 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuichen Jiang
An Accelerated Gradient Method for Simple Bilevel Optimization with Convex Lower-level Problem
Feb 12, 2024
In this paper, we focus on simple bilevel optimization problems, where we minimize a convex smooth objective function over the optimal solution set of another convex smooth constrained optimization problem. We present a novel bilevel optimization method that locally approximates the solution set of the lower-level problem using a cutting plane approach and employs an accelerated gradient-based update to reduce the upper-level objective function over the approximated solution set. We measure the performance of our method in terms of suboptimality and infeasibility errors and provide non-asymptotic convergence guarantees for both error criteria. Specifically, when the feasible set is compact, we show that our method requires at most $\mathcal{O}(\max\{1/\sqrt{\epsilon_{f}}, 1/\epsilon_g\})$ iterations to find a solution that is $\epsilon_f$-suboptimal and $\epsilon_g$-infeasible. Moreover, under the additional assumption that the lower-level objective satisfies the $r$-th H\"olderian error bound, we show that our method achieves an iteration complexity of $\mathcal{O}(\max\{\epsilon_{f}^{-\frac{2r-1}{2r}},\epsilon_{g}^{-\frac{2r-1}{2r}}\})$, which matches the optimal complexity of single-level convex constrained optimization when $r=1$.
Krylov Cubic Regularized Newton: A Subspace Second-Order Method with Dimension-Free Convergence Rate
Jan 05, 2024Second-order optimization methods, such as cubic regularized Newton methods, are known for their rapid convergence rates; nevertheless, they become impractical in high-dimensional problems due to their substantial memory requirements and computational costs. One promising approach is to execute second-order updates within a lower-dimensional subspace, giving rise to subspace second-order methods. However, the majority of existing subspace second-order methods randomly select subspaces, consequently resulting in slower convergence rates depending on the problem's dimension $d$. In this paper, we introduce a novel subspace cubic regularized Newton method that achieves a dimension-independent global convergence rate of ${O}\left(\frac{1}{mk}+\frac{1}{k^2}\right)$ for solving convex optimization problems. Here, $m$ represents the subspace dimension, which can be significantly smaller than $d$. Instead of adopting a random subspace, our primary innovation involves performing the cubic regularized Newton update within the Krylov subspace associated with the Hessian and the gradient of the objective function. This result marks the first instance of a dimension-independent convergence rate for a subspace second-order method. Furthermore, when specific spectral conditions of the Hessian are met, our method recovers the convergence rate of a full-dimensional cubic regularized Newton method. Numerical experiments show our method converges faster than existing random subspace methods, especially for high-dimensional problems.
Projection-Free Methods for Stochastic Simple Bilevel Optimization with Convex Lower-level Problem
Aug 15, 2023In this paper, we study a class of stochastic bilevel optimization problems, also known as stochastic simple bilevel optimization, where we minimize a smooth stochastic objective function over the optimal solution set of another stochastic convex optimization problem. We introduce novel stochastic bilevel optimization methods that locally approximate the solution set of the lower-level problem via a stochastic cutting plane, and then run a conditional gradient update with variance reduction techniques to control the error induced by using stochastic gradients. For the case that the upper-level function is convex, our method requires $\tilde{\mathcal{O}}(\max\{1/\epsilon_f^{2},1/\epsilon_g^{2}\}) $ stochastic oracle queries to obtain a solution that is $\epsilon_f$-optimal for the upper-level and $\epsilon_g$-optimal for the lower-level. This guarantee improves the previous best-known complexity of $\mathcal{O}(\max\{1/\epsilon_f^{4},1/\epsilon_g^{4}\})$. Moreover, for the case that the upper-level function is non-convex, our method requires at most $\tilde{\mathcal{O}}(\max\{1/\epsilon_f^{3},1/\epsilon_g^{3}\}) $ stochastic oracle queries to find an $(\epsilon_f, \epsilon_g)$-stationary point. In the finite-sum setting, we show that the number of stochastic oracle calls required by our method are $\tilde{\mathcal{O}}(\sqrt{n}/\epsilon)$ and $\tilde{\mathcal{O}}(\sqrt{n}/\epsilon^{2})$ for the convex and non-convex settings, respectively, where $\epsilon=\min \{\epsilon_f,\epsilon_g\}$.
Accelerated Quasi-Newton Proximal Extragradient: Faster Rate for Smooth Convex Optimization
Jun 03, 2023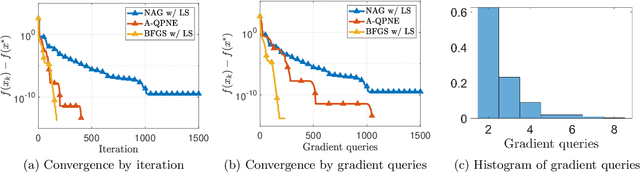
In this paper, we propose an accelerated quasi-Newton proximal extragradient (A-QPNE) method for solving unconstrained smooth convex optimization problems. With access only to the gradients of the objective, we prove that our method can achieve a convergence rate of ${O}\bigl(\min\{\frac{1}{k^2}, \frac{\sqrt{d\log k}}{k^{2.5}}\}\bigr)$, where $d$ is the problem dimension and $k$ is the number of iterations. In particular, in the regime where $k = {O}(d)$, our method matches the optimal rate of ${O}(\frac{1}{k^2})$ by Nesterov's accelerated gradient (NAG). Moreover, in the the regime where $k = \Omega(d \log d)$, it outperforms NAG and converges at a faster rate of ${O}\bigl(\frac{\sqrt{d\log k}}{k^{2.5}}\bigr)$. To the best of our knowledge, this result is the first to demonstrate a provable gain of a quasi-Newton-type method over NAG in the convex setting. To achieve such results, we build our method on a recent variant of the Monteiro-Svaiter acceleration framework and adopt an online learning perspective to update the Hessian approximation matrices, in which we relate the convergence rate of our method to the dynamic regret of a specific online convex optimization problem in the space of matrices.
Online Learning Guided Curvature Approximation: A Quasi-Newton Method with Global Non-Asymptotic Superlinear Convergence
Feb 16, 2023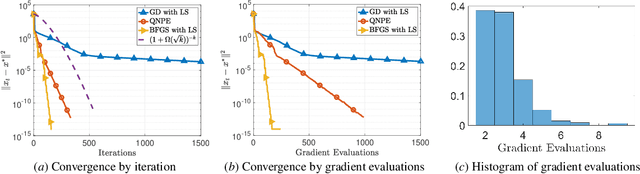
Quasi-Newton algorithms are among the most popular iterative methods for solving unconstrained minimization problems, largely due to their favorable superlinear convergence property. However, existing results for these algorithms are limited as they provide either (i) a global convergence guarantee with an asymptotic superlinear convergence rate, or (ii) a local non-asymptotic superlinear rate for the case that the initial point and the initial Hessian approximation are chosen properly. Furthermore, these results are not composable, since when the iterates of the globally convergent methods reach the region of local superlinear convergence, it cannot be guaranteed the Hessian approximation matrix will satisfy the required conditions for a non-asymptotic local superlienar convergence rate. In this paper, we close this gap and present the first globally convergent quasi-Newton method with an explicit non-asymptotic superlinear convergence rate. Unlike classical quasi-Newton methods, we build our algorithm upon the hybrid proximal extragradient method and propose a novel online learning framework for updating the Hessian approximation matrices. Specifically, guided by the convergence analysis, we formulate the Hessian approximation update as an online convex optimization problem in the space of matrices, and relate the bounded regret of the online problem to the superlinear convergence of our method.
Future Gradient Descent for Adapting the Temporal Shifting Data Distribution in Online Recommendation Systems
Sep 02, 2022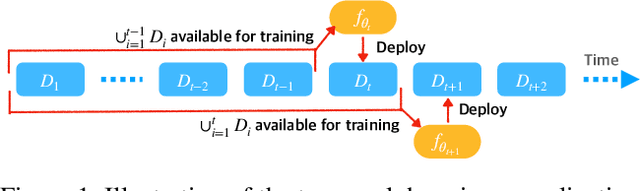
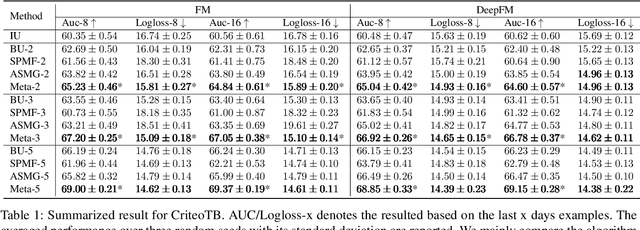
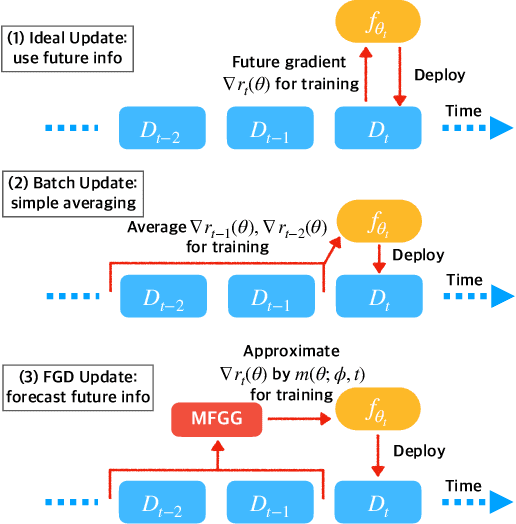
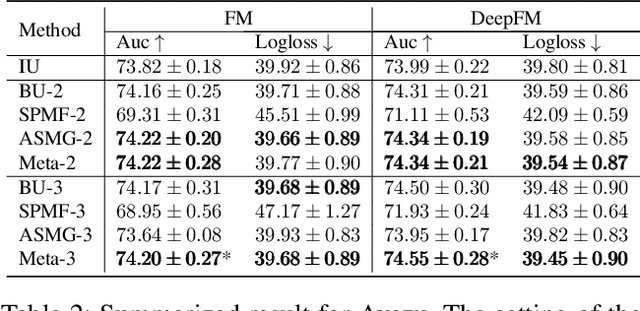
One of the key challenges of learning an online recommendation model is the temporal domain shift, which causes the mismatch between the training and testing data distribution and hence domain generalization error. To overcome, we propose to learn a meta future gradient generator that forecasts the gradient information of the future data distribution for training so that the recommendation model can be trained as if we were able to look ahead at the future of its deployment. Compared with Batch Update, a widely used paradigm, our theory suggests that the proposed algorithm achieves smaller temporal domain generalization error measured by a gradient variation term in a local regret. We demonstrate the empirical advantage by comparing with various representative baselines.
Generalized Frank-Wolfe Algorithm for Bilevel Optimization
Jun 17, 2022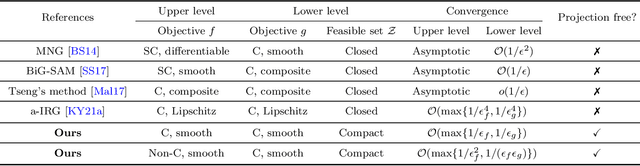
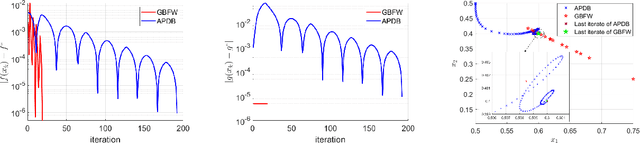

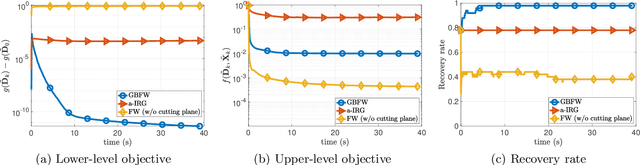
In this paper, we study a class of bilevel optimization problems, also known as simple bilevel optimization, where we minimize a smooth objective function over the optimal solution set of another convex constrained optimization problem. Several iterative methods have been developed for tackling this class of problems. Alas, their convergence guarantees are not satisfactory as they are either asymptotic for the upper-level objective, or the convergence rates are slow and sub-optimal. To address this issue, in this paper, we introduce a generalization of the Frank-Wolfe (FW) method to solve the considered problem. The main idea of our method is to locally approximate the solution set of the lower-level problem via a cutting plane, and then run a FW-type update to decrease the upper-level objective. When the upper-level objective is convex, we show that our method requires ${\mathcal{O}}(\max\{1/\epsilon_f,1/\epsilon_g\})$ iterations to find a solution that is $\epsilon_f$-optimal for the upper-level objective and $\epsilon_g$-optimal for the lower-level objective. Moreover, when the upper-level objective is non-convex, our method requires ${\mathcal{O}}(\max\{1/\epsilon_f^2,1/(\epsilon_f\epsilon_g)\})$ iterations to find an $(\epsilon_f,\epsilon_g)$-optimal solution. We further prove stronger convergence guarantees under the H\"olderian error bound assumption on the lower-level problem. To the best of our knowledge, our method achieves the best-known iteration complexity for the considered bilevel problem. We also present numerical experiments to showcase the superior performance of our method compared with state-of-the-art methods.
Generalized Optimistic Methods for Convex-Concave Saddle Point Problems
Feb 19, 2022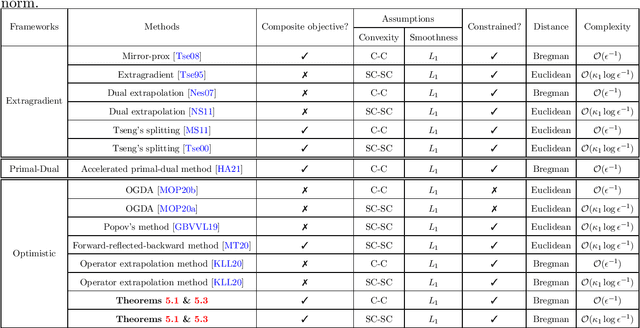
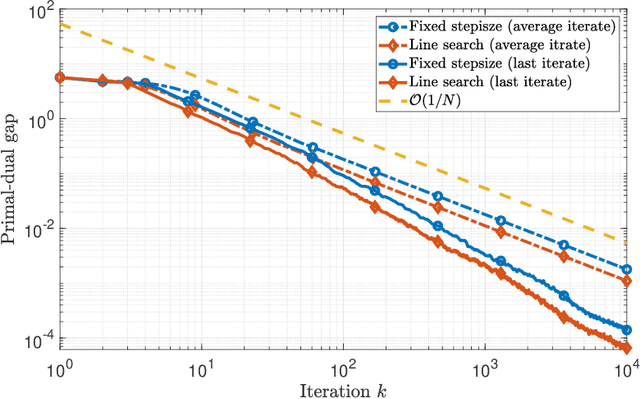
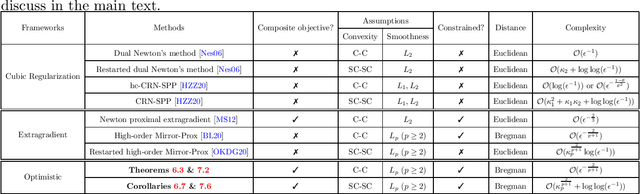
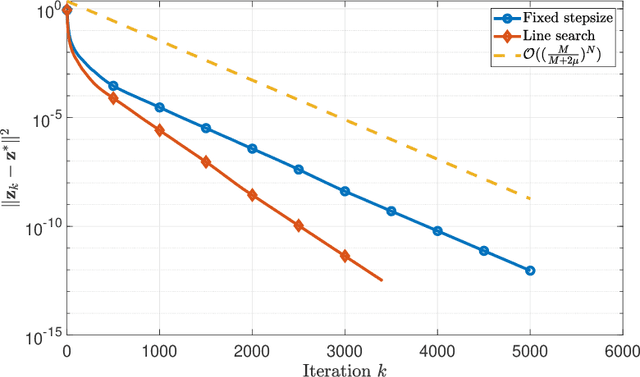
The optimistic gradient method has seen increasing popularity as an efficient first-order method for solving convex-concave saddle point problems. To analyze its iteration complexity, a recent work [arXiv:1901.08511] proposed an interesting perspective that interprets the optimistic gradient method as an approximation to the proximal point method. In this paper, we follow this approach and distill the underlying idea of optimism to propose a generalized optimistic method, which encompasses the optimistic gradient method as a special case. Our general framework can handle constrained saddle point problems with composite objective functions and can work with arbitrary norms with compatible Bregman distances. Moreover, we also develop an adaptive line search scheme to select the stepsizes without knowledge of the smoothness coefficients. We instantiate our method with first-order, second-order and higher-order oracles and give sharp global iteration complexity bounds. When the objective function is convex-concave, we show that the averaged iterates of our $p$-th-order method ($p\geq 1$) converge at a rate of $\mathcal{O}(1/N^\frac{p+1}{2})$. When the objective function is further strongly-convex-strongly-concave, we prove a complexity bound of $\mathcal{O}(\frac{L_1}{\mu}\log\frac{1}{\epsilon})$ for our first-order method and a bound of $\mathcal{O}((L_p D^\frac{p-1}{2}/\mu)^{\frac{2}{p+1}}+\log\log\frac{1}{\epsilon})$ for our $p$-th-order method ($p\geq 2$) respectively, where $L_p$ ($p\geq 1$) is the Lipschitz constant of the $p$-th-order derivative, $\mu$ is the strongly-convex parameter, and $D$ is the initial Bregman distance to the saddle point. Moreover, our line search scheme provably only requires an almost constant number of calls to a subproblem solver per iteration on average, making our first-order and second-order methods particularly amenable to implementation.
Antenna Efficiency in Massive MIMO Detection
Apr 23, 2021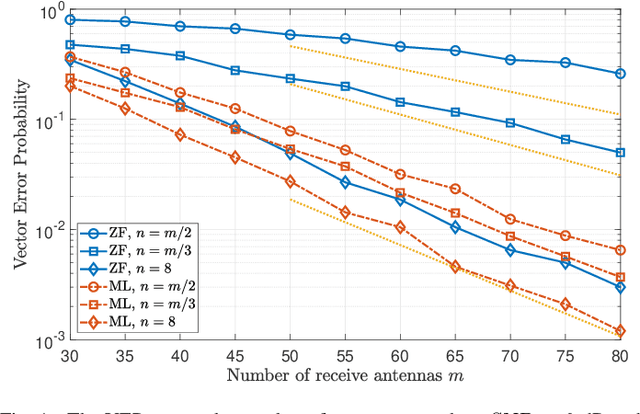

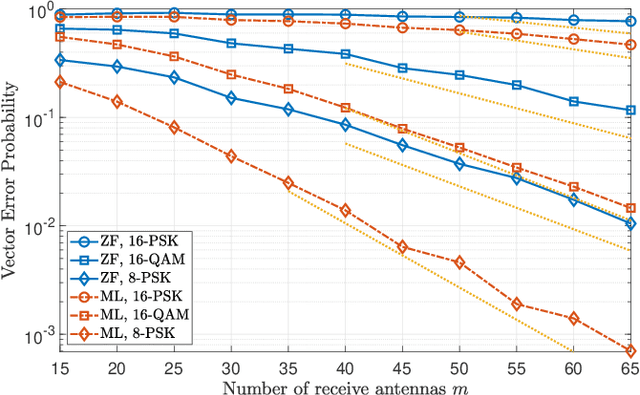
In this paper, we consider the multi-user detection problem in a multiple-input multiple-output (MIMO) system, where the number of receive antennas at the base station (BS) grows infinitely large. We propose a new performance metric, called antenna efficiency, to characterize how fast the vector error probability (VEP) decreases as the number of receive antennas increases in the large system limit. We analyze the optimal maximum-likelihood (ML) detector and the simple zero-forcing (ZF) detector and prove that their antenna efficiency admits a simple closed form, which quantifies the impacts of the user-to-antenna ratio, the signal-to-noise ratio (SNR), and the constellation set on the VEP. Numerical results show that our analysis can well describe the empirical detection error performance in a realistic massive MIMO system.
Tightness and Equivalence of Semidefinite Relaxations for MIMO Detection
Feb 09, 2021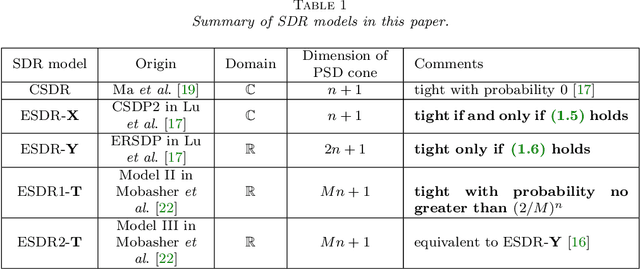
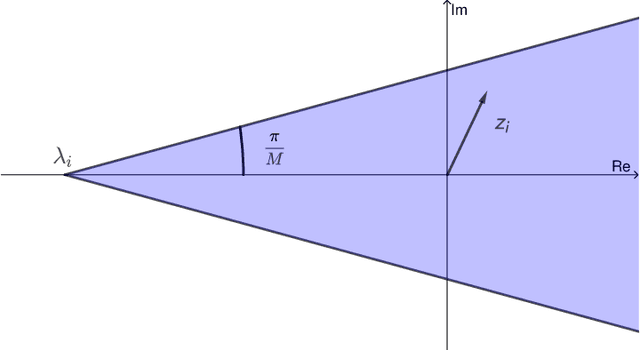
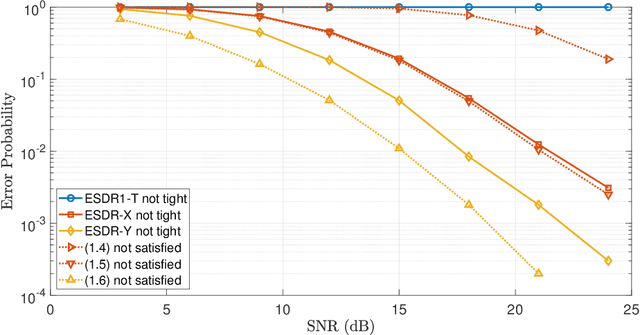

The multiple-input multiple-output (MIMO) detection problem, a fundamental problem in modern digital communications, is to detect a vector of transmitted symbols from the noisy outputs of a fading MIMO channel. The maximum likelihood detector can be formulated as a complex least-squares problem with discrete variables, which is NP-hard in general. Various semidefinite relaxation (SDR) methods have been proposed in the literature to solve the problem due to their polynomial-time worst-case complexity and good detection error rate performance. In this paper, we consider two popular classes of SDR-based detectors and study the conditions under which the SDRs are tight and the relationship between different SDR models. For the enhanced complex and real SDRs proposed recently by Lu et al., we refine their analysis and derive the necessary and sufficient condition for the complex SDR to be tight, as well as a necessary condition for the real SDR to be tight. In contrast, we also show that another SDR proposed by Mobasher et al. is not tight with high probability under mild conditions. Moreover, we establish a general theorem that shows the equivalence between two subsets of positive semidefinite matrices in different dimensions by exploiting a special "separable" structure in the constraints. Our theorem recovers two existing equivalence results of SDRs defined in different settings and has the potential to find other applications due to its generality.