 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunping Wang
Seeing Beyond Classes: Zero-Shot Grounded Situation Recognition via Language Explainer
Apr 24, 2024
Benefiting from strong generalization ability, pre-trained vision language models (VLMs), e.g., CLIP, have been widely utilized in zero-shot scene understanding. Unlike simple recognition tasks, grounded situation recognition (GSR) requires the model not only to classify salient activity (verb) in the image, but also to detect all semantic roles that participate in the action. This complex task usually involves three steps: verb recognition, semantic role grounding, and noun recognition. Directly employing class-based prompts with VLMs and grounding models for this task suffers from several limitations, e.g., it struggles to distinguish ambiguous verb concepts, accurately localize roles with fixed verb-centric template1 input, and achieve context-aware noun predictions. In this paper, we argue that these limitations stem from the mode's poor understanding of verb/noun classes. To this end, we introduce a new approach for zero-shot GSR via Language EXplainer (LEX), which significantly boosts the model's comprehensive capabilities through three explainers: 1) verb explainer, which generates general verb-centric descriptions to enhance the discriminability of different verb classes; 2) grounding explainer, which rephrases verb-centric templates for clearer understanding, thereby enhancing precise semantic role localization; and 3) noun explainer, which creates scene-specific noun descriptions to ensure context-aware noun recognition. By equipping each step of the GSR process with an auxiliary explainer, LEX facilitates complex scene understanding in real-world scenarios. Our extensive validations on the SWiG dataset demonstrate LEX's effectiveness and interoperability in zero-shot GSR.
Graph-Skeleton: ~1% Nodes are Sufficient to Represent Billion-Scale Graph
Feb 14, 2024Due to the ubiquity of graph data on the web, web graph mining has become a hot research spot. Nonetheless, the prevalence of large-scale web graphs in real applications poses significant challenges to storage, computational capacity and graph model design. Despite numerous studies to enhance the scalability of graph models, a noticeable gap remains between academic research and practical web graph mining applications. One major cause is that in most industrial scenarios, only a small part of nodes in a web graph are actually required to be analyzed, where we term these nodes as target nodes, while others as background nodes. In this paper, we argue that properly fetching and condensing the background nodes from massive web graph data might be a more economical shortcut to tackle the obstacles fundamentally. To this end, we make the first attempt to study the problem of massive background nodes compression for target nodes classification. Through extensive experiments, we reveal two critical roles played by the background nodes in target node classification: enhancing structural connectivity between target nodes, and feature correlation with target nodes. Followingthis, we propose a novel Graph-Skeleton1 model, which properly fetches the background nodes, and further condenses the semantic and topological information of background nodes within similar target-background local structures. Extensive experiments on various web graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, for MAG240M dataset with 0.24 billion nodes, our generated skeleton graph achieves highly comparable performance while only containing 1.8% nodes of the original graph.
One Graph Model for Cross-domain Dynamic Link Prediction
Feb 03, 2024This work proposes DyExpert, a dynamic graph model for cross-domain link prediction. It can explicitly model historical evolving processes to learn the evolution pattern of a specific downstream graph and subsequently make pattern-specific link predictions. DyExpert adopts a decode-only transformer and is capable of efficiently parallel training and inference by \textit{conditioned link generation} that integrates both evolution modeling and link prediction. DyExpert is trained by extensive dynamic graphs across diverse domains, comprising 6M dynamic edges. Extensive experiments on eight untrained graphs demonstrate that DyExpert achieves state-of-the-art performance in cross-domain link prediction. Compared to the advanced baseline under the same setting, DyExpert achieves an average of 11.40% improvement Average Precision across eight graphs. More impressive, it surpasses the fully supervised performance of 8 advanced baselines on 6 untrained graphs.
Fine-tuning Graph Neural Networks by Preserving Graph Generative Patterns
Dec 21, 2023Recently, the paradigm of pre-training and fine-tuning graph neural networks has been intensively studied and applied in a wide range of graph mining tasks. Its success is generally attributed to the structural consistency between pre-training and downstream datasets, which, however, does not hold in many real-world scenarios. Existing works have shown that the structural divergence between pre-training and downstream graphs significantly limits the transferability when using the vanilla fine-tuning strategy. This divergence leads to model overfitting on pre-training graphs and causes difficulties in capturing the structural properties of the downstream graphs. In this paper, we identify the fundamental cause of structural divergence as the discrepancy of generative patterns between the pre-training and downstream graphs. Furthermore, we propose G-Tuning to preserve the generative patterns of downstream graphs. Given a downstream graph G, the core idea is to tune the pre-trained GNN so that it can reconstruct the generative patterns of G, the graphon W. However, the exact reconstruction of a graphon is known to be computationally expensive. To overcome this challenge, we provide a theoretical analysis that establishes the existence of a set of alternative graphons called graphon bases for any given graphon. By utilizing a linear combination of these graphon bases, we can efficiently approximate W. This theoretical finding forms the basis of our proposed model, as it enables effective learning of the graphon bases and their associated coefficients. Compared with existing algorithms, G-Tuning demonstrates an average improvement of 0.5% and 2.6% on in-domain and out-of-domain transfer learning experiments, respectively.
Towards Fair Graph Federated Learning via Incentive Mechanisms
Dec 20, 2023Graph federated learning (FL) has emerged as a pivotal paradigm enabling multiple agents to collaboratively train a graph model while preserving local data privacy. Yet, current efforts overlook a key issue: agents are self-interested and would hesitant to share data without fair and satisfactory incentives. This paper is the first endeavor to address this issue by studying the incentive mechanism for graph federated learning. We identify a unique phenomenon in graph federated learning: the presence of agents posing potential harm to the federation and agents contributing with delays. This stands in contrast to previous FL incentive mechanisms that assume all agents contribute positively and in a timely manner. In view of this, this paper presents a novel incentive mechanism tailored for fair graph federated learning, integrating incentives derived from both model gradient and payoff. To achieve this, we first introduce an agent valuation function aimed at quantifying agent contributions through the introduction of two criteria: gradient alignment and graph diversity. Moreover, due to the high heterogeneity in graph federated learning, striking a balance between accuracy and fairness becomes particularly crucial. We introduce motif prototypes to enhance accuracy, communicated between the server and agents, enhancing global model aggregation and aiding agents in local model optimization. Extensive experiments show that our model achieves the best trade-off between accuracy and the fairness of model gradient, as well as superior payoff fairness.
Better with Less: A Data-Active Perspective on Pre-Training Graph Neural Networks
Nov 21, 2023Pre-training on graph neural networks (GNNs) aims to learn transferable knowledge for downstream tasks with unlabeled data, and it has recently become an active research area. The success of graph pre-training models is often attributed to the massive amount of input data. In this paper, however, we identify the curse of big data phenomenon in graph pre-training: more training data do not necessarily lead to better downstream performance. Motivated by this observation, we propose a better-with-less framework for graph pre-training: fewer, but carefully chosen data are fed into a GNN model to enhance pre-training. The proposed pre-training pipeline is called the data-active graph pre-training (APT) framework, and is composed of a graph selector and a pre-training model. The graph selector chooses the most representative and instructive data points based on the inherent properties of graphs as well as predictive uncertainty. The proposed predictive uncertainty, as feedback from the pre-training model, measures the confidence level of the model in the data. When fed with the chosen data, on the other hand, the pre-training model grasps an initial understanding of the new, unseen data, and at the same time attempts to remember the knowledge learned from previous data. Therefore, the integration and interaction between these two components form a unified framework (APT), in which graph pre-training is performed in a progressive and iterative way. Experiment results show that the proposed APT is able to obtain an efficient pre-training model with fewer training data and better downstream performance.
Compositional Feature Augmentation for Unbiased Scene Graph Generation
Aug 13, 2023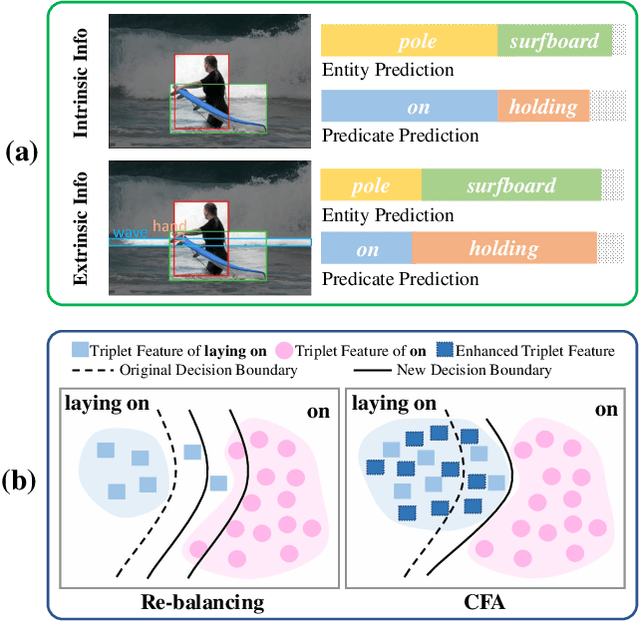
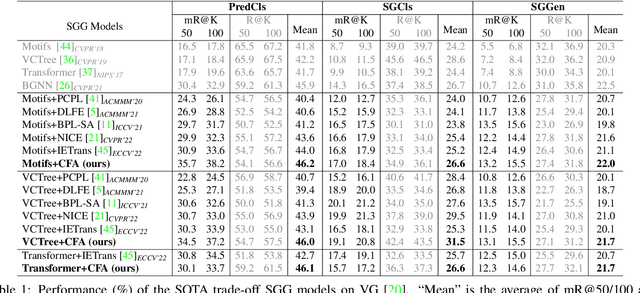
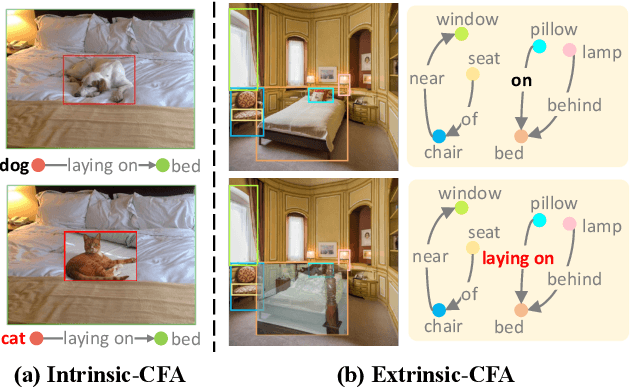
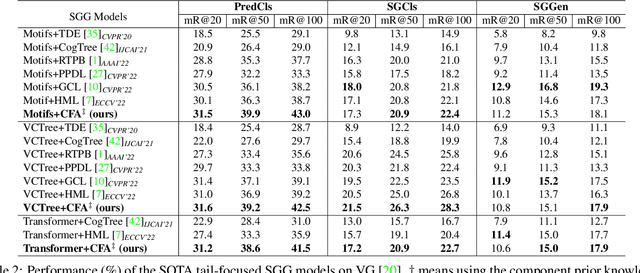
Scene Graph Generation (SGG) aims to detect all the visual relation triplets <sub, pred, obj> in a given image. With the emergence of various advanced techniques for better utilizing both the intrinsic and extrinsic information in each relation triplet, SGG has achieved great progress over the recent years. However, due to the ubiquitous long-tailed predicate distributions, today's SGG models are still easily biased to the head predicates. Currently, the most prevalent debiasing solutions for SGG are re-balancing methods, e.g., changing the distributions of original training samples. In this paper, we argue that all existing re-balancing strategies fail to increase the diversity of the relation triplet features of each predicate, which is critical for robust SGG. To this end, we propose a novel Compositional Feature Augmentation (CFA) strategy, which is the first unbiased SGG work to mitigate the bias issue from the perspective of increasing the diversity of triplet features. Specifically, we first decompose each relation triplet feature into two components: intrinsic feature and extrinsic feature, which correspond to the intrinsic characteristics and extrinsic contexts of a relation triplet, respectively. Then, we design two different feature augmentation modules to enrich the feature diversity of original relation triplets by replacing or mixing up either their intrinsic or extrinsic features from other samples. Due to its model-agnostic nature, CFA can be seamlessly incorporated into various SGG frameworks. Extensive ablations have shown that CFA achieves a new state-of-the-art performance on the trade-off between different metrics.
When to Pre-Train Graph Neural Networks? An Answer from Data Generation Perspective!
Apr 03, 2023
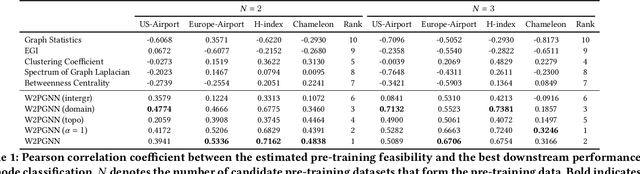


Recently, graph pre-training has attracted wide research attention, which aims to learn transferable knowledge from unlabeled graph data so as to improve downstream performance. Despite these recent attempts, the negative transfer is a major issue when applying graph pre-trained models to downstream tasks. Existing works made great efforts on the issue of what to pre-train and how to pre-train by designing a number of graph pre-training and fine-tuning strategies. However, there are indeed cases where no matter how advanced the strategy is, the "pre-train and fine-tune" paradigm still cannot achieve clear benefits. This paper introduces a generic framework W2PGNN to answer the crucial question of when to pre-train (i.e., in what situations could we take advantage of graph pre-training) before performing effortful pre-training or fine-tuning. We start from a new perspective to explore the complex generative mechanisms from the pre-training data to downstream data. In particular, W2PGNN first fits the pre-training data into graphon bases, each element of graphon basis (i.e., a graphon) identifies a fundamental transferable pattern shared by a collection of pre-training graphs. All convex combinations of graphon bases give rise to a generator space, from which graphs generated form the solution space for those downstream data that can benefit from pre-training. In this manner, the feasibility of pre-training can be quantified as the generation probability of the downstream data from any generator in the generator space. W2PGNN provides three broad applications, including providing the application scope of graph pre-trained models, quantifying the feasibility of performing pre-training, and helping select pre-training data to enhance downstream performance. We give a theoretically sound solution for the first application and extensive empirical justifications for the latter two applications.
Prompt Tuning for Graph Neural Networks
Sep 30, 2022

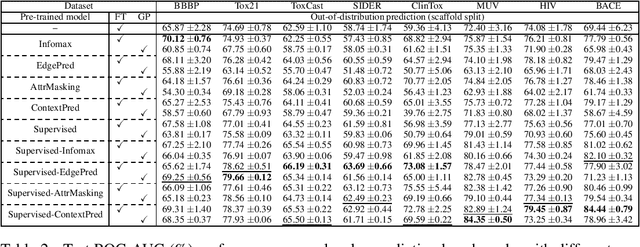

In recent years, prompt tuning has set off a research boom in the adaptation of pre-trained models. In this paper, we propose Graph Prompt as an efficient and effective alternative to full fine-tuning for adapting the pre-trianed GNN models to downstream tasks. To the best of our knowledge, we are the first to explore the effectiveness of prompt tuning on existing pre-trained GNN models. Specifically, without tuning the parameters of the pre-trained GNN model, we train a task-specific graph prompt that provides graph-level transformations on the downstream graphs during the adaptation stage. Then, we introduce a concrete implementation of the graph prompt, called GP-Feature (GPF), which adds learnable perturbations to the feature space of the downstream graph. GPF has a strong expressive ability that it can modify both the node features and the graph structure implicitly. Accordingly, we demonstrate that GPF can achieve the approximately equivalent effect of any graph-level transformations under most existing pre-trained GNN models. We validate the effectiveness of GPF on numerous pre-trained GNN models, and the experimental results show that with a small amount (about 0.1% of that for fine-tuning ) of tunable parameters, GPF can achieve comparable performances as fine-tuning, and even obtain significant performance gains in some cases.
DGraph: A Large-Scale Financial Dataset for Graph Anomaly Detection
Jul 12, 2022

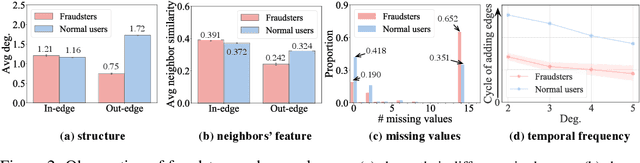
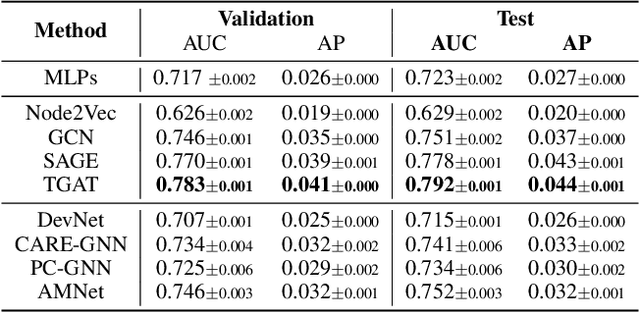
Graph Anomaly Detection (GAD) has recently become a hot research spot due to its practicability and theoretical value. Since GAD emphasizes the application and the rarity of anomalous samples, enriching the varieties of its datasets is a fundamental work. Thus, this paper present DGraph, a real-world dynamic graph in the finance domain. DGraph overcomes many limitations of current GAD datasets. It contains about 3M nodes, 4M dynamic edges, and 1M ground-truth nodes. We provide a comprehensive observation of DGraph, revealing that anomalous nodes and normal nodes generally have different structures, neighbor distribution, and temporal dynamics. Moreover, it suggests that those unlabeled nodes are also essential for detecting fraudsters. Furthermore, we conduct extensive experiments on DGraph. Observation and experiments demonstrate that DGraph is propulsive to advance GAD research and enable in-depth exploration of anomalous nodes.