 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongrui Liu
MLP Can Be A Good Transformer Learner
Apr 08, 2024
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
Self-Supervised Multi-Frame Neural Scene Flow
Mar 24, 2024Neural Scene Flow Prior (NSFP) and Fast Neural Scene Flow (FNSF) have shown remarkable adaptability in the context of large out-of-distribution autonomous driving. Despite their success, the underlying reasons for their astonishing generalization capabilities remain unclear. Our research addresses this gap by examining the generalization capabilities of NSFP through the lens of uniform stability, revealing that its performance is inversely proportional to the number of input point clouds. This finding sheds light on NSFP's effectiveness in handling large-scale point cloud scene flow estimation tasks. Motivated by such theoretical insights, we further explore the improvement of scene flow estimation by leveraging historical point clouds across multiple frames, which inherently increases the number of point clouds. Consequently, we propose a simple and effective method for multi-frame point cloud scene flow estimation, along with a theoretical evaluation of its generalization abilities. Our analysis confirms that the proposed method maintains a limited generalization error, suggesting that adding multiple frames to the scene flow optimization process does not detract from its generalizability. Extensive experimental results on large-scale autonomous driving Waymo Open and Argoverse lidar datasets demonstrate that the proposed method achieves state-of-the-art performance.
Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
Feb 29, 2024Ensuring the trustworthiness of large language models (LLMs) is crucial. Most studies concentrate on fully pre-trained LLMs to better understand and improve LLMs' trustworthiness. In this paper, to reveal the untapped potential of pre-training, we pioneer the exploration of LLMs' trustworthiness during this period, focusing on five key dimensions: reliability, privacy, toxicity, fairness, and robustness. To begin with, we apply linear probing to LLMs. The high probing accuracy suggests that \textit{LLMs in early pre-training can already distinguish concepts in each trustworthiness dimension}. Therefore, to further uncover the hidden possibilities of pre-training, we extract steering vectors from a LLM's pre-training checkpoints to enhance the LLM's trustworthiness. Finally, inspired by~\citet{choi2023understanding} that mutual information estimation is bounded by linear probing accuracy, we also probe LLMs with mutual information to investigate the dynamics of trustworthiness during pre-training. We are the first to observe a similar two-phase phenomenon: fitting and compression~\citep{shwartz2017opening}. This research provides an initial exploration of trustworthiness modeling during LLM pre-training, seeking to unveil new insights and spur further developments in the field. We will make our code publicly accessible at \url{https://github.com/ChnQ/TracingLLM}.
Identifying Semantic Induction Heads to Understand In-Context Learning
Feb 20, 2024Although large language models (LLMs) have demonstrated remarkable performance, the lack of transparency in their inference logic raises concerns about their trustworthiness. To gain a better understanding of LLMs, we conduct a detailed analysis of the operations of attention heads and aim to better understand the in-context learning of LLMs. Specifically, we investigate whether attention heads encode two types of relationships between tokens present in natural languages: the syntactic dependency parsed from sentences and the relation within knowledge graphs. We find that certain attention heads exhibit a pattern where, when attending to head tokens, they recall tail tokens and increase the output logits of those tail tokens. More crucially, the formulation of such semantic induction heads has a close correlation with the emergence of the in-context learning ability of language models. The study of semantic attention heads advances our understanding of the intricate operations of attention heads in transformers, and further provides new insights into the in-context learning of LLMs.
Concept-Level Explanation for the Generalization of a DNN
Feb 25, 2023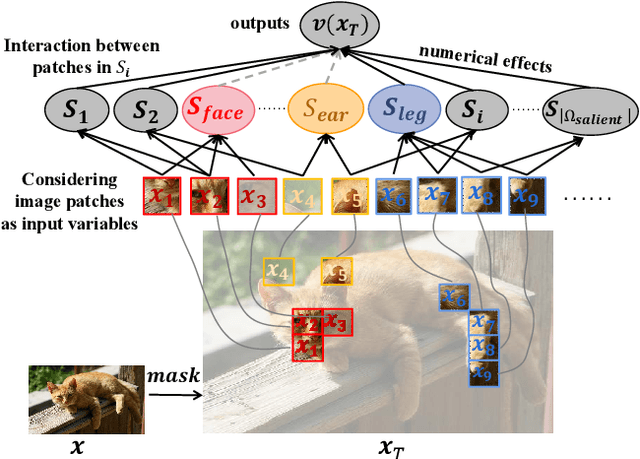
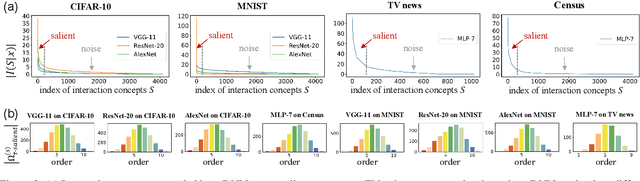

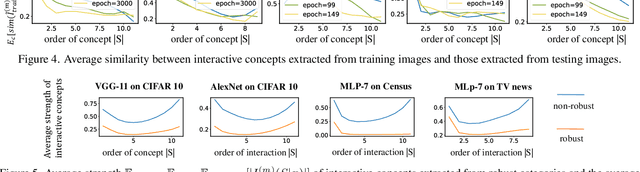
This paper explains the generalization power of a deep neural network (DNN) from the perspective of interactive concepts. Many recent studies have quantified a clear emergence of interactive concepts encoded by the DNN, which have been observed on different DNNs during the learning process. Therefore, in this paper, we investigate the generalization power of each interactive concept, and we use the generalization power of different interactive concepts to explain the generalization power of the entire DNN. Specifically, we define the complexity of each interactive concept. We find that simple concepts can be better generalized to testing data than complex concepts. The DNN with strong generalization power usually learns simple concepts more quickly and encodes fewer complex concepts. More crucially, we discover the detouring dynamics of learning complex concepts, which explain both the high learning difficulty and the low generalization power of complex concepts.
Self-supervised Point Cloud Registration with Deep Versatile Descriptors
Jan 25, 2022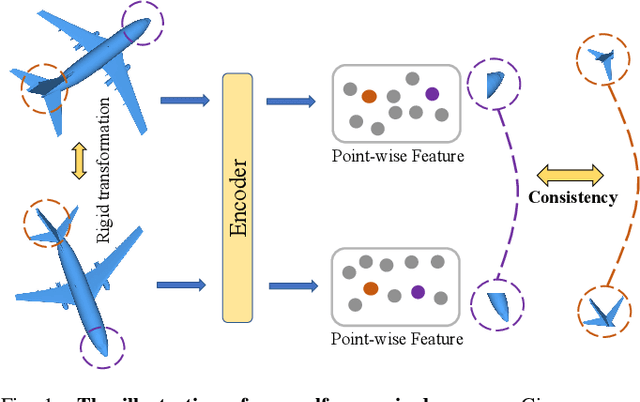

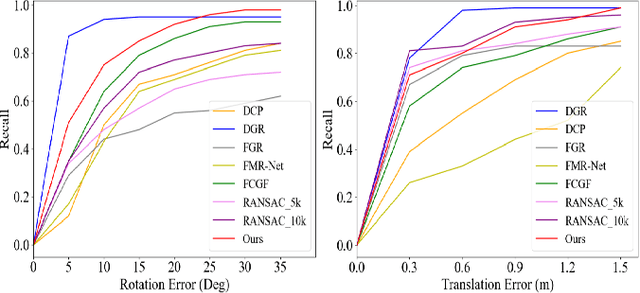

Recent years have witnessed an increasing trend toward solving point cloud registration problems with various deep learning-based algorithms. Compared to supervised/semi-supervised registration methods, unsupervised methods require no human annotations. However, unsupervised methods mainly depend on the global descriptors, which ignore the high-level representations of local geometries. In this paper, we propose a self-supervised registration scheme with a novel Deep Versatile Descriptors (DVD), jointly considering global representations and local representations. The DVD is motivated by a key observation that the local distinctive geometric structures of the point cloud by two subset points can be employed to enhance the representation ability of the feature extraction module. Furthermore, we utilize two additional tasks (reconstruction and normal estimation) to enhance the transformation awareness of the proposed DVDs. Lastly, we conduct extensive experiments on synthetic and real-world datasets, demonstrating that our method achieves state-of-the-art performance against competing methods over a wide range of experimental settings.
Multi-View Partial (MVP) Point Cloud Challenge 2021 on Completion and Registration: Methods and Results
Dec 22, 2021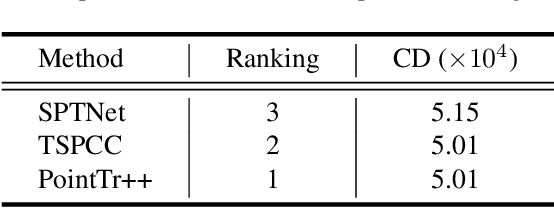
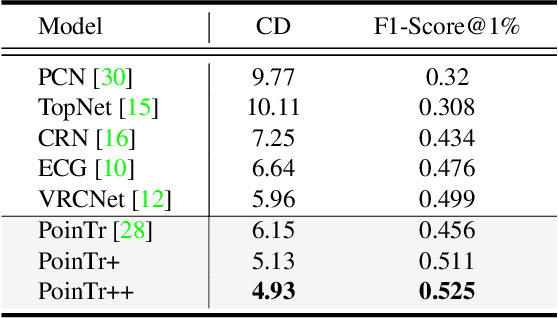
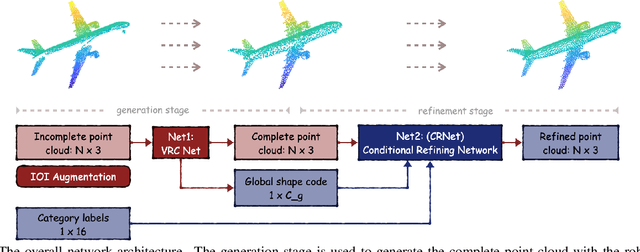
As real-scanned point clouds are mostly partial due to occlusions and viewpoints, reconstructing complete 3D shapes based on incomplete observations becomes a fundamental problem for computer vision. With a single incomplete point cloud, it becomes the partial point cloud completion problem. Given multiple different observations, 3D reconstruction can be addressed by performing partial-to-partial point cloud registration. Recently, a large-scale Multi-View Partial (MVP) point cloud dataset has been released, which consists of over 100,000 high-quality virtual-scanned partial point clouds. Based on the MVP dataset, this paper reports methods and results in the Multi-View Partial Point Cloud Challenge 2021 on Completion and Registration. In total, 128 participants registered for the competition, and 31 teams made valid submissions. The top-ranked solutions will be analyzed, and then we will discuss future research directions.
Trap of Feature Diversity in the Learning of MLPs
Dec 02, 2021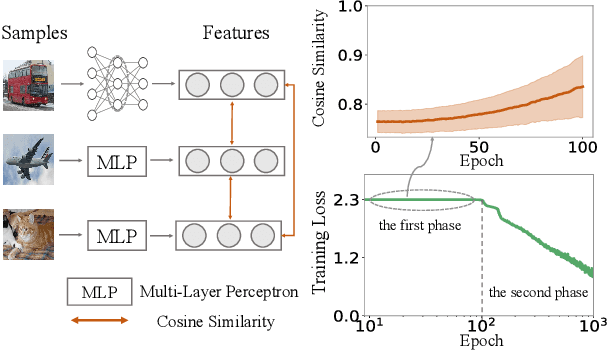
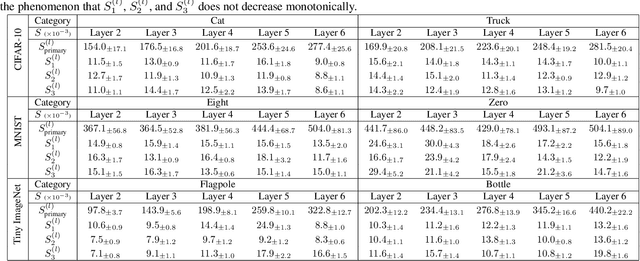

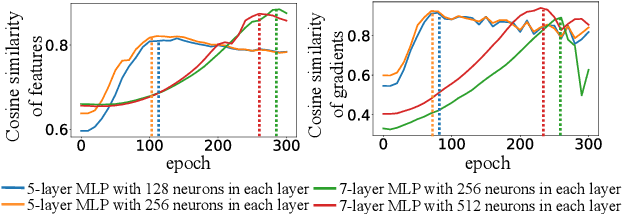
In this paper, we discover a two-phase phenomenon in the learning of multi-layer perceptrons (MLPs). I.e., in the first phase, the training loss does not decrease significantly, but the similarity of features between different samples keeps increasing, which hurts the feature diversity. We explain such a two-phase phenomenon in terms of the learning dynamics of the MLP. Furthermore, we propose two normalization operations to eliminate the two-phase phenomenon, which avoids the decrease of the feature diversity and speeds up the training process.
Interpreting Representation Quality of DNNs for 3D Point Cloud Processing
Nov 05, 2021
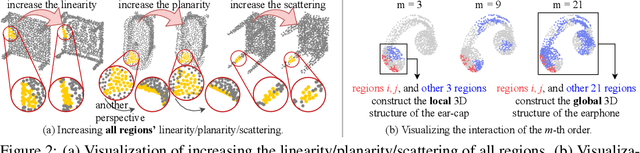
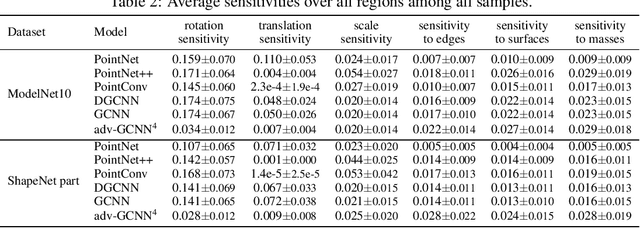
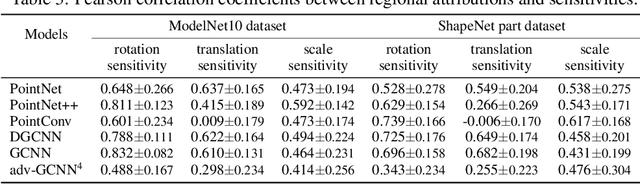
In this paper, we evaluate the quality of knowledge representations encoded in deep neural networks (DNNs) for 3D point cloud processing. We propose a method to disentangle the overall model vulnerability into the sensitivity to the rotation, the translation, the scale, and local 3D structures. Besides, we also propose metrics to evaluate the spatial smoothness of encoding 3D structures, and the representation complexity of the DNN. Based on such analysis, experiments expose representation problems with classic DNNs, and explain the utility of the adversarial training.
Deep Models with Fusion Strategies for MVP Point Cloud Registration
Oct 18, 2021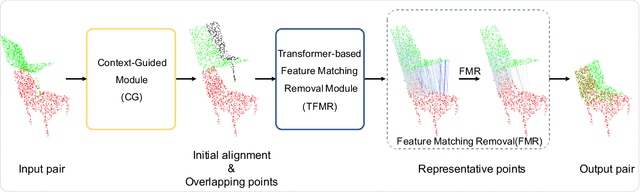

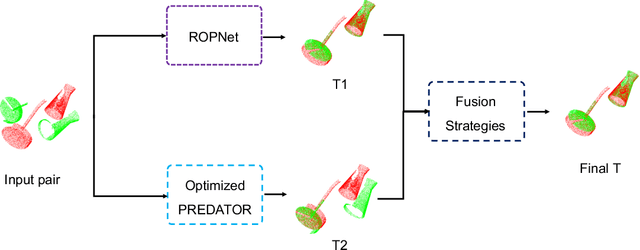

The main goal of point cloud registration in Multi-View Partial (MVP) Challenge 2021 is to estimate a rigid transformation to align a point cloud pair. The pairs in this competition have the characteristics of low overlap, non-uniform density, unrestricted rotations and ambiguity, which pose a huge challenge to the registration task. In this report, we introduce our solution to the registration task, which fuses two deep learning models: ROPNet and PREDATOR, with customized ensemble strategies. Finally, we achieved the second place in the registration track with 2.96546, 0.02632 and 0.07808 under the the metrics of Rot\_Error, Trans\_Error and MSE, respectively.