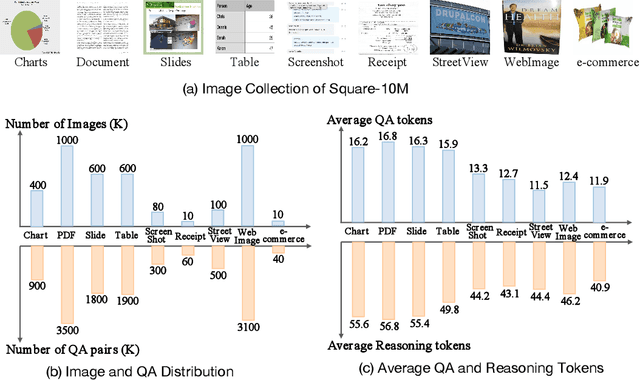
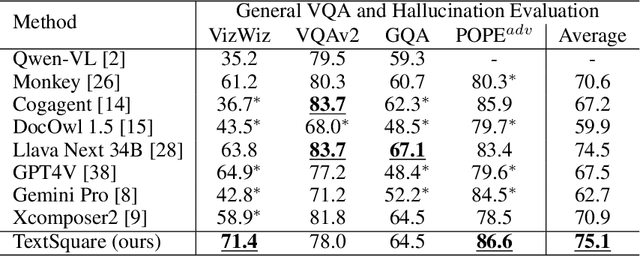
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
Elysium: Exploring Object-level Perception in Videos via MLLM
Mar 29, 2024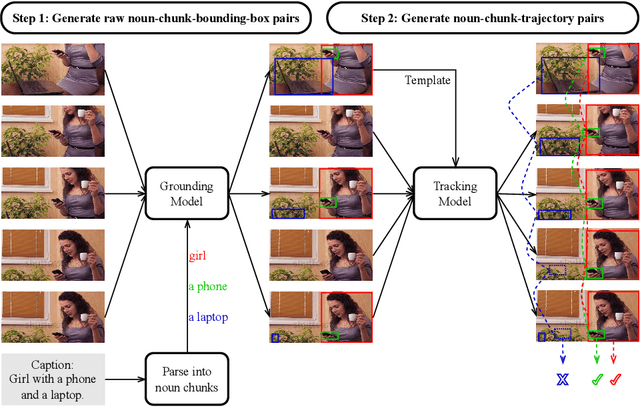
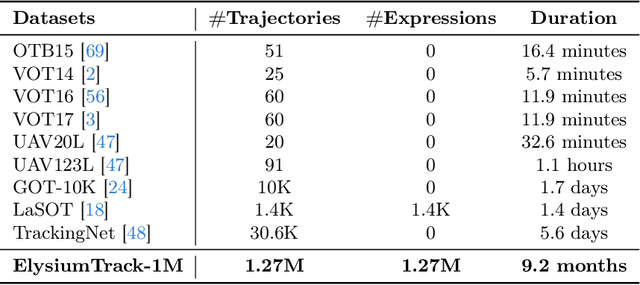

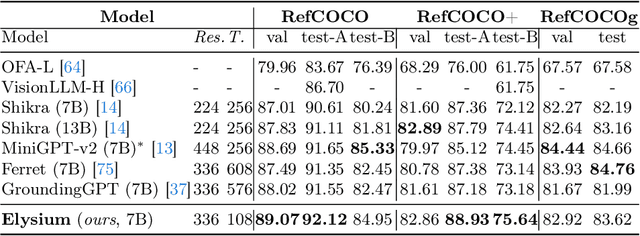
Multi-modal Large Language Models (MLLMs) have demonstrated their ability to perceive objects in still images, but their application in video-related tasks, such as object tracking, remains understudied. This lack of exploration is primarily due to two key challenges. Firstly, extensive pretraining on large-scale video datasets is required to equip MLLMs with the capability to perceive objects across multiple frames and understand inter-frame relationships. Secondly, processing a large number of frames within the context window of Large Language Models (LLMs) can impose a significant computational burden. To address the first challenge, we introduce ElysiumTrack-1M, a large-scale video dataset supported for three tasks: Single Object Tracking (SOT), Referring Single Object Tracking (RSOT), and Video Referring Expression Generation (Video-REG). ElysiumTrack-1M contains 1.27 million annotated video frames with corresponding object boxes and descriptions. Leveraging this dataset, we conduct training of MLLMs and propose a token-compression model T-Selector to tackle the second challenge. Our proposed approach, Elysium: Exploring Object-level Perception in Videos via MLLM, is an end-to-end trainable MLLM that attempts to conduct object-level tasks in videos without requiring any additional plug-in or expert models. All codes and datasets are available at https://github.com/Hon-Wong/Elysium.
PURPLE: Making a Large Language Model a Better SQL Writer
Mar 29, 2024


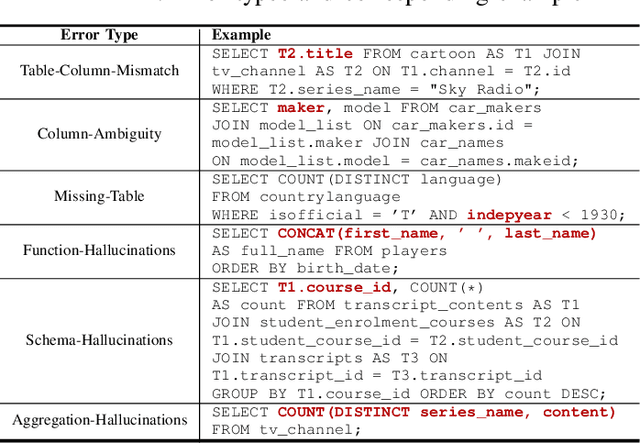
Large Language Model (LLM) techniques play an increasingly important role in Natural Language to SQL (NL2SQL) translation. LLMs trained by extensive corpora have strong natural language understanding and basic SQL generation abilities without additional tuning specific to NL2SQL tasks. Existing LLMs-based NL2SQL approaches try to improve the translation by enhancing the LLMs with an emphasis on user intention understanding. However, LLMs sometimes fail to generate appropriate SQL due to their lack of knowledge in organizing complex logical operator composition. A promising method is to input the LLMs with demonstrations, which include known NL2SQL translations from various databases. LLMs can learn to organize operator compositions from the input demonstrations for the given task. In this paper, we propose PURPLE (Pre-trained models Utilized to Retrieve Prompts for Logical Enhancement), which improves accuracy by retrieving demonstrations containing the requisite logical operator composition for the NL2SQL task on hand, thereby guiding LLMs to produce better SQL translation. PURPLE achieves a new state-of-the-art performance of 80.5% exact-set match accuracy and 87.8% execution match accuracy on the validation set of the popular NL2SQL benchmark Spider. PURPLE maintains high accuracy across diverse benchmarks, budgetary constraints, and various LLMs, showing robustness and cost-effectiveness.
Metasql: A Generate-then-Rank Framework for Natural Language to SQL Translation
Feb 27, 2024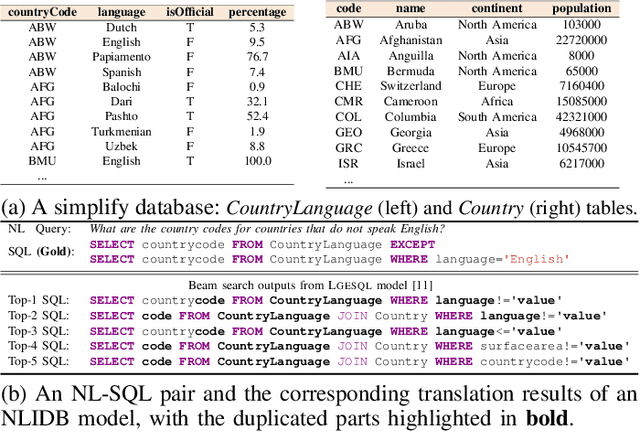

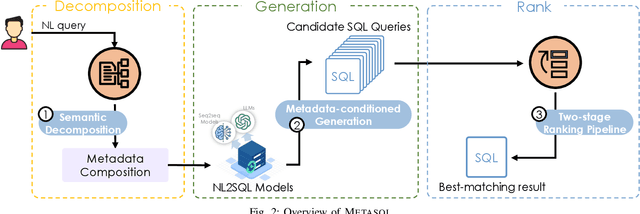

The Natural Language Interface to Databases (NLIDB) empowers non-technical users with database access through intuitive natural language (NL) interactions. Advanced approaches, utilizing neural sequence-to-sequence models or large-scale language models, typically employ auto-regressive decoding to generate unique SQL queries sequentially. While these translation models have greatly improved the overall translation accuracy, surpassing 70% on NLIDB benchmarks, the use of auto-regressive decoding to generate single SQL queries may result in sub-optimal outputs, potentially leading to erroneous translations. In this paper, we propose Metasql, a unified generate-then-rank framework that can be flexibly incorporated with existing NLIDBs to consistently improve their translation accuracy. Metasql introduces query metadata to control the generation of better SQL query candidates and uses learning-to-rank algorithms to retrieve globally optimized queries. Specifically, Metasql first breaks down the meaning of the given NL query into a set of possible query metadata, representing the basic concepts of the semantics. These metadata are then used as language constraints to steer the underlying translation model toward generating a set of candidate SQL queries. Finally, Metasql ranks the candidates to identify the best matching one for the given NL query. Extensive experiments are performed to study Metasql on two public NLIDB benchmarks. The results show that the performance of the translation models can be effectively improved using Metasql.
PaDeLLM-NER: Parallel Decoding in Large Language Models for Named Entity Recognition
Feb 15, 2024
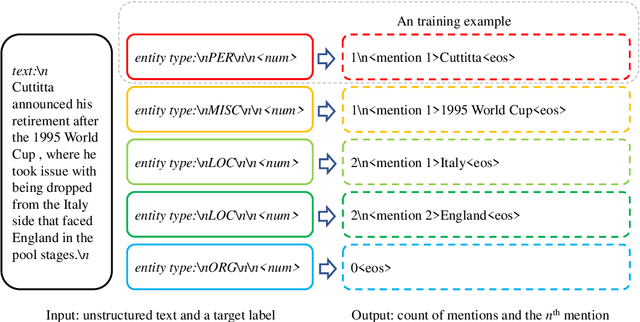
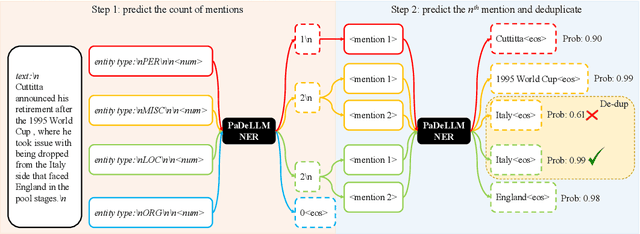
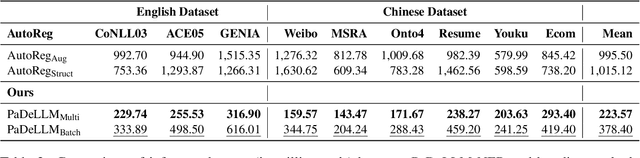
In this study, we aim to reduce generation latency for Named Entity Recognition (NER) with Large Language Models (LLMs). The main cause of high latency in LLMs is the sequential decoding process, which autoregressively generates all labels and mentions for NER, significantly increase the sequence length. To this end, we introduce Parallel Decoding in LLM for NE} (PaDeLLM-NER), a approach that integrates seamlessly into existing generative model frameworks without necessitating additional modules or architectural modifications. PaDeLLM-NER allows for the simultaneous decoding of all mentions, thereby reducing generation latency. Experiments reveal that PaDeLLM-NER significantly increases inference speed that is 1.76 to 10.22 times faster than the autoregressive approach for both English and Chinese. Simultaneously it maintains the quality of predictions as evidenced by the performance that is on par with the state-of-the-art across various datasets.
GloTSFormer: Global Video Text Spotting Transformer
Jan 08, 2024Video Text Spotting (VTS) is a fundamental visual task that aims to predict the trajectories and content of texts in a video. Previous works usually conduct local associations and apply IoU-based distance and complex post-processing procedures to boost performance, ignoring the abundant temporal information and the morphological characteristics in VTS. In this paper, we propose a novel Global Video Text Spotting Transformer GloTSFormer to model the tracking problem as global associations and utilize the Gaussian Wasserstein distance to guide the morphological correlation between frames. Our main contributions can be summarized as three folds. 1). We propose a Transformer-based global tracking method GloTSFormer for VTS and associate multiple frames simultaneously. 2). We introduce a Wasserstein distance-based method to conduct positional associations between frames. 3). We conduct extensive experiments on public datasets. On the ICDAR2015 video dataset, GloTSFormer achieves 56.0 MOTA with 4.6 absolute improvement compared with the previous SOTA method and outperforms the previous Transformer-based method by a significant 8.3 MOTA.
DocPedia: Unleashing the Power of Large Multimodal Model in the Frequency Domain for Versatile Document Understanding
Nov 30, 2023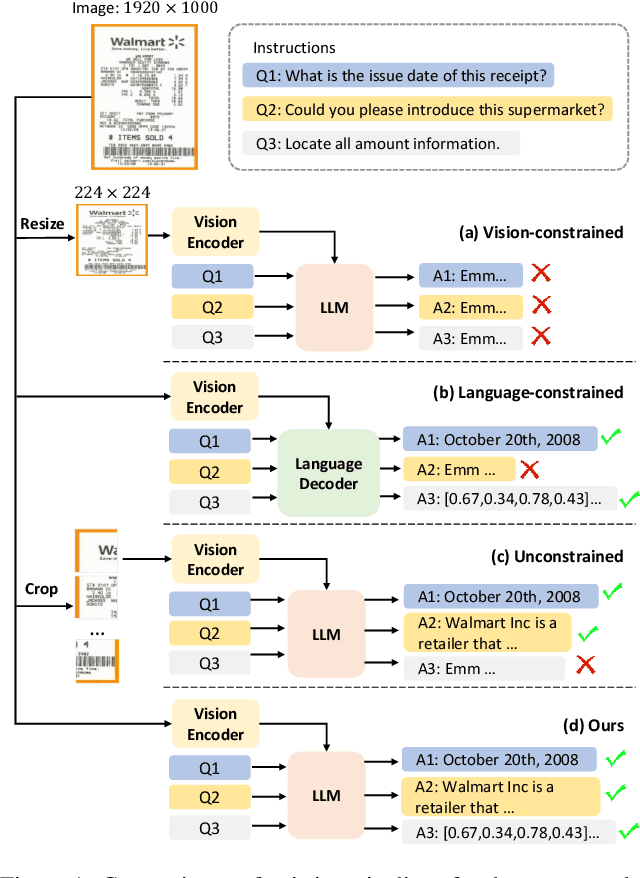
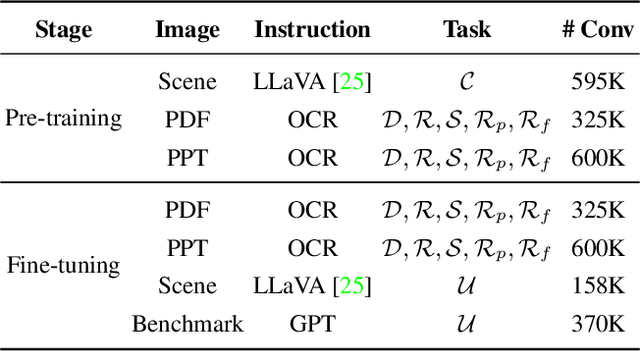
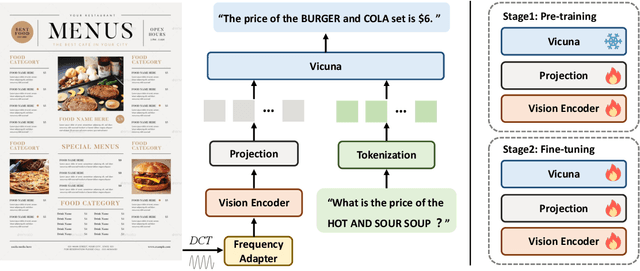
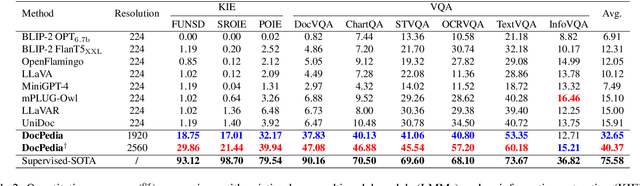
This work presents DocPedia, a novel large multimodal model (LMM) for versatile OCR-free document understanding, capable of parsing images up to 2,560$\times$2,560 resolution. Unlike existing work either struggle with high-resolution documents or give up the large language model thus vision or language ability constrained, our DocPedia directly processes visual input in the frequency domain rather than the pixel space. The unique characteristic enables DocPedia to capture a greater amount of visual and textual information using a limited number of visual tokens. To consistently enhance both perception and comprehension abilities of our model, we develop a dual-stage training strategy and enrich instructions/annotations of all training tasks covering multiple document types. Extensive quantitative and qualitative experiments conducted on various publicly available benchmarks confirm the mutual benefits of jointly learning perception and comprehension tasks. The results provide further evidence of the effectiveness and superior performance of our DocPedia over other methods.
Multi-modal In-Context Learning Makes an Ego-evolving Scene Text Recognizer
Nov 23, 2023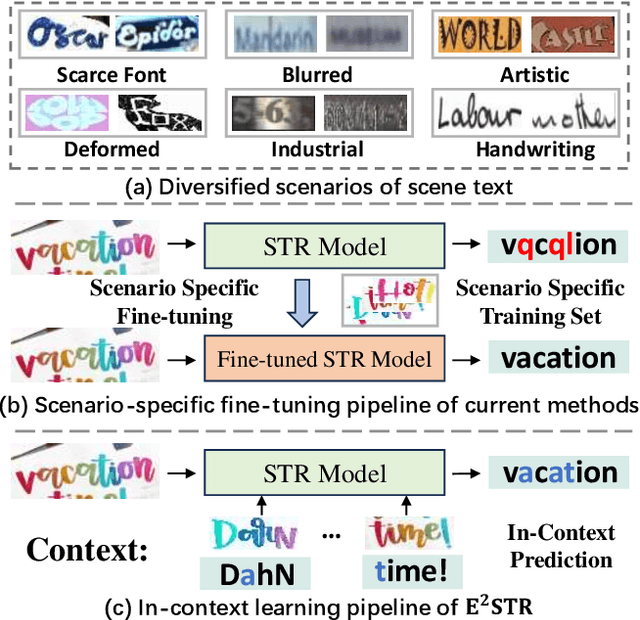

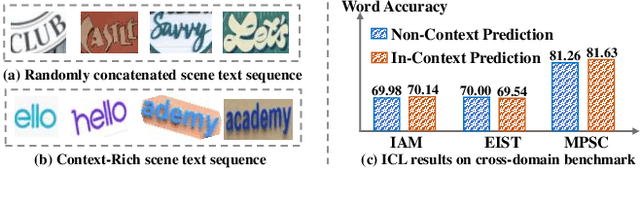

Scene text recognition (STR) in the wild frequently encounters challenges when coping with domain variations, font diversity, shape deformations, etc. A straightforward solution is performing model fine-tuning tailored to a specific scenario, but it is computationally intensive and requires multiple model copies for various scenarios. Recent studies indicate that large language models (LLMs) can learn from a few demonstration examples in a training-free manner, termed "In-Context Learning" (ICL). Nevertheless, applying LLMs as a text recognizer is unacceptably resource-consuming. Moreover, our pilot experiments on LLMs show that ICL fails in STR, mainly attributed to the insufficient incorporation of contextual information from diverse samples in the training stage. To this end, we introduce E$^2$STR, a STR model trained with context-rich scene text sequences, where the sequences are generated via our proposed in-context training strategy. E$^2$STR demonstrates that a regular-sized model is sufficient to achieve effective ICL capabilities in STR. Extensive experiments show that E$^2$STR exhibits remarkable training-free adaptation in various scenarios and outperforms even the fine-tuned state-of-the-art approaches on public benchmarks.
UniDoc: A Universal Large Multimodal Model for Simultaneous Text Detection, Recognition, Spotting and Understanding
Sep 02, 2023



In the era of Large Language Models (LLMs), tremendous strides have been made in the field of multimodal understanding. However, existing advanced algorithms are limited to effectively utilizing the immense representation capabilities and rich world knowledge inherent to these large pre-trained models, and the beneficial connections among tasks within the context of text-rich scenarios have not been sufficiently explored. In this work, we introduce UniDoc, a novel multimodal model equipped with text detection and recognition capabilities, which are deficient in existing approaches. Moreover, UniDoc capitalizes on the beneficial interactions among tasks to enhance the performance of each individual task. To implement UniDoc, we perform unified multimodal instruct tuning on the contributed large-scale instruction following datasets. Quantitative and qualitative experimental results show that UniDoc sets state-of-the-art scores across multiple challenging benchmarks. To the best of our knowledge, this is the first large multimodal model capable of simultaneous text detection, recognition, spotting, and understanding.
ESTextSpotter: Towards Better Scene Text Spotting with Explicit Synergy in Transformer
Aug 20, 2023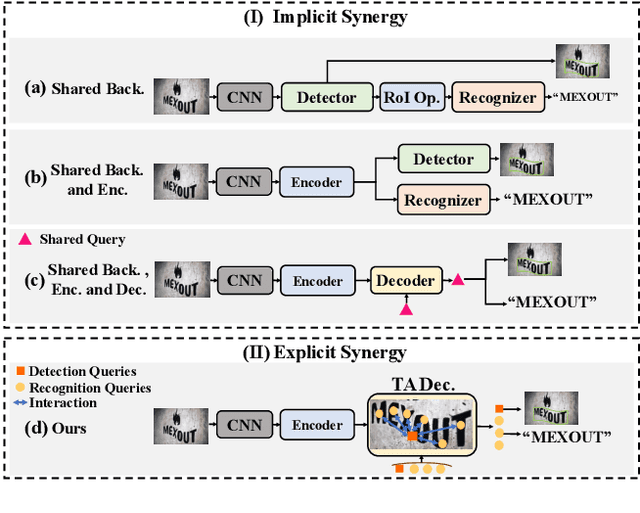
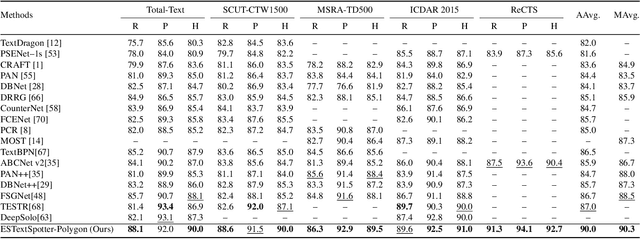

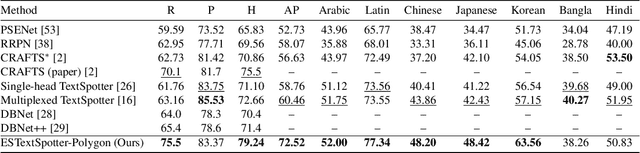
In recent years, end-to-end scene text spotting approaches are evolving to the Transformer-based framework. While previous studies have shown the crucial importance of the intrinsic synergy between text detection and recognition, recent advances in Transformer-based methods usually adopt an implicit synergy strategy with shared query, which can not fully realize the potential of these two interactive tasks. In this paper, we argue that the explicit synergy considering distinct characteristics of text detection and recognition can significantly improve the performance text spotting. To this end, we introduce a new model named Explicit Synergy-based Text Spotting Transformer framework (ESTextSpotter), which achieves explicit synergy by modeling discriminative and interactive features for text detection and recognition within a single decoder. Specifically, we decompose the conventional shared query into task-aware queries for text polygon and content, respectively. Through the decoder with the proposed vision-language communication module, the queries interact with each other in an explicit manner while preserving discriminative patterns of text detection and recognition, thus improving performance significantly. Additionally, we propose a task-aware query initialization scheme to ensure stable training. Experimental results demonstrate that our model significantly outperforms previous state-of-the-art methods. Code is available at https://github.com/mxin262/ESTextSpotter.