 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaire Cardie
Adapting Fake News Detection to the Era of Large Language Models
Nov 02, 2023
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts \cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
Probing Representations for Document-level Event Extraction
Oct 23, 2023The probing classifiers framework has been employed for interpreting deep neural network models for a variety of natural language processing (NLP) applications. Studies, however, have largely focused on sentencelevel NLP tasks. This work is the first to apply the probing paradigm to representations learned for document-level information extraction (IE). We designed eight embedding probes to analyze surface, semantic, and event-understanding capabilities relevant to document-level event extraction. We apply them to the representations acquired by learning models from three different LLM-based document-level IE approaches on a standard dataset. We found that trained encoders from these models yield embeddings that can modestly improve argument detections and labeling but only slightly enhance event-level tasks, albeit trade-offs in information helpful for coherence and event-type prediction. We further found that encoder models struggle with document length and cross-sentence discourse.
Policy-Gradient Training of Language Models for Ranking
Oct 06, 2023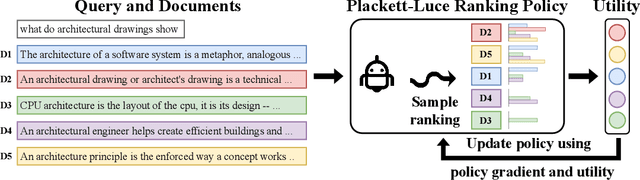


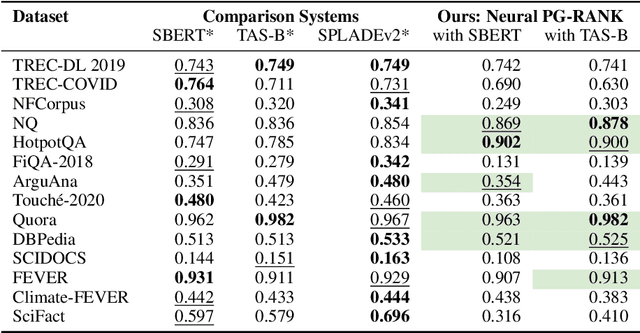
Text retrieval plays a crucial role in incorporating factual knowledge for decision making into language processing pipelines, ranging from chat-based web search to question answering systems. Current state-of-the-art text retrieval models leverage pre-trained large language models (LLMs) to achieve competitive performance, but training LLM-based retrievers via typical contrastive losses requires intricate heuristics, including selecting hard negatives and using additional supervision as learning signals. This reliance on heuristics stems from the fact that the contrastive loss itself is heuristic and does not directly optimize the downstream metrics of decision quality at the end of the processing pipeline. To address this issue, we introduce Neural PG-RANK, a novel training algorithm that learns to rank by instantiating a LLM as a Plackett-Luce ranking policy. Neural PG-RANK provides a principled method for end-to-end training of retrieval models as part of larger decision systems via policy gradient, with little reliance on complex heuristics, and it effectively unifies the training objective with downstream decision-making quality. We conduct extensive experiments on various text retrieval benchmarks. The results demonstrate that when the training objective aligns with the evaluation setup, Neural PG-RANK yields remarkable in-domain performance improvement, with substantial out-of-domain generalization to some critical datasets employed in downstream question answering tasks.
Abductive Commonsense Reasoning Exploiting Mutually Exclusive Explanations
May 24, 2023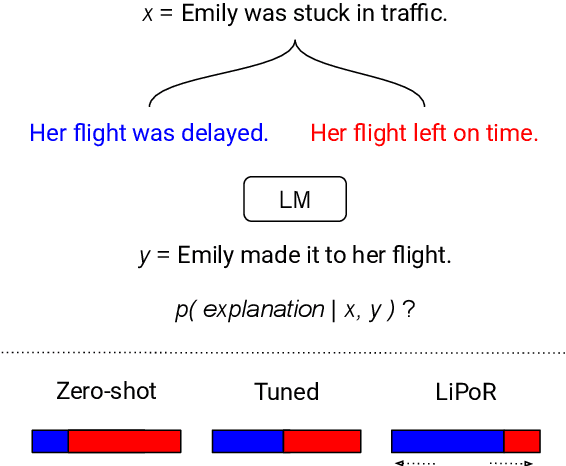


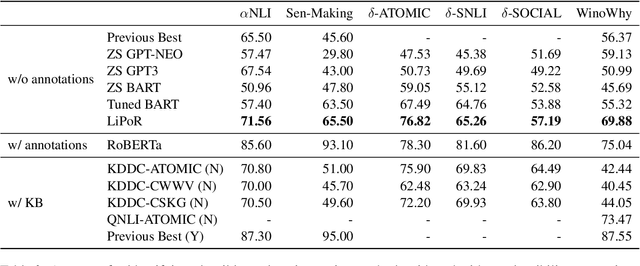
Abductive reasoning aims to find plausible explanations for an event. This style of reasoning is critical for commonsense tasks where there are often multiple plausible explanations. Existing approaches for abductive reasoning in natural language processing (NLP) often rely on manually generated annotations for supervision; however, such annotations can be subjective and biased. Instead of using direct supervision, this work proposes an approach for abductive commonsense reasoning that exploits the fact that only a subset of explanations is correct for a given context. The method uses posterior regularization to enforce a mutual exclusion constraint, encouraging the model to learn the distinction between fluent explanations and plausible ones. We evaluate our approach on a diverse set of abductive reasoning datasets; experimental results show that our approach outperforms or is comparable to directly applying pretrained language models in a zero-shot manner and other knowledge-augmented zero-shot methods.
HOP, UNION, GENERATE: Explainable Multi-hop Reasoning without Rationale Supervision
May 23, 2023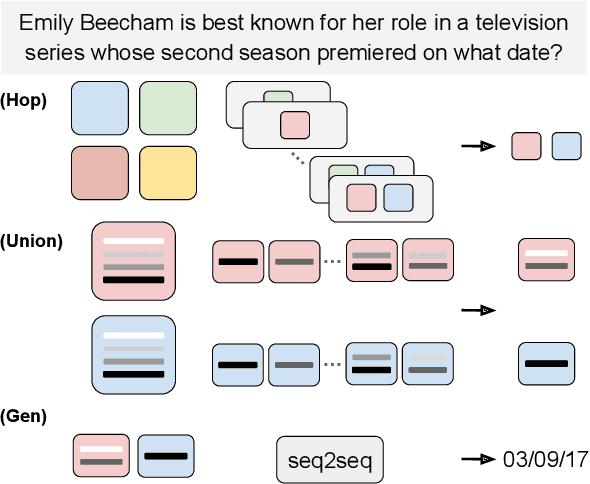

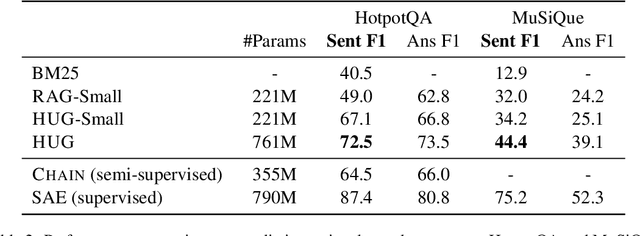
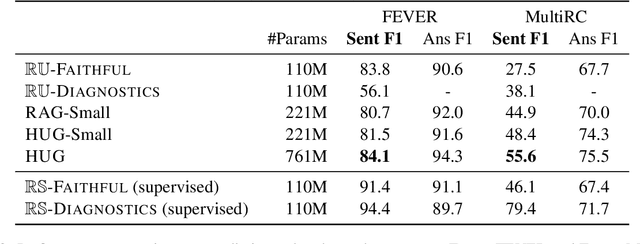
Explainable multi-hop question answering (QA) not only predicts answers but also identifies rationales, i. e. subsets of input sentences used to derive the answers. This problem has been extensively studied under the supervised setting, where both answer and rationale annotations are given. Because rationale annotations are expensive to collect and not always available, recent efforts have been devoted to developing methods that do not rely on supervision for rationales. However, such methods have limited capacities in modeling interactions between sentences, let alone reasoning across multiple documents. This work proposes a principled, probabilistic approach for training explainable multi-hop QA systems without rationale supervision. Our approach performs multi-hop reasoning by explicitly modeling rationales as sets, enabling the model to capture interactions between documents and sentences within a document. Experimental results show that our approach is more accurate at selecting rationales than the previous methods, while maintaining similar accuracy in predicting answers.
Fashionpedia-Ads: Do Your Favorite Advertisements Reveal Your Fashion Taste?
May 03, 2023
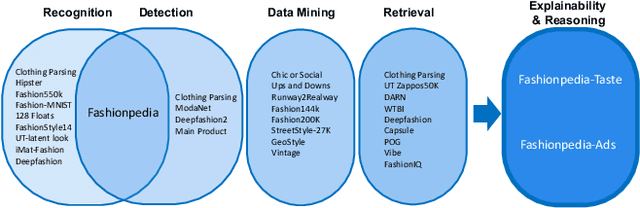


Consumers are exposed to advertisements across many different domains on the internet, such as fashion, beauty, car, food, and others. On the other hand, fashion represents second highest e-commerce shopping category. Does consumer digital record behavior on various fashion ad images reveal their fashion taste? Does ads from other domains infer their fashion taste as well? In this paper, we study the correlation between advertisements and fashion taste. Towards this goal, we introduce a new dataset, Fashionpedia-Ads, which asks subjects to provide their preferences on both ad (fashion, beauty, car, and dessert) and fashion product (social network and e-commerce style) images. Furthermore, we exhaustively collect and annotate the emotional, visual and textual information on the ad images from multi-perspectives (abstractive level, physical level, captions, and brands). We open-source Fashionpedia-Ads to enable future studies and encourage more approaches to interpretability research between advertisements and fashion taste.
Fashionpedia-Taste: A Dataset towards Explaining Human Fashion Taste
May 03, 2023
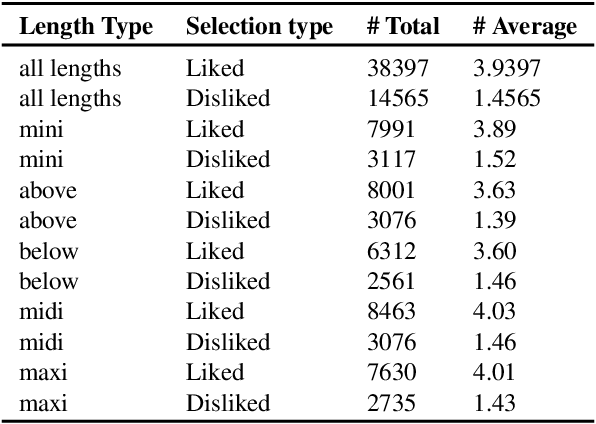

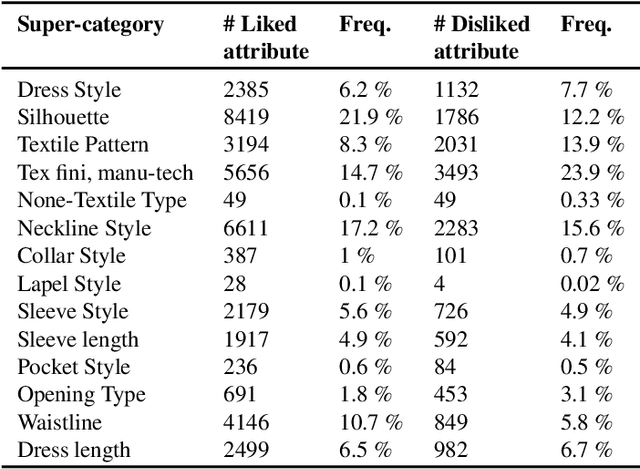
Existing fashion datasets do not consider the multi-facts that cause a consumer to like or dislike a fashion image. Even two consumers like a same fashion image, they could like this image for total different reasons. In this paper, we study the reason why a consumer like a certain fashion image. Towards this goal, we introduce an interpretability dataset, Fashionpedia-taste, consist of rich annotation to explain why a subject like or dislike a fashion image from the following 3 perspectives: 1) localized attributes; 2) human attention; 3) caption. Furthermore, subjects are asked to provide their personal attributes and preference on fashion, such as personality and preferred fashion brands. Our dataset makes it possible for researchers to build computational models to fully understand and interpret human fashion taste from different humanistic perspectives and modalities.
Automatic Error Analysis for Document-level Information Extraction
Sep 15, 2022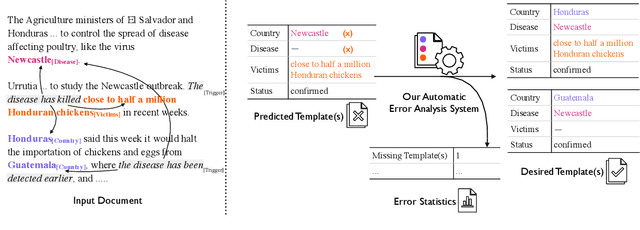
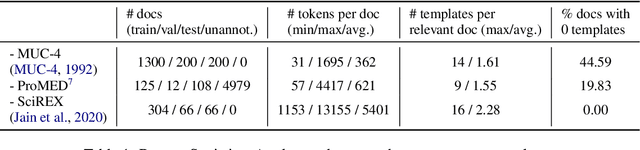
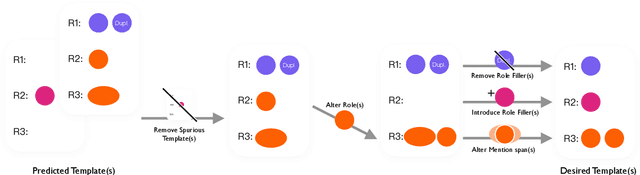
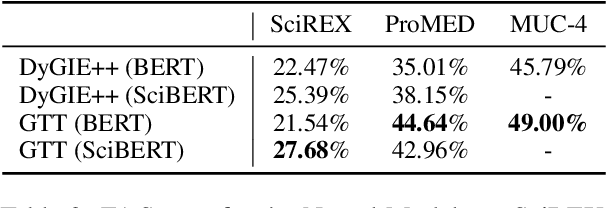
Document-level information extraction (IE) tasks have recently begun to be revisited in earnest using the end-to-end neural network techniques that have been successful on their sentence-level IE counterparts. Evaluation of the approaches, however, has been limited in a number of dimensions. In particular, the precision/recall/F1 scores typically reported provide few insights on the range of errors the models make. We build on the work of Kummerfeld and Klein (2013) to propose a transformation-based framework for automating error analysis in document-level event and (N-ary) relation extraction. We employ our framework to compare two state-of-the-art document-level template-filling approaches on datasets from three domains; and then, to gauge progress in IE since its inception 30 years ago, vs. four systems from the MUC-4 (1992) evaluation.
* Accepted to ACL 2022 Main Conference. First three authors contributed equally to this work
Compositional Task-Oriented Parsing as Abstractive Question Answering
May 04, 2022
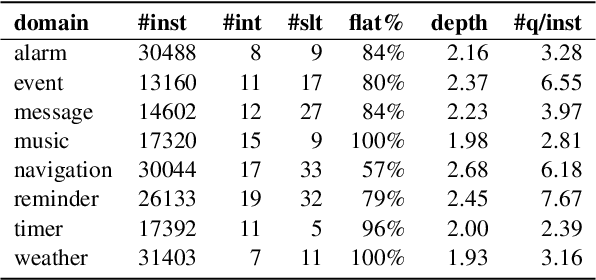
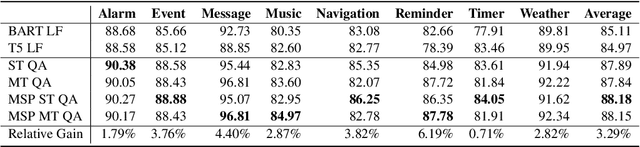

Task-oriented parsing (TOP) aims to convert natural language into machine-readable representations of specific tasks, such as setting an alarm. A popular approach to TOP is to apply seq2seq models to generate linearized parse trees. A more recent line of work argues that pretrained seq2seq models are better at generating outputs that are themselves natural language, so they replace linearized parse trees with canonical natural-language paraphrases that can then be easily translated into parse trees, resulting in so-called naturalized parsers. In this work we continue to explore naturalized semantic parsing by presenting a general reduction of TOP to abstractive question answering that overcomes some limitations of canonical paraphrasing. Experimental results show that our QA-based technique outperforms state-of-the-art methods in full-data settings while achieving dramatic improvements in few-shot settings.
Visual Prompt Tuning
Mar 23, 2022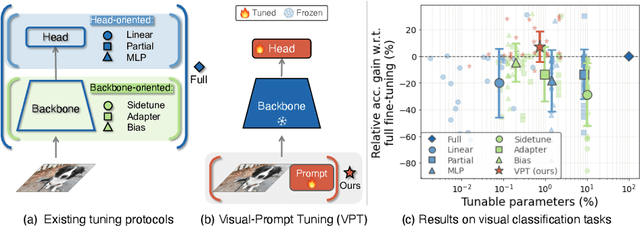
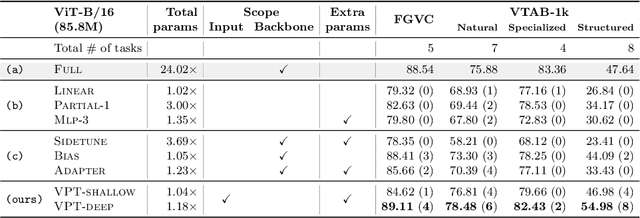
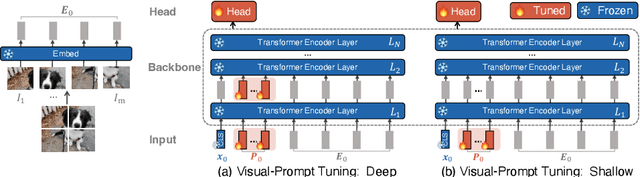
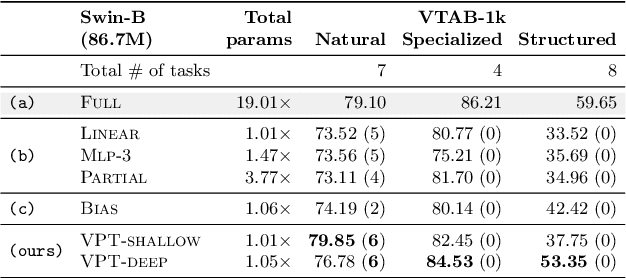
The current modus operandi in adapting pre-trained models involves updating all the backbone parameters, ie, full fine-tuning. This paper introduces Visual Prompt Tuning (VPT) as an efficient and effective alternative to full fine-tuning for large-scale Transformer models in vision. Taking inspiration from recent advances in efficiently tuning large language models, VPT introduces only a small amount (less than 1% of model parameters) of trainable parameters in the input space while keeping the model backbone frozen. Via extensive experiments on a wide variety of downstream recognition tasks, we show that VPT achieves significant performance gains compared to other parameter efficient tuning protocols. Most importantly, VPT even outperforms full fine-tuning in many cases across model capacities and training data scales, while reducing per-task storage cost.