 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDengpan Ye
Trinity Detector:text-assisted and attention mechanisms based spectral fusion for diffusion generation image detection
Apr 26, 2024
Artificial Intelligence Generated Content (AIGC) techniques, represented by text-to-image generation, have led to a malicious use of deep forgeries, raising concerns about the trustworthiness of multimedia content. Adapting traditional forgery detection methods to diffusion models proves challenging. Thus, this paper proposes a forgery detection method explicitly designed for diffusion models called Trinity Detector. Trinity Detector incorporates coarse-grained text features through a CLIP encoder, coherently integrating them with fine-grained artifacts in the pixel domain for comprehensive multimodal detection. To heighten sensitivity to diffusion-generated image features, a Multi-spectral Channel Attention Fusion Unit (MCAF) is designed, extracting spectral inconsistencies through adaptive fusion of diverse frequency bands and further integrating spatial co-occurrence of the two modalities. Extensive experimentation validates that our Trinity Detector method outperforms several state-of-the-art methods, our performance is competitive across all datasets and up to 17.6\% improvement in transferability in the diffusion datasets.
Double Privacy Guard: Robust Traceable Adversarial Watermarking against Face Recognition
Apr 23, 2024The wide deployment of Face Recognition (FR) systems poses risks of privacy leakage. One countermeasure to address this issue is adversarial attacks, which deceive malicious FR searches but simultaneously interfere the normal identity verification of trusted authorizers. In this paper, we propose the first Double Privacy Guard (DPG) scheme based on traceable adversarial watermarking. DPG employs a one-time watermark embedding to deceive unauthorized FR models and allows authorizers to perform identity verification by extracting the watermark. Specifically, we propose an information-guided adversarial attack against FR models. The encoder embeds an identity-specific watermark into the deep feature space of the carrier, guiding recognizable features of the image to deviate from the source identity. We further adopt a collaborative meta-optimization strategy compatible with sub-tasks, which regularizes the joint optimization direction of the encoder and decoder. This strategy enhances the representation of universal carrier features, mitigating multi-objective optimization conflicts in watermarking. Experiments confirm that DPG achieves significant attack success rates and traceability accuracy on state-of-the-art FR models, exhibiting remarkable robustness that outperforms the existing privacy protection methods using adversarial attacks and deep watermarking, or simple combinations of the two. Our work potentially opens up new insights into proactive protection for FR privacy.
AVT2-DWF: Improving Deepfake Detection with Audio-Visual Fusion and Dynamic Weighting Strategies
Mar 22, 2024With the continuous improvements of deepfake methods, forgery messages have transitioned from single-modality to multi-modal fusion, posing new challenges for existing forgery detection algorithms. In this paper, we propose AVT2-DWF, the Audio-Visual dual Transformers grounded in Dynamic Weight Fusion, which aims to amplify both intra- and cross-modal forgery cues, thereby enhancing detection capabilities. AVT2-DWF adopts a dual-stage approach to capture both spatial characteristics and temporal dynamics of facial expressions. This is achieved through a face transformer with an n-frame-wise tokenization strategy encoder and an audio transformer encoder. Subsequently, it uses multi-modal conversion with dynamic weight fusion to address the challenge of heterogeneous information fusion between audio and visual modalities. Experiments on DeepfakeTIMIT, FakeAVCeleb, and DFDC datasets indicate that AVT2-DWF achieves state-of-the-art performance intra- and cross-dataset Deepfake detection. Code is available at https://github.com/raining-dev/AVT2-DWF.
Dual Defense: Adversarial, Traceable, and Invisible Robust Watermarking against Face Swapping
Oct 25, 2023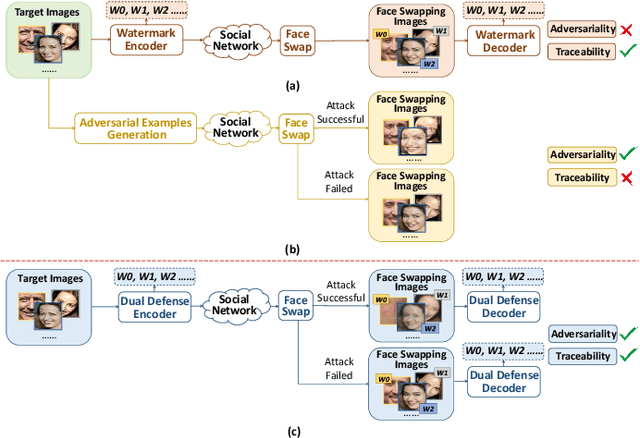

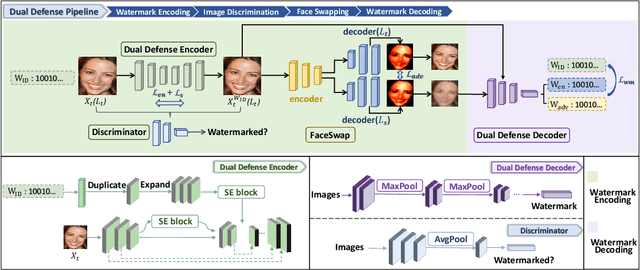
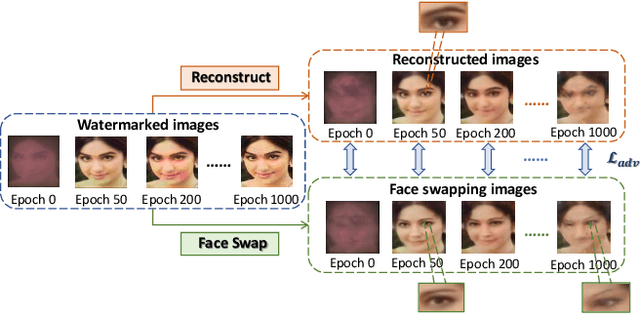
The malicious applications of deep forgery, represented by face swapping, have introduced security threats such as misinformation dissemination and identity fraud. While some research has proposed the use of robust watermarking methods to trace the copyright of facial images for post-event traceability, these methods cannot effectively prevent the generation of forgeries at the source and curb their dissemination. To address this problem, we propose a novel comprehensive active defense mechanism that combines traceability and adversariality, called Dual Defense. Dual Defense invisibly embeds a single robust watermark within the target face to actively respond to sudden cases of malicious face swapping. It disrupts the output of the face swapping model while maintaining the integrity of watermark information throughout the entire dissemination process. This allows for watermark extraction at any stage of image tracking for traceability. Specifically, we introduce a watermark embedding network based on original-domain feature impersonation attack. This network learns robust adversarial features of target facial images and embeds watermarks, seeking a well-balanced trade-off between watermark invisibility, adversariality, and traceability through perceptual adversarial encoding strategies. Extensive experiments demonstrate that Dual Defense achieves optimal overall defense success rates and exhibits promising universality in anti-face swapping tasks and dataset generalization ability. It maintains impressive adversariality and traceability in both original and robust settings, surpassing current forgery defense methods that possess only one of these capabilities, including CMUA-Watermark, Anti-Forgery, FakeTagger, or PGD methods.
Universal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023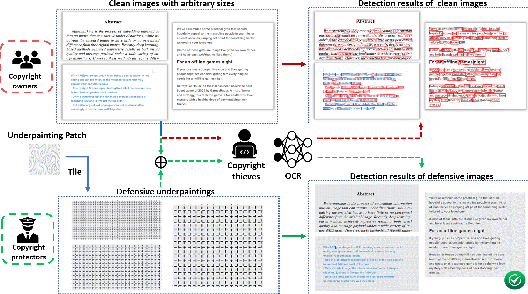

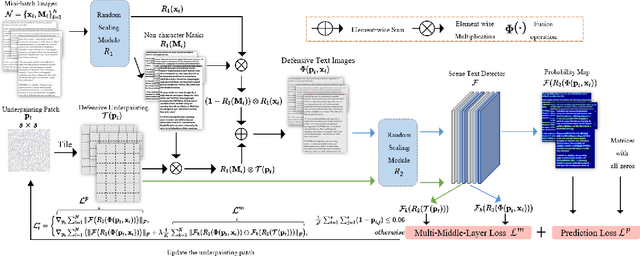
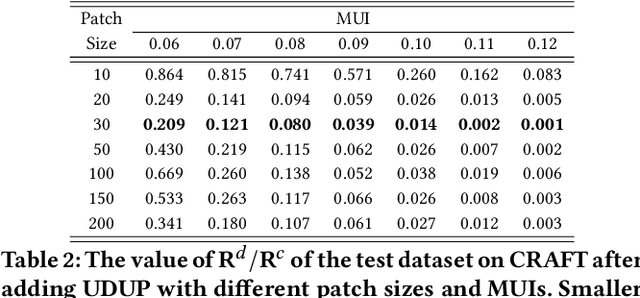
Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency
Mar 27, 2023
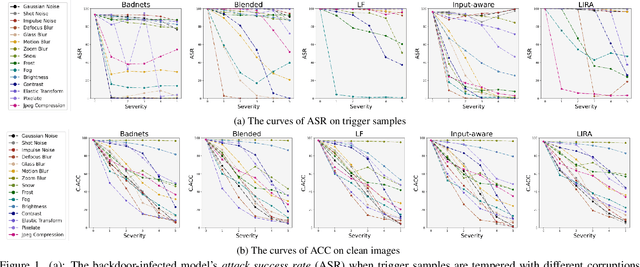
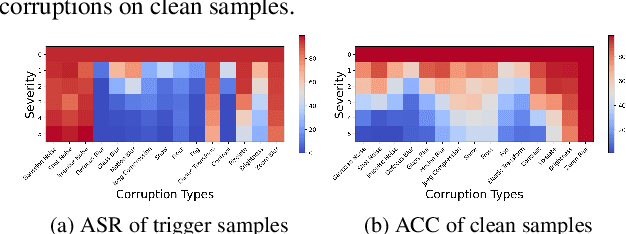
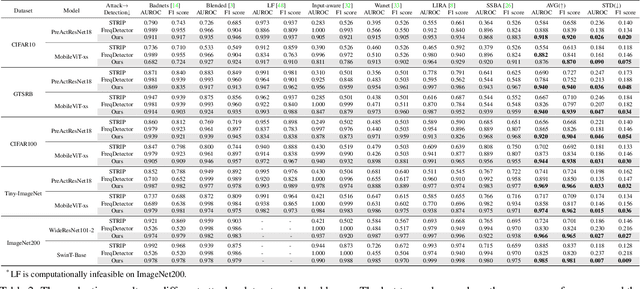
Deep neural networks are proven to be vulnerable to backdoor attacks. Detecting the trigger samples during the inference stage, i.e., the test-time trigger sample detection, can prevent the backdoor from being triggered. However, existing detection methods often require the defenders to have high accessibility to victim models, extra clean data, or knowledge about the appearance of backdoor triggers, limiting their practicality. In this paper, we propose the test-time corruption robustness consistency evaluation (TeCo), a novel test-time trigger sample detection method that only needs the hard-label outputs of the victim models without any extra information. Our journey begins with the intriguing observation that the backdoor-infected models have similar performance across different image corruptions for the clean images, but perform discrepantly for the trigger samples. Based on this phenomenon, we design TeCo to evaluate test-time robustness consistency by calculating the deviation of severity that leads to predictions' transition across different corruptions. Extensive experiments demonstrate that compared with state-of-the-art defenses, which even require either certain information about the trigger types or accessibility of clean data, TeCo outperforms them on different backdoor attacks, datasets, and model architectures, enjoying a higher AUROC by 10% and 5 times of stability.
Feature Extraction Matters More: Universal Deepfake Disruption through Attacking Ensemble Feature Extractors
Mar 01, 2023
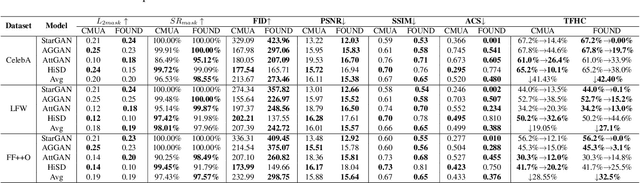
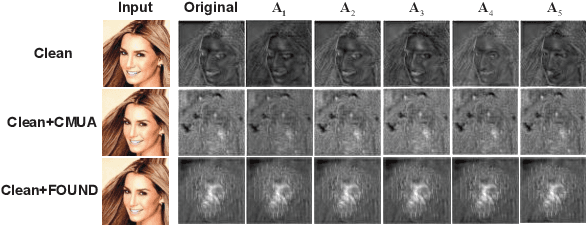

Adversarial example is a rising way of protecting facial privacy security from deepfake modification. To prevent massive facial images from being illegally modified by various deepfake models, it is essential to design a universal deepfake disruptor. However, existing works treat deepfake disruption as an End-to-End process, ignoring the functional difference between feature extraction and image reconstruction, which makes it difficult to generate a cross-model universal disruptor. In this work, we propose a novel Feature-Output ensemble UNiversal Disruptor (FOUND) against deepfake networks, which explores a new opinion that considers attacking feature extractors as the more critical and general task in deepfake disruption. We conduct an effective two-stage disruption process. We first disrupt multi-model feature extractors through multi-feature aggregation and individual-feature maintenance, and then develop a gradient-ensemble algorithm to enhance the disruption effect by simplifying the complex optimization problem of disrupting multiple End-to-End models. Extensive experiments demonstrate that FOUND can significantly boost the disruption effect against ensemble deepfake benchmark models. Besides, our method can fast obtain a cross-attribute, cross-image, and cross-model universal deepfake disruptor with only a few training images, surpassing state-of-the-art universal disruptors in both success rate and efficiency.
Detection Defense Against Adversarial Attacks with Saliency Map
Sep 06, 2020



It is well established that neural networks are vulnerable to adversarial examples, which are almost imperceptible on human vision and can cause the deep models misbehave. Such phenomenon may lead to severely inestimable consequences in the safety and security critical applications. Existing defenses are trend to harden the robustness of models against adversarial attacks, e.g., adversarial training technology. However, these are usually intractable to implement due to the high cost of re-training and the cumbersome operations of altering the model architecture or parameters. In this paper, we discuss the saliency map method from the view of enhancing model interpretability, it is similar to introducing the mechanism of the attention to the model, so as to comprehend the progress of object identification by the deep networks. We then propose a novel method combined with additional noises and utilize the inconsistency strategy to detect adversarial examples. Our experimental results of some representative adversarial attacks on common datasets including ImageNet and popular models show that our method can detect all the attacks with high detection success rate effectively. We compare it with the existing state-of-the-art technique, and the experiments indicate that our method is more general.