 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Feng
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Apr 19, 2024
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
Progressive Multi-modal Conditional Prompt Tuning
Apr 18, 2024Pre-trained vision-language models (VLMs) have shown remarkable generalization capabilities via prompting, which leverages VLMs as knowledge bases to extract information beneficial for downstream tasks. However, existing methods primarily employ uni-modal prompting, which only engages a uni-modal branch, failing to simultaneously adjust vision-language (V-L) features. Additionally, the one-pass forward pipeline in VLM encoding struggles to align V-L features that have a huge gap. Confronting these challenges, we propose a novel method, Progressive Multi-modal conditional Prompt Tuning (ProMPT). ProMPT exploits a recurrent structure, optimizing and aligning V-L features by iteratively utilizing image and current encoding information. It comprises an initialization and a multi-modal iterative evolution (MIE) module. Initialization is responsible for encoding image and text using a VLM, followed by a feature filter that selects text features similar to image. MIE then facilitates multi-modal prompting through class-conditional vision prompting, instance-conditional text prompting, and feature filtering. In each MIE iteration, vision prompts are obtained from the filtered text features via a vision generator, promoting image features to focus more on target object during vision prompting. The encoded image features are fed into a text generator to produce text prompts that are more robust to class shift. Thus, V-L features are progressively aligned, enabling advance from coarse to exact classifications. Extensive experiments are conducted in three settings to evaluate the efficacy of ProMPT. The results indicate that ProMPT outperforms existing methods on average across all settings, demonstrating its superior generalization.
Integration of Self-Supervised BYOL in Semi-Supervised Medical Image Recognition
Apr 16, 2024Image recognition techniques heavily rely on abundant labeled data, particularly in medical contexts. Addressing the challenges associated with obtaining labeled data has led to the prominence of self-supervised learning and semi-supervised learning, especially in scenarios with limited annotated data. In this paper, we proposed an innovative approach by integrating self-supervised learning into semi-supervised models to enhance medical image recognition. Our methodology commences with pre-training on unlabeled data utilizing the BYOL method. Subsequently, we merge pseudo-labeled and labeled datasets to construct a neural network classifier, refining it through iterative fine-tuning. Experimental results on three different datasets demonstrate that our approach optimally leverages unlabeled data, outperforming existing methods in terms of accuracy for medical image recognition.
TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
Apr 15, 2024The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
Enhanced Radar Perception via Multi-Task Learning: Towards Refined Data for Sensor Fusion Applications
Apr 09, 2024Radar and camera fusion yields robustness in perception tasks by leveraging the strength of both sensors. The typical extracted radar point cloud is 2D without height information due to insufficient antennas along the elevation axis, which challenges the network performance. This work introduces a learning-based approach to infer the height of radar points associated with 3D objects. A novel robust regression loss is introduced to address the sparse target challenge. In addition, a multi-task training strategy is employed, emphasizing important features. The average radar absolute height error decreases from 1.69 to 0.25 meters compared to the state-of-the-art height extension method. The estimated target height values are used to preprocess and enrich radar data for downstream perception tasks. Integrating this refined radar information further enhances the performance of existing radar camera fusion models for object detection and depth estimation tasks.
DeepEraser: Deep Iterative Context Mining for Generic Text Eraser
Feb 29, 2024In this work, we present DeepEraser, an effective deep network for generic text removal. DeepEraser utilizes a recurrent architecture that erases the text in an image via iterative operations. Our idea comes from the process of erasing pencil script, where the text area designated for removal is subject to continuous monitoring and the text is attenuated progressively, ensuring a thorough and clean erasure. Technically, at each iteration, an innovative erasing module is deployed, which not only explicitly aggregates the previous erasing progress but also mines additional semantic context to erase the target text. Through iterative refinements, the text regions are progressively replaced with more appropriate content and finally converge to a relatively accurate status. Furthermore, a custom mask generation strategy is introduced to improve the capability of DeepEraser for adaptive text removal, as opposed to indiscriminately removing all the text in an image. Our DeepEraser is notably compact with only 1.4M parameters and trained in an end-to-end manner. To verify its effectiveness, extensive experiments are conducted on several prevalent benchmarks, including SCUT-Syn, SCUT-EnsText, and Oxford Synthetic text dataset. The quantitative and qualitative results demonstrate the effectiveness of our DeepEraser over the state-of-the-art methods, as well as its strong generalization ability in custom mask text removal. The codes and pre-trained models are available at https://github.com/fh2019ustc/DeepEraser
UCE-FID: Using Large Unlabeled, Medium Crowdsourced-Labeled, and Small Expert-Labeled Tweets for Foodborne Illness Detection
Dec 02, 2023Foodborne illnesses significantly impact public health. Deep learning surveillance applications using social media data aim to detect early warning signals. However, labeling foodborne illness-related tweets for model training requires extensive human resources, making it challenging to collect a sufficient number of high-quality labels for tweets within a limited budget. The severe class imbalance resulting from the scarcity of foodborne illness-related tweets among the vast volume of social media further exacerbates the problem. Classifiers trained on a class-imbalanced dataset are biased towards the majority class, making accurate detection difficult. To overcome these challenges, we propose EGAL, a deep learning framework for foodborne illness detection that uses small expert-labeled tweets augmented by crowdsourced-labeled and massive unlabeled data. Specifically, by leveraging tweets labeled by experts as a reward set, EGAL learns to assign a weight of zero to incorrectly labeled tweets to mitigate their negative influence. Other tweets receive proportionate weights to counter-balance the unbalanced class distribution. Extensive experiments on real-world \textit{TWEET-FID} data show that EGAL outperforms strong baseline models across different settings, including varying expert-labeled set sizes and class imbalance ratios. A case study on a multistate outbreak of Salmonella Typhimurium infection linked to packaged salad greens demonstrates how the trained model captures relevant tweets offering valuable outbreak insights. EGAL, funded by the U.S. Department of Agriculture (USDA), has the potential to be deployed for real-time analysis of tweet streaming, contributing to foodborne illness outbreak surveillance efforts.
DocPedia: Unleashing the Power of Large Multimodal Model in the Frequency Domain for Versatile Document Understanding
Nov 30, 2023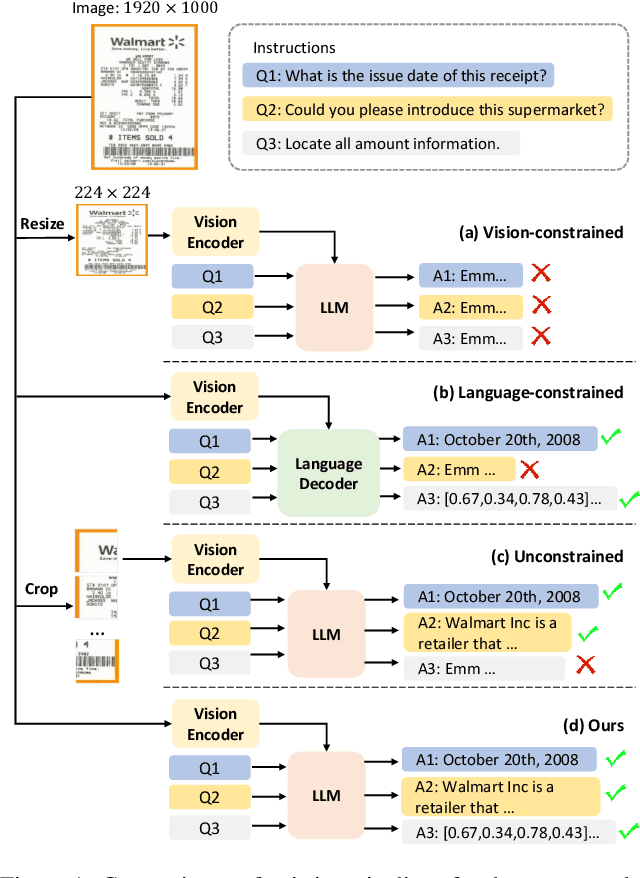
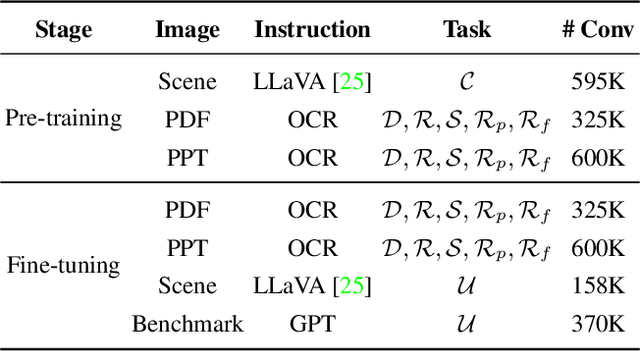
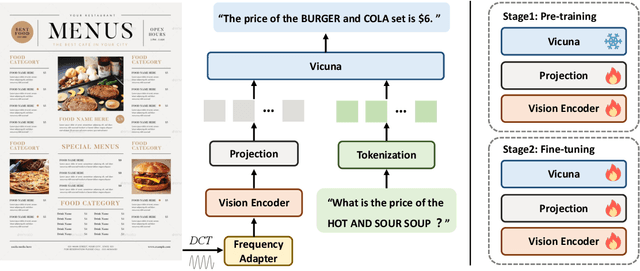
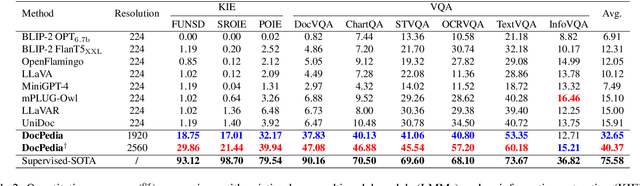
This work presents DocPedia, a novel large multimodal model (LMM) for versatile OCR-free document understanding, capable of parsing images up to 2,560$\times$2,560 resolution. Unlike existing work either struggle with high-resolution documents or give up the large language model thus vision or language ability constrained, our DocPedia directly processes visual input in the frequency domain rather than the pixel space. The unique characteristic enables DocPedia to capture a greater amount of visual and textual information using a limited number of visual tokens. To consistently enhance both perception and comprehension abilities of our model, we develop a dual-stage training strategy and enrich instructions/annotations of all training tasks covering multiple document types. Extensive quantitative and qualitative experiments conducted on various publicly available benchmarks confirm the mutual benefits of jointly learning perception and comprehension tasks. The results provide further evidence of the effectiveness and superior performance of our DocPedia over other methods.
Scalable AI Generative Content for Vehicular Network Semantic Communication
Nov 23, 2023Perceiving vehicles in a driver's blind spot is vital for safe driving. The detection of potentially dangerous vehicles in these blind spots can benefit from vehicular network semantic communication technology. However, efficient semantic communication involves a trade-off between accuracy and delay, especially in bandwidth-limited situations. This paper unveils a scalable Artificial Intelligence Generated Content (AIGC) system that leverages an encoder-decoder architecture. This system converts images into textual representations and reconstructs them into quality-acceptable images, optimizing transmission for vehicular network semantic communication. Moreover, when bandwidth allows, auxiliary information is integrated. The encoder-decoder aims to maintain semantic equivalence with the original images across various tasks. Then the proposed approach employs reinforcement learning to enhance the reliability of the generated contents. Experimental results suggest that the proposed method surpasses the baseline in perceiving vehicles in blind spots and effectively compresses communication data. While this method is specifically designed for driving scenarios, this encoder-decoder architecture also holds potential for wide use across various semantic communication scenarios.
Towards Improving Document Understanding: An Exploration on Text-Grounding via MLLMs
Nov 22, 2023In the field of document understanding, significant advances have been made in the fine-tuning of Multimodal Large Language Models (MLLMs) with instruction-following data. Nevertheless, the potential of text-grounding capability within text-rich scenarios remains underexplored. In this paper, we present a text-grounding document understanding model, termed TGDoc, which addresses this deficiency by enhancing MLLMs with the ability to discern the spatial positioning of text within images. Empirical evidence suggests that text-grounding improves the model's interpretation of textual content, thereby elevating its proficiency in comprehending text-rich images. Specifically, we compile a dataset containing 99K PowerPoint presentations sourced from the internet. We formulate instruction tuning tasks including text detection, recognition, and spotting to facilitate the cohesive alignment between the visual encoder and large language model. Moreover, we curate a collection of text-rich images and prompt the text-only GPT-4 to generate 12K high-quality conversations, featuring textual locations within text-rich scenarios. By integrating text location data into the instructions, TGDoc is adept at discerning text locations during the visual question process. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple text-rich benchmarks, validating the effectiveness of our method.