 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimosthenis Karatzas
Machine Unlearning for Document Classification
Apr 29, 2024
Document understanding models have recently demonstrated remarkable performance by leveraging extensive collections of user documents. However, since documents often contain large amounts of personal data, their usage can pose a threat to user privacy and weaken the bonds of trust between humans and AI services. In response to these concerns, legislation advocating ``the right to be forgotten" has recently been proposed, allowing users to request the removal of private information from computer systems and neural network models. A novel approach, known as machine unlearning, has emerged to make AI models forget about a particular class of data. In our research, we explore machine unlearning for document classification problems, representing, to the best of our knowledge, the first investigation into this area. Specifically, we consider a realistic scenario where a remote server houses a well-trained model and possesses only a small portion of training data. This setup is designed for efficient forgetting manipulation. This work represents a pioneering step towards the development of machine unlearning methods aimed at addressing privacy concerns in document analysis applications. Our code is publicly available at \url{https://github.com/leitro/MachineUnlearning-DocClassification}.
Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
Apr 29, 2024Documents are 2-dimensional carriers of written communication, and as such their interpretation requires a multi-modal approach where textual and visual information are efficiently combined. Document Visual Question Answering (Document VQA), due to this multi-modal nature, has garnered significant interest from both the document understanding and natural language processing communities. The state-of-the-art single-page Document VQA methods show impressive performance, yet in multi-page scenarios, these methods struggle. They have to concatenate all pages into one large page for processing, demanding substantial GPU resources, even for evaluation. In this work, we propose a novel method and efficient training strategy for multi-page Document VQA tasks. In particular, we employ a visual-only document representation, leveraging the encoder from a document understanding model, Pix2Struct. Our approach utilizes a self-attention scoring mechanism to generate relevance scores for each document page, enabling the retrieval of pertinent pages. This adaptation allows us to extend single-page Document VQA models to multi-page scenarios without constraints on the number of pages during evaluation, all with minimal demand for GPU resources. Our extensive experiments demonstrate not only achieving state-of-the-art performance without the need for Optical Character Recognition (OCR), but also sustained performance in scenarios extending to documents of nearly 800 pages compared to a maximum of 20 pages in the MP-DocVQA dataset. Our code is publicly available at \url{https://github.com/leitro/SelfAttnScoring-MPDocVQA}.
Multimodal Transformer for Comics Text-Cloze
Mar 06, 2024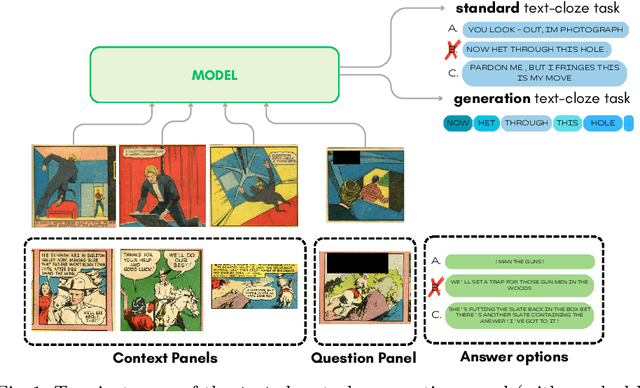


This work explores a closure task in comics, a medium where visual and textual elements are intricately intertwined. Specifically, Text-cloze refers to the task of selecting the correct text to use in a comic panel, given its neighboring panels. Traditional methods based on recurrent neural networks have struggled with this task due to limited OCR accuracy and inherent model limitations. We introduce a novel Multimodal Large Language Model (Multimodal-LLM) architecture, specifically designed for Text-cloze, achieving a 10% improvement over existing state-of-the-art models in both its easy and hard variants. Central to our approach is a Domain-Adapted ResNet-50 based visual encoder, fine-tuned to the comics domain in a self-supervised manner using SimCLR. This encoder delivers comparable results to more complex models with just one-fifth of the parameters. Additionally, we release new OCR annotations for this dataset, enhancing model input quality and resulting in another 1% improvement. Finally, we extend the task to a generative format, establishing new baselines and expanding the research possibilities in the field of comics analysis.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Understanding Video Scenes through Text: Insights from Text-based Video Question Answering
Sep 11, 2023
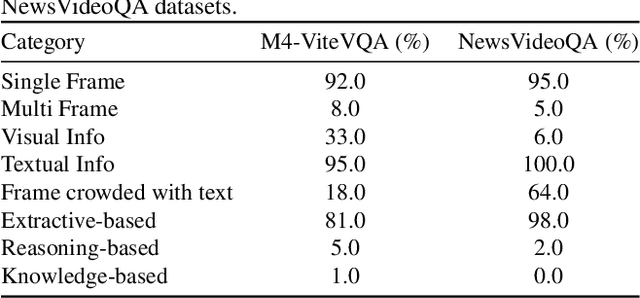
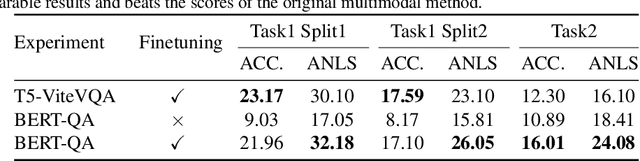

Researchers have extensively studied the field of vision and language, discovering that both visual and textual content is crucial for understanding scenes effectively. Particularly, comprehending text in videos holds great significance, requiring both scene text understanding and temporal reasoning. This paper focuses on exploring two recently introduced datasets, NewsVideoQA and M4-ViteVQA, which aim to address video question answering based on textual content. The NewsVideoQA dataset contains question-answer pairs related to the text in news videos, while M4-ViteVQA comprises question-answer pairs from diverse categories like vlogging, traveling, and shopping. We provide an analysis of the formulation of these datasets on various levels, exploring the degree of visual understanding and multi-frame comprehension required for answering the questions. Additionally, the study includes experimentation with BERT-QA, a text-only model, which demonstrates comparable performance to the original methods on both datasets, indicating the shortcomings in the formulation of these datasets. Furthermore, we also look into the domain adaptation aspect by examining the effectiveness of training on M4-ViteVQA and evaluating on NewsVideoQA and vice-versa, thereby shedding light on the challenges and potential benefits of out-of-domain training.
STEP -- Towards Structured Scene-Text Spotting
Sep 05, 2023

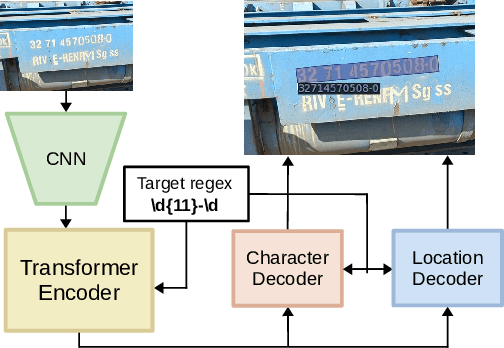
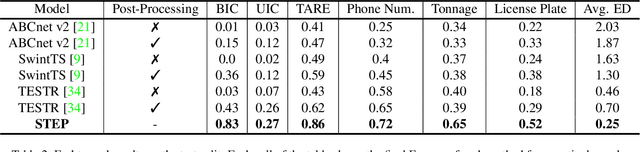
We introduce the structured scene-text spotting task, which requires a scene-text OCR system to spot text in the wild according to a query regular expression. Contrary to generic scene text OCR, structured scene-text spotting seeks to dynamically condition both scene text detection and recognition on user-provided regular expressions. To tackle this task, we propose the Structured TExt sPotter (STEP), a model that exploits the provided text structure to guide the OCR process. STEP is able to deal with regular expressions that contain spaces and it is not bound to detection at the word-level granularity. Our approach enables accurate zero-shot structured text spotting in a wide variety of real-world reading scenarios and is solely trained on publicly available data. To demonstrate the effectiveness of our approach, we introduce a new challenging test dataset that contains several types of out-of-vocabulary structured text, reflecting important reading applications of fields such as prices, dates, serial numbers, license plates etc. We demonstrate that STEP can provide specialised OCR performance on demand in all tested scenarios.
Reading Between the Lanes: Text VideoQA on the Road
Jul 08, 2023


Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness. Scene text recognition in motion is a challenging problem, while textual cues typically appear for a short time span, and early detection at a distance is necessary. Systems that exploit such information to assist the driver should not only extract and incorporate visual and textual cues from the video stream but also reason over time. To address this issue, we introduce RoadTextVQA, a new dataset for the task of video question answering (VideoQA) in the context of driver assistance. RoadTextVQA consists of $3,222$ driving videos collected from multiple countries, annotated with $10,500$ questions, all based on text or road signs present in the driving videos. We assess the performance of state-of-the-art video question answering models on our RoadTextVQA dataset, highlighting the significant potential for improvement in this domain and the usefulness of the dataset in advancing research on in-vehicle support systems and text-aware multimodal question answering. The dataset is available at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtextvqa
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023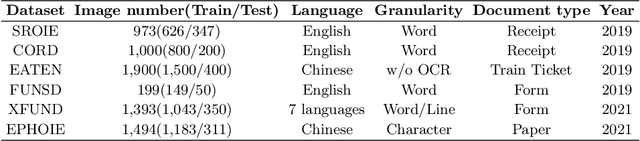
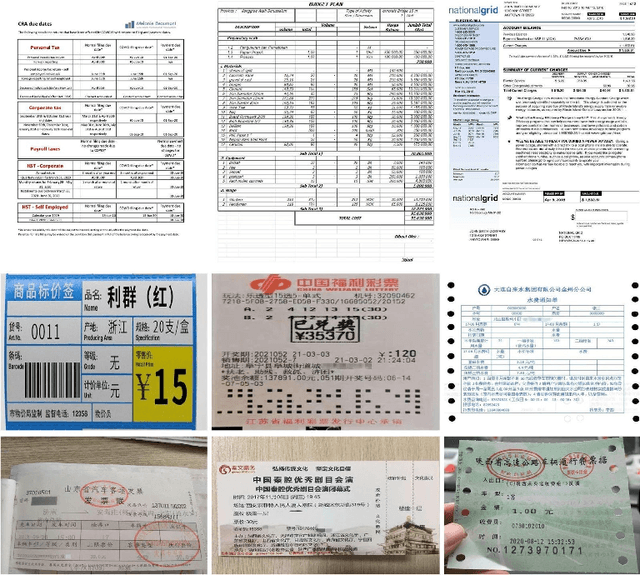

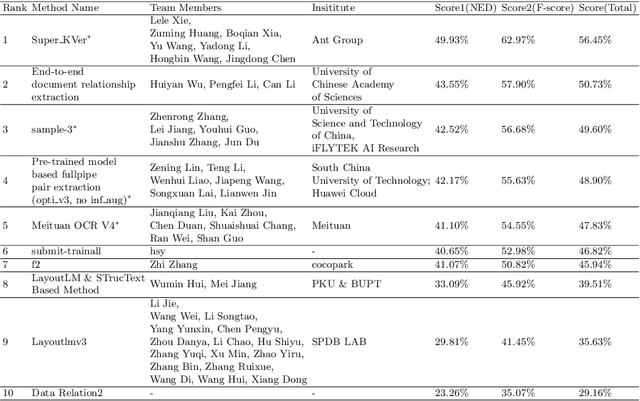
Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
ICDAR 2023 Competition on Reading the Seal Title
Apr 24, 2023


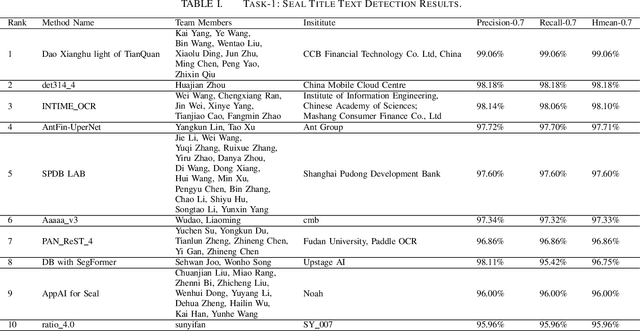
Reading seal title text is a challenging task due to the variable shapes of seals, curved text, background noise, and overlapped text. However, this important element is commonly found in official and financial scenarios, and has not received the attention it deserves in the field of OCR technology. To promote research in this area, we organized ICDAR 2023 competition on reading the seal title (ReST), which included two tasks: seal title text detection (Task 1) and end-to-end seal title recognition (Task 2). We constructed a dataset of 10,000 real seal data, covering the most common classes of seals, and labeled all seal title texts with text polygons and text contents. The competition opened on 30th December, 2022 and closed on 20th March, 2023. The competition attracted 53 participants from academia and industry including 28 submissions for Task 1 and 25 submissions for Task 2, which demonstrated significant interest in this challenging task. In this report, we present an overview of the competition, including the organization, challenges, and results. We describe the dataset and tasks, and summarize the submissions and evaluation results. The results show that significant progress has been made in the field of seal title text reading, and we hope that this competition will inspire further research and development in this important area of OCR technology.
ICDAR 2023 Video Text Reading Competition for Dense and Small Text
Apr 10, 2023
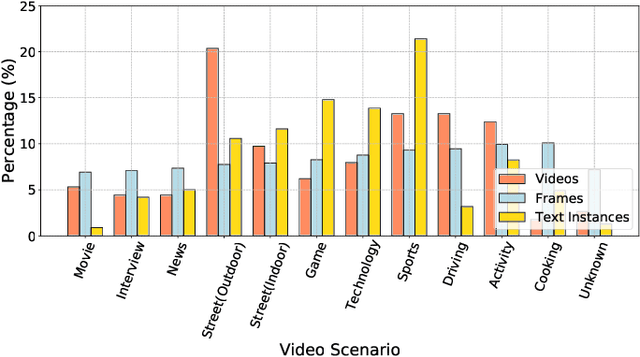
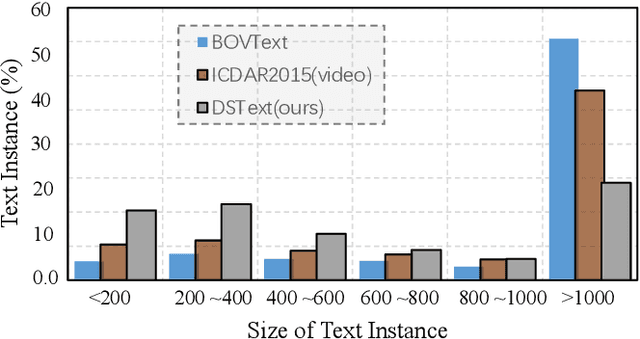

Recently, video text detection, tracking, and recognition in natural scenes are becoming very popular in the computer vision community. However, most existing algorithms and benchmarks focus on common text cases (e.g., normal size, density) and single scenarios, while ignoring extreme video text challenges, i.e., dense and small text in various scenarios. In this competition report, we establish a video text reading benchmark, DSText, which focuses on dense and small text reading challenges in the video with various scenarios. Compared with the previous datasets, the proposed dataset mainly include three new challenges: 1) Dense video texts, a new challenge for video text spotter. 2) High-proportioned small texts. 3) Various new scenarios, e.g., Game, sports, etc. The proposed DSText includes 100 video clips from 12 open scenarios, supporting two tasks (i.e., video text tracking (Task 1) and end-to-end video text spotting (Task 2)). During the competition period (opened on 15th February 2023 and closed on 20th March 2023), a total of 24 teams participated in the three proposed tasks with around 30 valid submissions, respectively. In this article, we describe detailed statistical information of the dataset, tasks, evaluation protocols and the results summaries of the ICDAR 2023 on DSText competition. Moreover, we hope the benchmark will promise video text research in the community.