 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaocong Du
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022
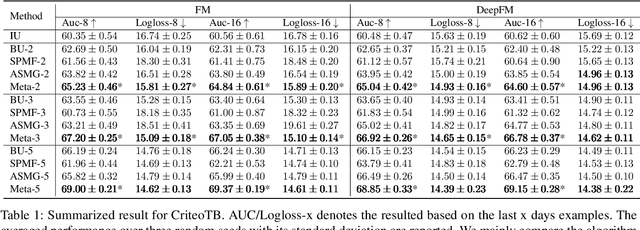
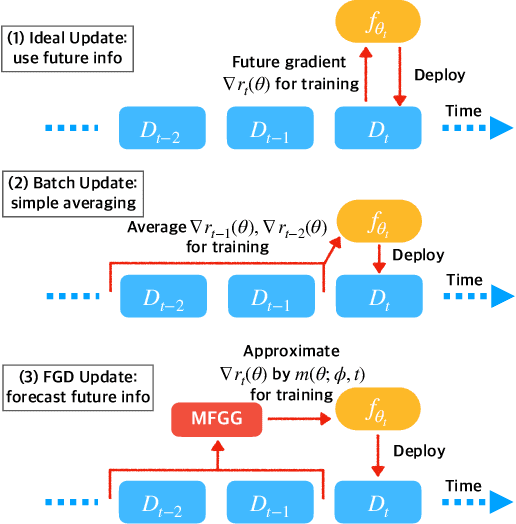
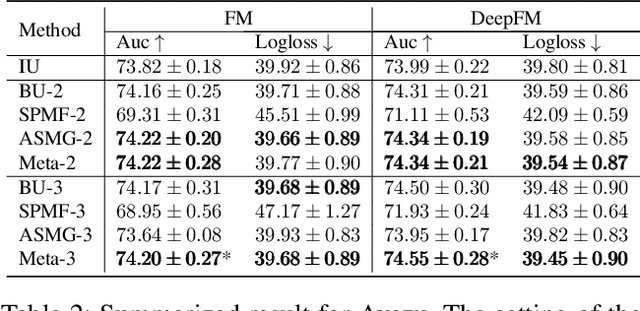
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
Alternate Model Growth and Pruning for Efficient Training of Recommendation Systems
May 04, 2021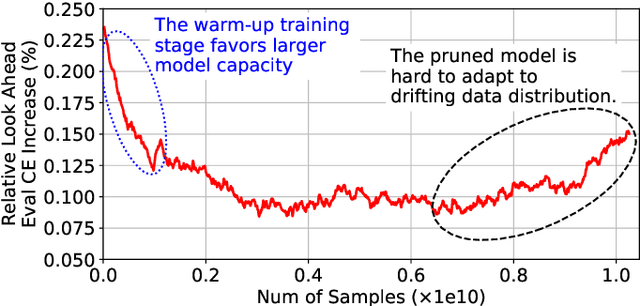
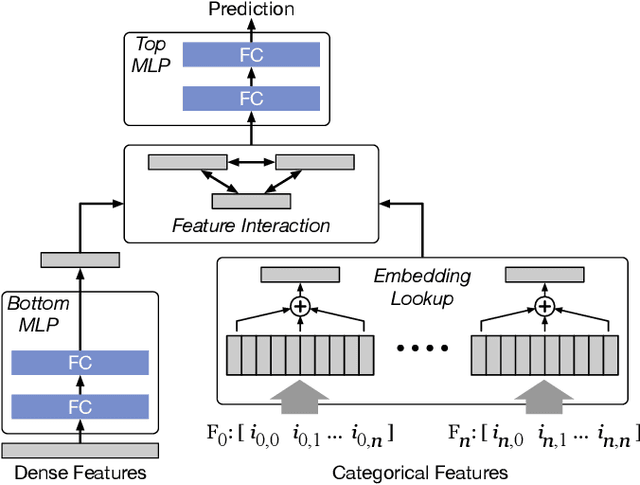
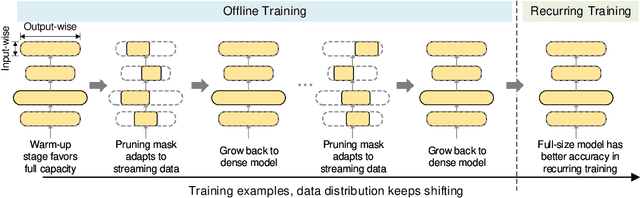
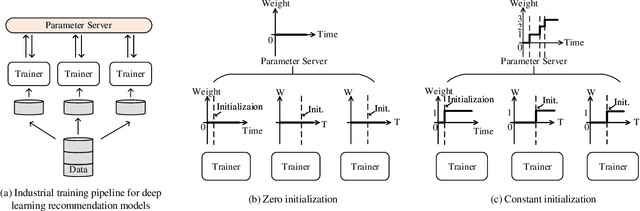
Deep learning recommendation systems at scale have provided remarkable gains through increasing model capacity (i.e. wider and deeper neural networks), but it comes at significant training cost and infrastructure cost. Model pruning is an effective technique to reduce computation overhead for deep neural networks by removing redundant parameters. However, modern recommendation systems are still thirsty for model capacity due to the demand for handling big data. Thus, pruning a recommendation model at scale results in a smaller model capacity and consequently lower accuracy. To reduce computation cost without sacrificing model capacity, we propose a dynamic training scheme, namely alternate model growth and pruning, to alternatively construct and prune weights in the course of training. Our method leverages structured sparsification to reduce computational cost without hurting the model capacity at the end of offline training so that a full-size model is available in the recurring training stage to learn new data in real-time. To the best of our knowledge, this is the first work to provide in-depth experiments and discussion of applying structural dynamics to recommendation systems at scale to reduce training cost. The proposed method is validated with an open-source deep-learning recommendation model (DLRM) and state-of-the-art industrial-scale production models.
Structural Pruning in Deep Neural Networks: A Small-World Approach
Nov 11, 2019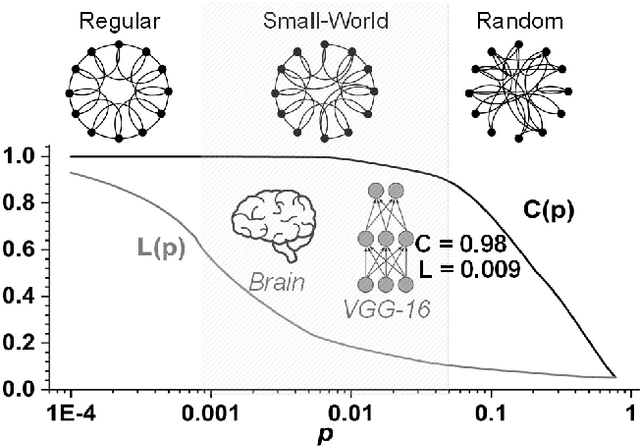
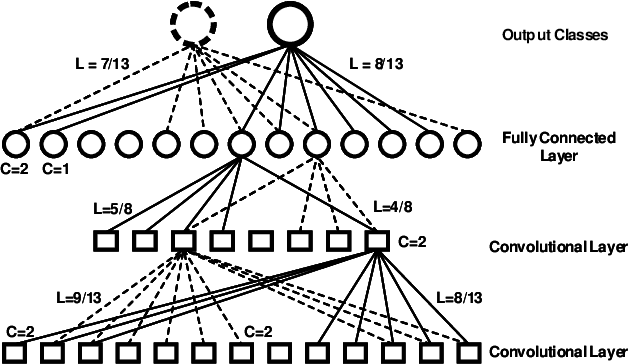
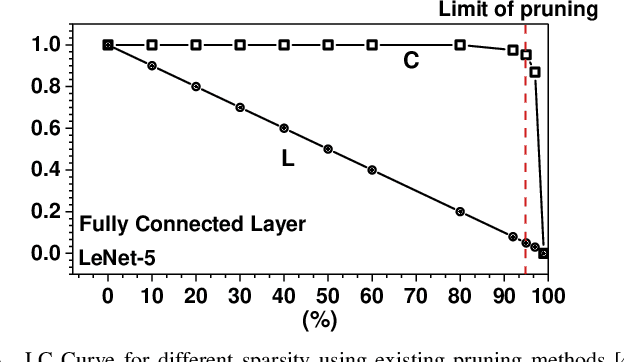
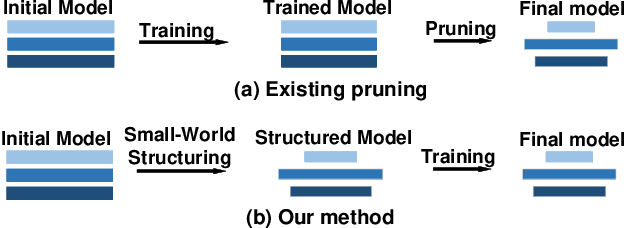
Deep Neural Networks (DNNs) are usually over-parameterized, causing excessive memory and interconnection cost on the hardware platform. Existing pruning approaches remove secondary parameters at the end of training to reduce the model size; but without exploiting the intrinsic network property, they still require the full interconnection to prepare the network. Inspired by the observation that brain networks follow the Small-World model, we propose a novel structural pruning scheme, which includes (1) hierarchically trimming the network into a Small-World model before training, (2) training the network for a given dataset, and (3) optimizing the network for accuracy. The new scheme effectively reduces both the model size and the interconnection needed before training, achieving a locally clustered and globally sparse model. We demonstrate our approach on LeNet-5 for MNIST and VGG-16 for CIFAR-10, decreasing the number of parameters to 2.3% and 9.02% of the baseline model, respectively.
Single-Net Continual Learning with Progressive Segmented Training (PST)
Jun 02, 2019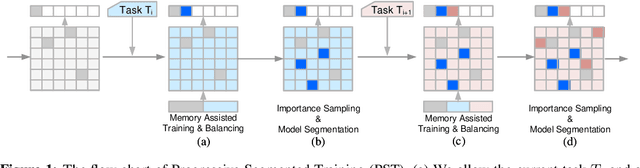

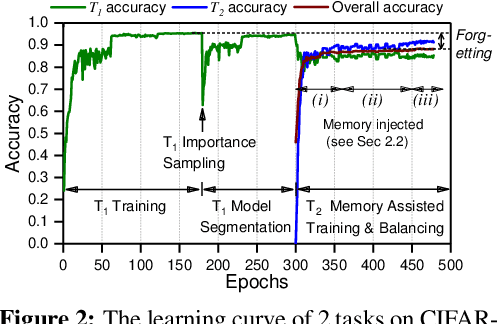
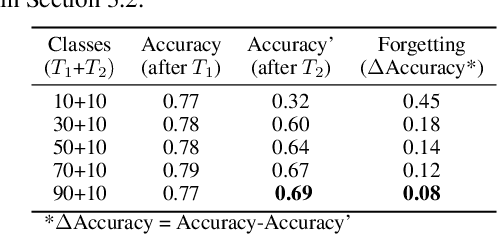
There is an increasing need of continual learning in dynamic systems, such as the self-driving vehicle, the surveillance drone, and the robotic system. Such a system requires learning from the data stream, training the model to preserve previous information and adapt to a new task, and generating a single-headed vector for future inference. Different from previous approaches with dynamic structures, this work focuses on a single network and model segmentation to prevent catastrophic forgetting. Leveraging the redundant capacity of a single network, model parameters for each task are separated into two groups: one important group which is frozen to preserve current knowledge, and secondary group to be saved (not pruned) for a future learning. A fixed-size memory containing a small amount of previously seen data is further adopted to assist the training. Without additional regularization, the simple yet effective approach of PST successfully incorporates multiple tasks and achieves the state-of-the-art accuracy in the single-head evaluation on CIFAR-10 and CIFAR-100 datasets. Moreover, the segmented training significantly improves computation efficiency in continual learning.
CGaP: Continuous Growth and Pruning for Efficient Deep Learning
May 29, 2019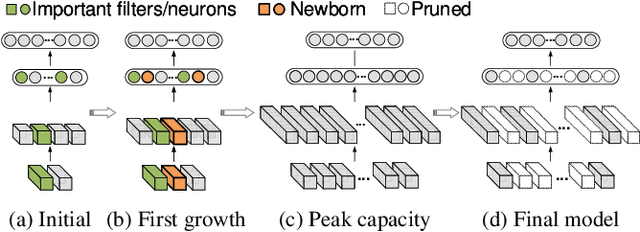
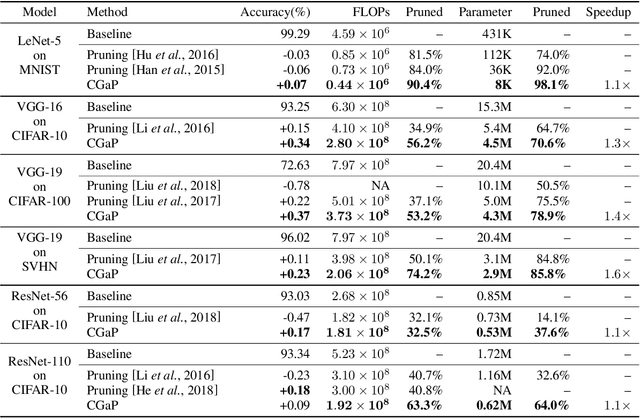
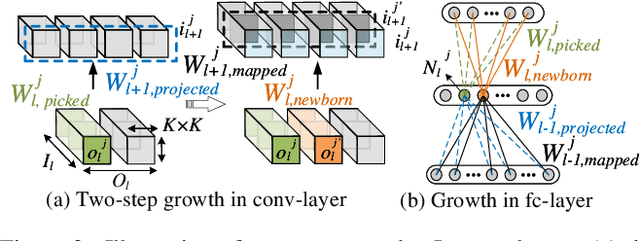
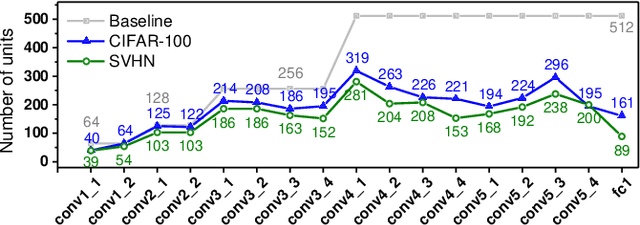
Today a canonical approach to reduce the computation cost of Deep Neural Networks (DNNs) is to pre-define an over-parameterized model before training to guarantee the learning capacity, and then prune unimportant learning units (filters and neurons) during training to improve model compactness. We argue it is unnecessary to introduce redundancy at the beginning of the training but then reduce redundancy for the ultimate inference model. In this paper, we propose a Continuous Growth and Pruning (CGaP) scheme to minimize the redundancy from the beginning. CGaP starts the training from a small network seed, then expands the model continuously by reinforcing important learning units, and finally prunes the network to obtain a compact and accurate model. As the growth phase favors important learning units, CGaP provides a clear learning purpose to the pruning phase. Experimental results on representative datasets and DNN architectures demonstrate that CGaP outperforms previous pruning-only approaches that deal with pre-defined structures. For VGG-19 on CIFAR-100 and SVHN datasets, CGaP reduces the number of parameters by 78.9% and 85.8%, FLOPs by 53.2% and 74.2%, respectively; For ResNet-110 On CIFAR-10, CGaP reduces 64.0% number of parameters and 63.3% FLOPs.
Efficient Network Construction through Structural Plasticity
May 27, 2019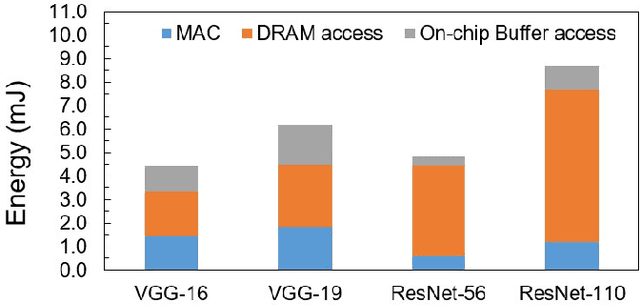
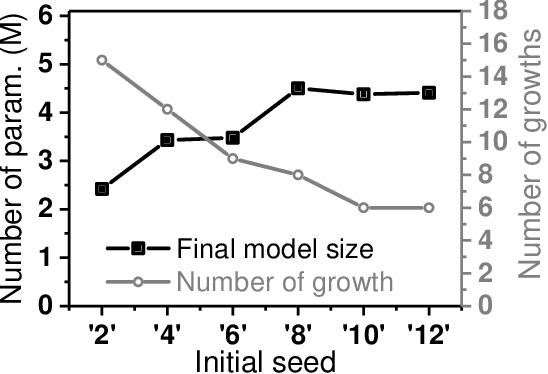


Deep Neural Networks (DNNs) on hardware is facing excessive computation cost due to the massive number of parameters. A typical training pipeline to mitigate over-parameterization is to pre-define a DNN structure first with redundant learning units (filters and neurons) under the goal of high accuracy, then to prune redundant learning units after training with the purpose of efficient inference. We argue that it is sub-optimal to introduce redundancy into training for the purpose of reducing redundancy later in inference. Moreover, the fixed network structure further results in poor adaption to dynamic tasks, such as lifelong learning. In contrast, structural plasticity plays an indispensable role in mammalian brains to achieve compact and accurate learning. Throughout the lifetime, active connections are continuously created while those no longer important are degenerated. Inspired by such observation, we propose a training scheme, namely Continuous Growth and Pruning (CGaP), where we start the training from a small network seed, then literally execute continuous growth by adding important learning units and finally prune secondary ones for efficient inference. The inference model generated from CGaP is sparse in the structure, largely decreasing the inference power and latency when deployed on hardware platforms. With popular DNN structures on representative datasets, the efficacy of CGaP is benchmarked by both algorithm simulation and architectural modeling on Field-programmable Gate Arrays (FPGA). For example, CGaP decreases the FLOPs, model size, DRAM access energy and inference latency by 63.3%, 64.0%, 11.8% and 40.2%, respectively, for ResNet-110 on CIFAR-10.