 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDhruv Choudhary
Microscaling Data Formats for Deep Learning
Oct 19, 2023
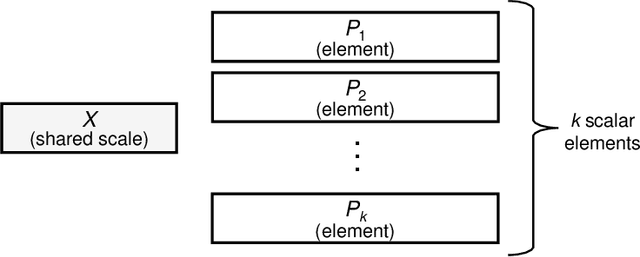
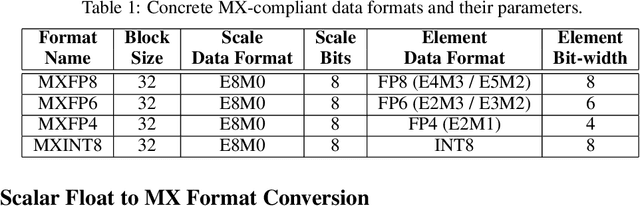
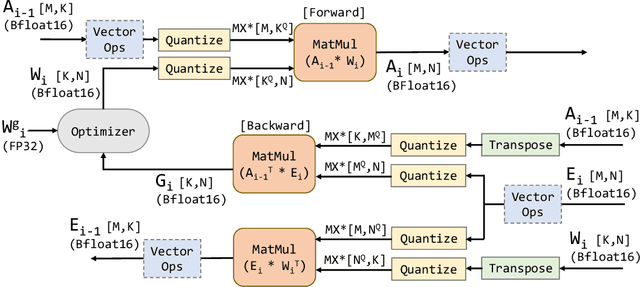
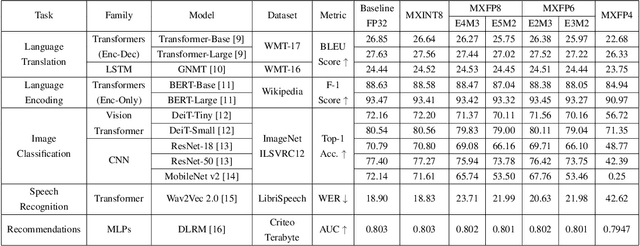
Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
FlexShard: Flexible Sharding for Industry-Scale Sequence Recommendation Models
Jan 08, 2023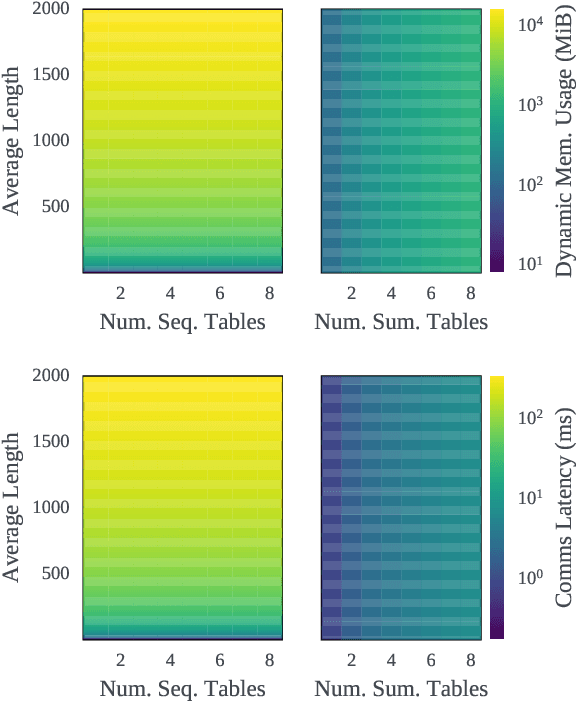

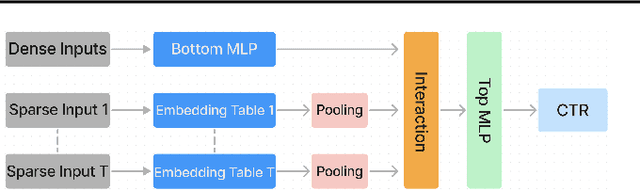
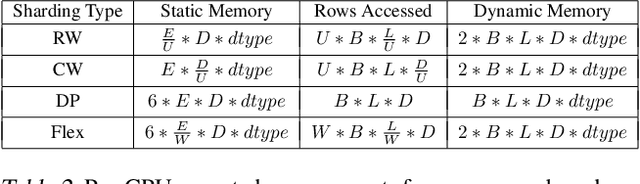
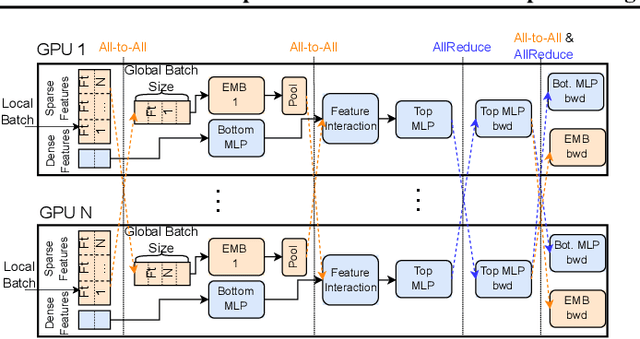
Sequence-based deep learning recommendation models (DLRMs) are an emerging class of DLRMs showing great improvements over their prior sum-pooling based counterparts at capturing users' long term interests. These improvements come at immense system cost however, with sequence-based DLRMs requiring substantial amounts of data to be dynamically materialized and communicated by each accelerator during a single iteration. To address this rapidly growing bottleneck, we present FlexShard, a new tiered sequence embedding table sharding algorithm which operates at a per-row granularity by exploiting the insight that not every row is equal. Through precise replication of embedding rows based on their underlying probability distribution, along with the introduction of a new sharding strategy adapted to the heterogeneous, skewed performance of real-world cluster network topologies, FlexShard is able to significantly reduce communication demand while using no additional memory compared to the prior state-of-the-art. When evaluated on production-scale sequence DLRMs, FlexShard was able to reduce overall global all-to-all communication traffic by over 85%, resulting in end-to-end training communication latency improvements of almost 6x over the prior state-of-the-art approach.
RecD: Deduplication for End-to-End Deep Learning Recommendation Model Training Infrastructure
Nov 14, 2022

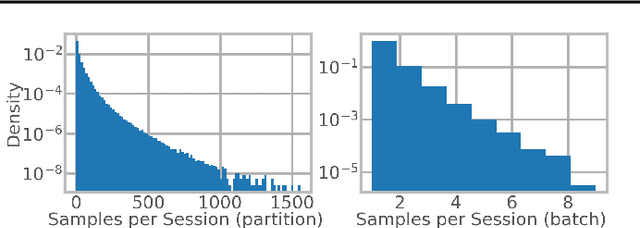
We present RecD (Recommendation Deduplication), a suite of end-to-end infrastructure optimizations across the Deep Learning Recommendation Model (DLRM) training pipeline. RecD addresses immense storage, preprocessing, and training overheads caused by feature duplication inherent in industry-scale DLRM training datasets. Feature duplication arises because DLRM datasets are generated from interactions. While each user session can generate multiple training samples, many features' values do not change across these samples. We demonstrate how RecD exploits this property, end-to-end, across a deployed training pipeline. RecD optimizes data generation pipelines to decrease dataset storage and preprocessing resource demands and to maximize duplication within a training batch. RecD introduces a new tensor format, InverseKeyedJaggedTensors (IKJTs), to deduplicate feature values in each batch. We show how DLRM model architectures can leverage IKJTs to drastically increase training throughput. RecD improves the training and preprocessing throughput and storage efficiency by up to 2.49x, 1.79x, and 3.71x, respectively, in an industry-scale DLRM training system.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022
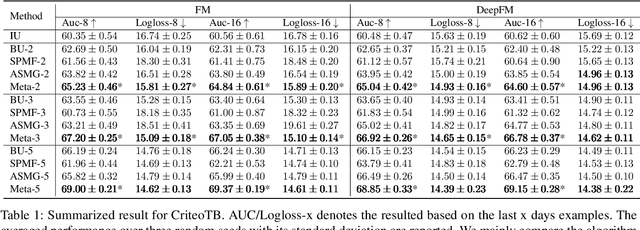
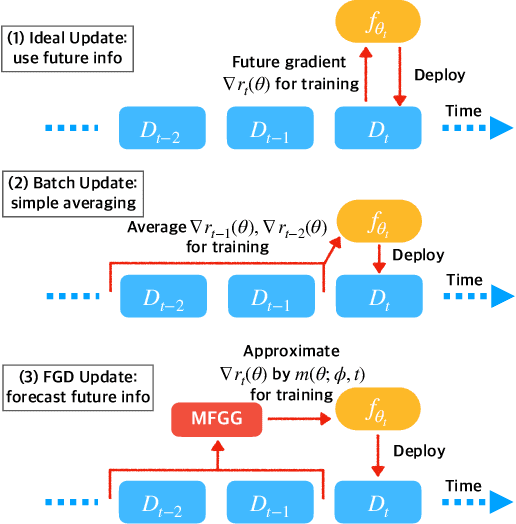
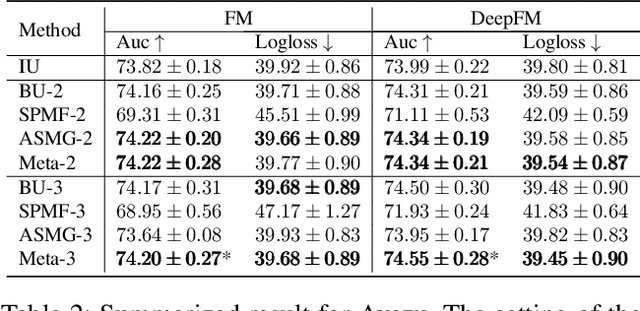
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
AutoShard: Automated Embedding Table Sharding for Recommender Systems
Aug 12, 2022



Embedding learning is an important technique in deep recommendation models to map categorical features to dense vectors. However, the embedding tables often demand an extremely large number of parameters, which become the storage and efficiency bottlenecks. Distributed training solutions have been adopted to partition the embedding tables into multiple devices. However, the embedding tables can easily lead to imbalances if not carefully partitioned. This is a significant design challenge of distributed systems named embedding table sharding, i.e., how we should partition the embedding tables to balance the costs across devices, which is a non-trivial task because 1) it is hard to efficiently and precisely measure the cost, and 2) the partition problem is known to be NP-hard. In this work, we introduce our novel practice in Meta, namely AutoShard, which uses a neural cost model to directly predict the multi-table costs and leverages deep reinforcement learning to solve the partition problem. Experimental results on an open-sourced large-scale synthetic dataset and Meta's production dataset demonstrate the superiority of AutoShard over the heuristics. Moreover, the learned policy of AutoShard can transfer to sharding tasks with various numbers of tables and different ratios of the unseen tables without any fine-tuning. Furthermore, AutoShard can efficiently shard hundreds of tables in seconds. The effectiveness, transferability, and efficiency of AutoShard make it desirable for production use. Our algorithms have been deployed in Meta production environment. A prototype is available at https://github.com/daochenzha/autoshard
Positive Unlabeled Contrastive Learning
Jun 01, 2022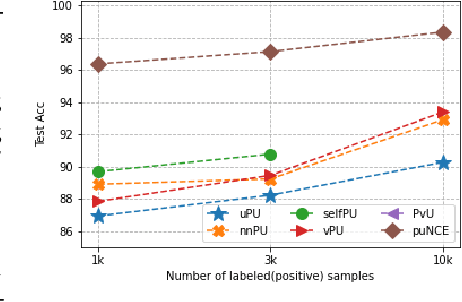

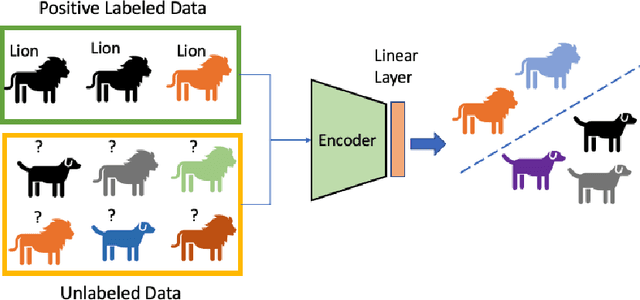
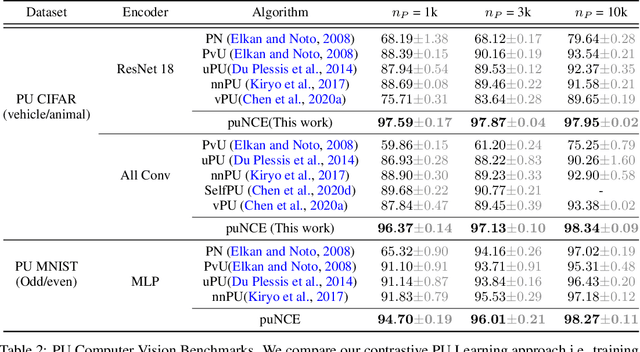
Self-supervised pretraining on unlabeled data followed by supervised finetuning on labeled data is a popular paradigm for learning from limited labeled examples. In this paper, we investigate and extend this paradigm to the classical positive unlabeled (PU) setting - the weakly supervised task of learning a binary classifier only using a few labeled positive examples and a set of unlabeled samples. We propose a novel PU learning objective positive unlabeled Noise Contrastive Estimation (puNCE) that leverages the available explicit (from labeled samples) and implicit (from unlabeled samples) supervision to learn useful representations from positive unlabeled input data. The underlying idea is to assign each training sample an individual weight; labeled positives are given unit weight; unlabeled samples are duplicated, one copy is labeled positive and the other as negative with weights $\pi$ and $(1-\pi)$ where $\pi$ denotes the class prior. Extensive experiments across vision and natural language tasks reveal that puNCE consistently improves over existing unsupervised and supervised contrastive baselines under limited supervision.
Frequency-aware SGD for Efficient Embedding Learning with Provable Benefits
Oct 24, 2021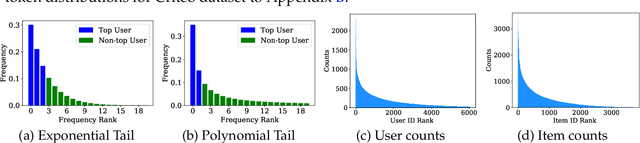
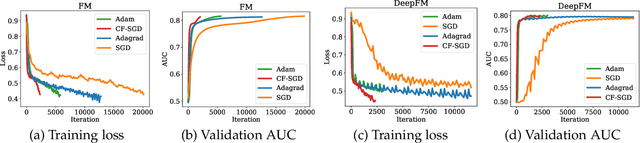

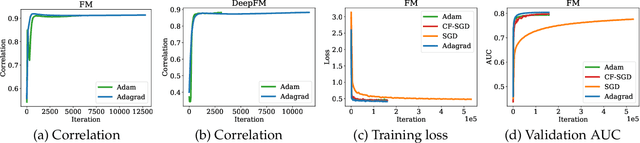
Embedding learning has found widespread applications in recommendation systems and natural language modeling, among other domains. To learn quality embeddings efficiently, adaptive learning rate algorithms have demonstrated superior empirical performance over SGD, largely accredited to their token-dependent learning rate. However, the underlying mechanism for the efficiency of token-dependent learning rate remains underexplored. We show that incorporating frequency information of tokens in the embedding learning problems leads to provably efficient algorithms, and demonstrate that common adaptive algorithms implicitly exploit the frequency information to a large extent. Specifically, we propose (Counter-based) Frequency-aware Stochastic Gradient Descent, which applies a frequency-dependent learning rate for each token, and exhibits provable speed-up compared to SGD when the token distribution is imbalanced. Empirically, we show the proposed algorithms are able to improve or match adaptive algorithms on benchmark recommendation tasks and a large-scale industrial recommendation system, closing the performance gap between SGD and adaptive algorithms. Our results are the first to show token-dependent learning rate provably improves convergence for non-convex embedding learning problems.
Low-Precision Hardware Architectures Meet Recommendation Model Inference at Scale
May 26, 2021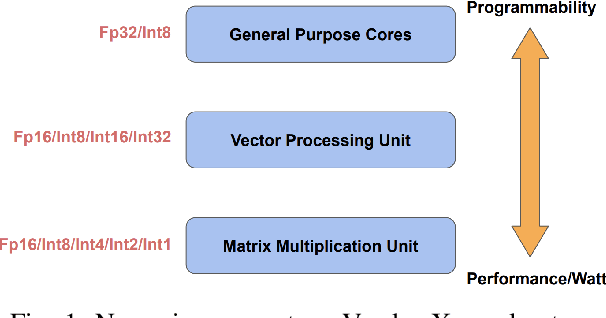
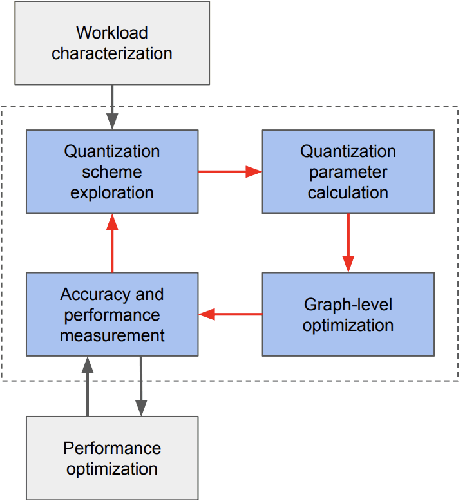
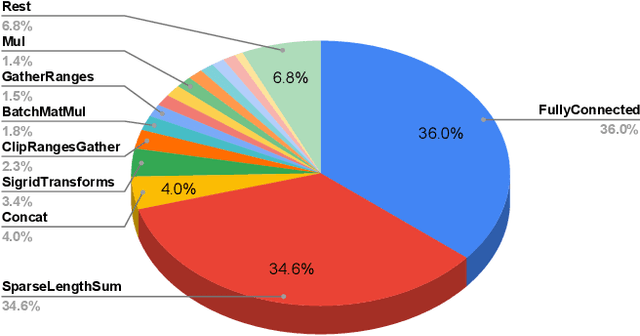
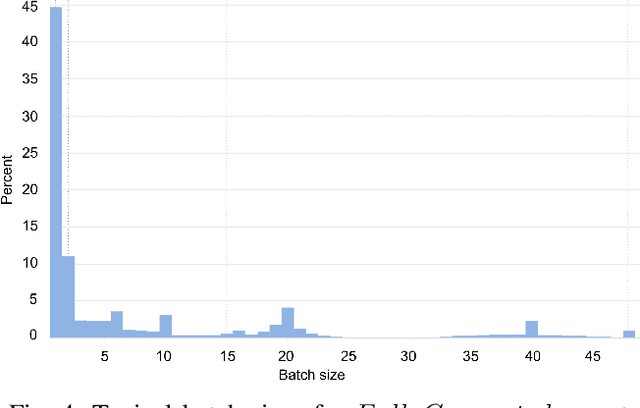
Tremendous success of machine learning (ML) and the unabated growth in ML model complexity motivated many ML-specific designs in both CPU and accelerator architectures to speed up the model inference. While these architectures are diverse, highly optimized low-precision arithmetic is a component shared by most. Impressive compute throughputs are indeed often exhibited by these architectures on benchmark ML models. Nevertheless, production models such as recommendation systems important to Facebook's personalization services are demanding and complex: These systems must serve billions of users per month responsively with low latency while maintaining high prediction accuracy, notwithstanding computations with many tens of billions parameters per inference. Do these low-precision architectures work well with our production recommendation systems? They do. But not without significant effort. We share in this paper our search strategies to adapt reference recommendation models to low-precision hardware, our optimization of low-precision compute kernels, and the design and development of tool chain so as to maintain our models' accuracy throughout their lifespan during which topic trends and users' interests inevitably evolve. Practicing these low-precision technologies helped us save datacenter capacities while deploying models with up to 5X complexity that would otherwise not be deployed on traditional general-purpose CPUs. We believe these lessons from the trenches promote better co-design between hardware architecture and software engineering and advance the state of the art of ML in industry.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021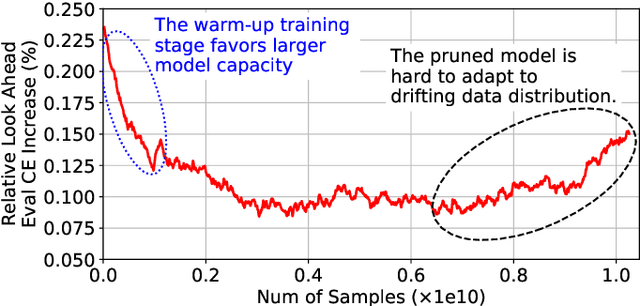
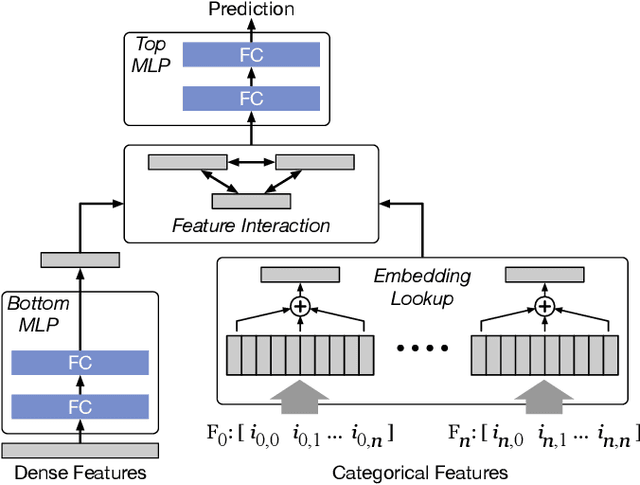
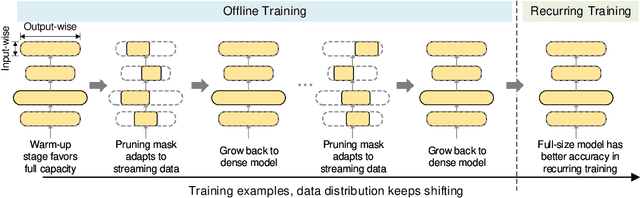
Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Adaptive Dense-to-Sparse Paradigm for Pruning Online Recommendation System with Non-Stationary Data
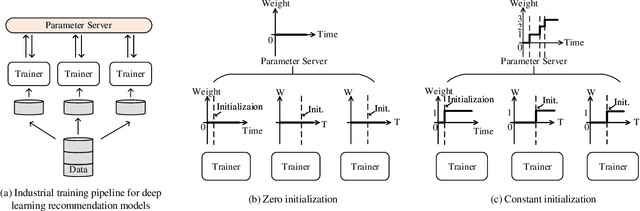
Oct 21, 2020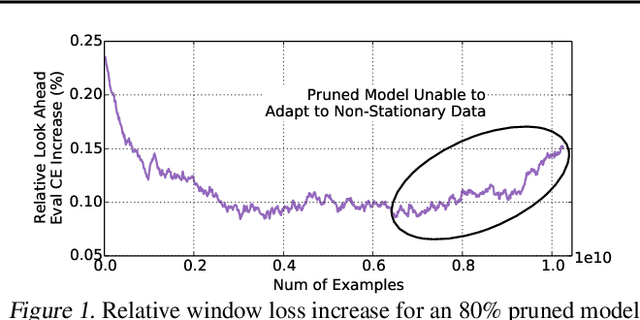
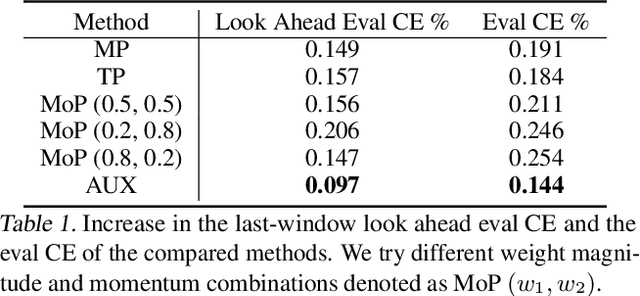
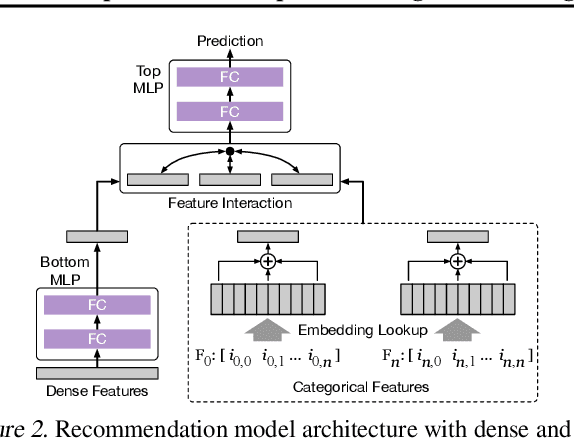
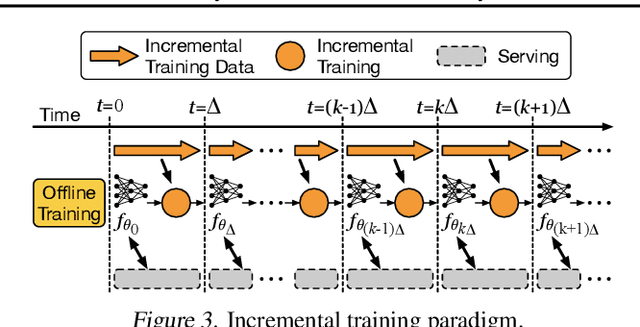
Large scale deep learning provides a tremendous opportunity to improve the quality of content recommendation systems by employing both wider and deeper models, but this comes at great infrastructural cost and carbon footprint in modern data centers. Pruning is an effective technique that reduces both memory and compute demand for model inference. However, pruning for online recommendation systems is challenging due to the continuous data distribution shift (a.k.a non-stationary data). Although incremental training on the full model is able to adapt to the non-stationary data, directly applying it on the pruned model leads to accuracy loss. This is because the sparsity pattern after pruning requires adjustment to learn new patterns. To the best of our knowledge, this is the first work to provide in-depth analysis and discussion of applying pruning to online recommendation systems with non-stationary data distribution. Overall, this work makes the following contributions: 1) We present an adaptive dense to sparse paradigm equipped with a novel pruning algorithm for pruning a large scale recommendation system with non-stationary data distribution; 2) We design the pruning algorithm to automatically learn the sparsity across layers to avoid repeating hand-tuning, which is critical for pruning the heterogeneous architectures of recommendation systems trained with non-stationary data.