 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeitong Tan
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 2024
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Feb 19, 2024Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
GO-NeRF: Generating Virtual Objects in Neural Radiance Fields
Jan 11, 2024Despite advances in 3D generation, the direct creation of 3D objects within an existing 3D scene represented as NeRF remains underexplored. This process requires not only high-quality 3D object generation but also seamless composition of the generated 3D content into the existing NeRF. To this end, we propose a new method, GO-NeRF, capable of utilizing scene context for high-quality and harmonious 3D object generation within an existing NeRF. Our method employs a compositional rendering formulation that allows the generated 3D objects to be seamlessly composited into the scene utilizing learned 3D-aware opacity maps without introducing unintended scene modification. Moreover, we also develop tailored optimization objectives and training strategies to enhance the model's ability to exploit scene context and mitigate artifacts, such as floaters, originating from 3D object generation within a scene. Extensive experiments on both feed-forward and $360^o$ scenes show the superior performance of our proposed GO-NeRF in generating objects harmoniously composited with surrounding scenes and synthesizing high-quality novel view images. Project page at {\url{https://daipengwa.github.io/GO-NeRF/}.
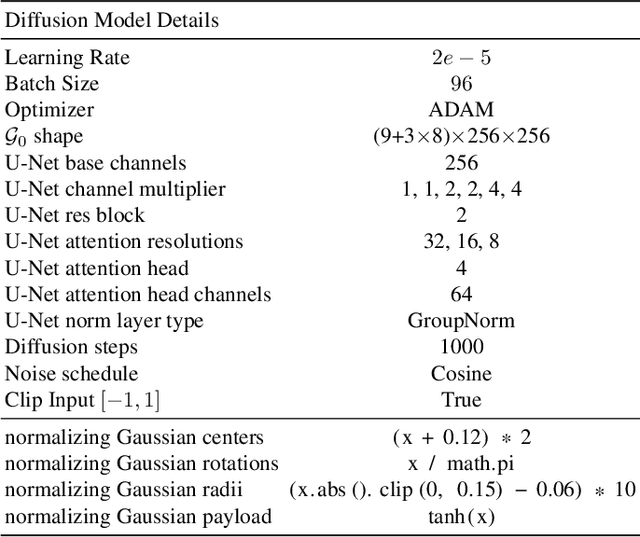
MVDD: Multi-View Depth Diffusion Models
Dec 19, 2023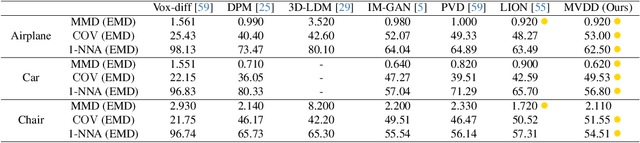
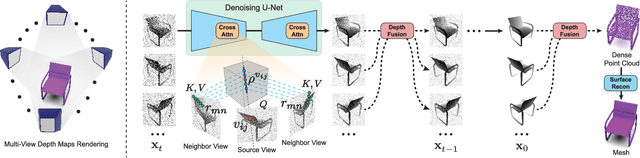
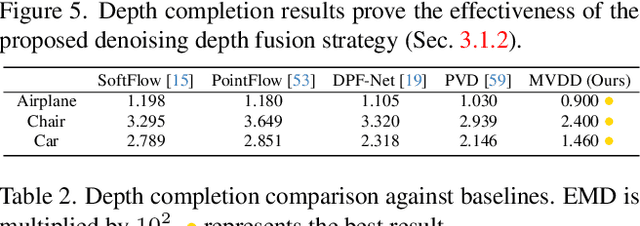

Denoising diffusion models have demonstrated outstanding results in 2D image generation, yet it remains a challenge to replicate its success in 3D shape generation. In this paper, we propose leveraging multi-view depth, which represents complex 3D shapes in a 2D data format that is easy to denoise. We pair this representation with a diffusion model, MVDD, that is capable of generating high-quality dense point clouds with 20K+ points with fine-grained details. To enforce 3D consistency in multi-view depth, we introduce an epipolar line segment attention that conditions the denoising step for a view on its neighboring views. Additionally, a depth fusion module is incorporated into diffusion steps to further ensure the alignment of depth maps. When augmented with surface reconstruction, MVDD can also produce high-quality 3D meshes. Furthermore, MVDD stands out in other tasks such as depth completion, and can serve as a 3D prior, significantly boosting many downstream tasks, such as GAN inversion. State-of-the-art results from extensive experiments demonstrate MVDD's excellent ability in 3D shape generation, depth completion, and its potential as a 3D prior for downstream tasks.
Gaussian3Diff: 3D Gaussian Diffusion for 3D Full Head Synthesis and Editing
Dec 19, 2023
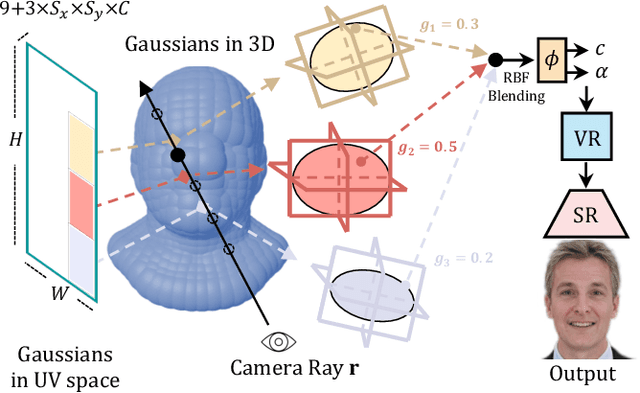

We present a novel framework for generating photorealistic 3D human head and subsequently manipulating and reposing them with remarkable flexibility. The proposed approach leverages an implicit function representation of 3D human heads, employing 3D Gaussians anchored on a parametric face model. To enhance representational capabilities and encode spatial information, we embed a lightweight tri-plane payload within each Gaussian rather than directly storing color and opacity. Additionally, we parameterize the Gaussians in a 2D UV space via a 3DMM, enabling effective utilization of the diffusion model for 3D head avatar generation. Our method facilitates the creation of diverse and realistic 3D human heads with fine-grained editing over facial features and expressions. Extensive experiments demonstrate the effectiveness of our method.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023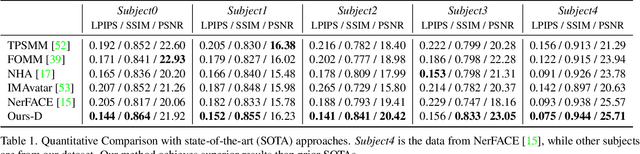

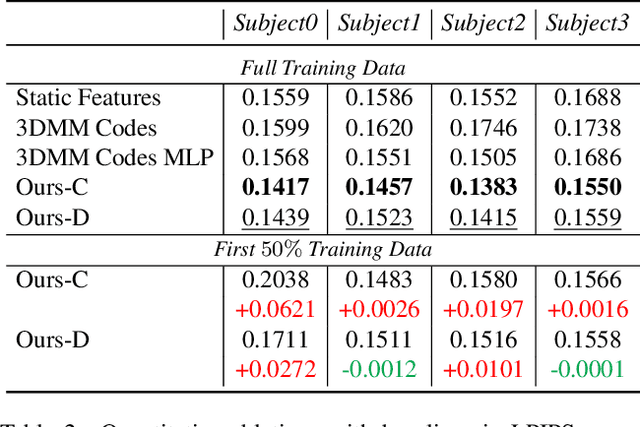
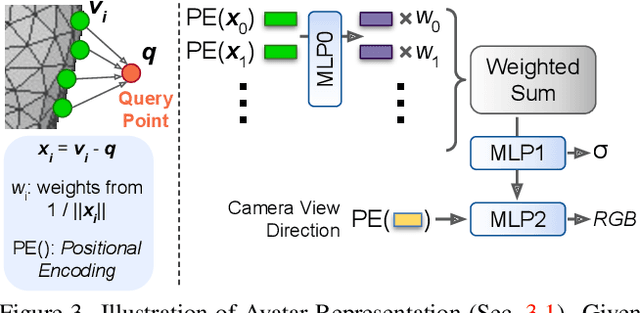
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.
VoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting
Jan 13, 2022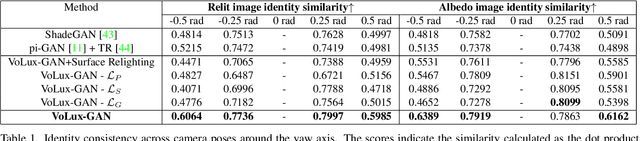
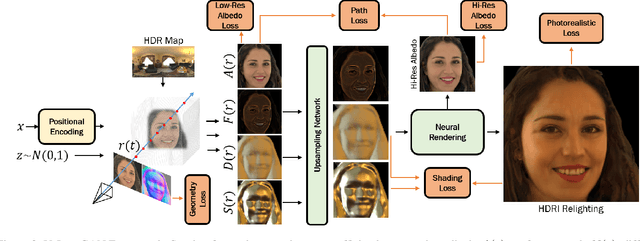
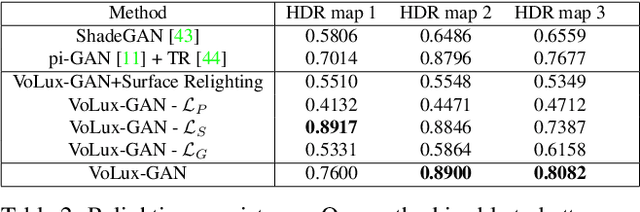

We propose VoLux-GAN, a generative framework to synthesize 3D-aware faces with convincing relighting. Our main contribution is a volumetric HDRI relighting method that can efficiently accumulate albedo, diffuse and specular lighting contributions along each 3D ray for any desired HDR environmental map. Additionally, we show the importance of supervising the image decomposition process using multiple discriminators. In particular, we propose a data augmentation technique that leverages recent advances in single image portrait relighting to enforce consistent geometry, albedo, diffuse and specular components. Multiple experiments and comparisons with other generative frameworks show how our model is a step forward towards photorealistic relightable 3D generative models.
HumanGPS: Geodesic PreServing Feature for Dense Human Correspondences
Mar 29, 2021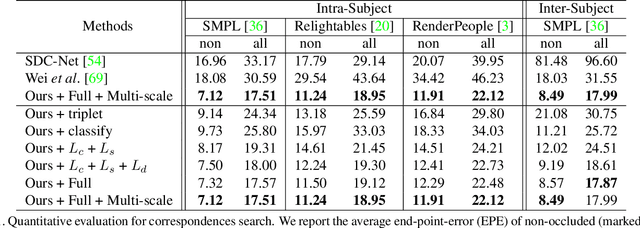
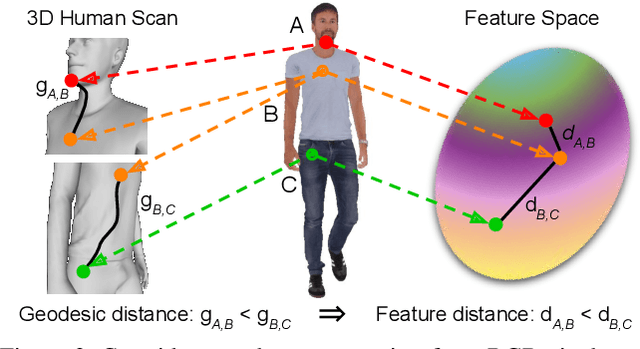
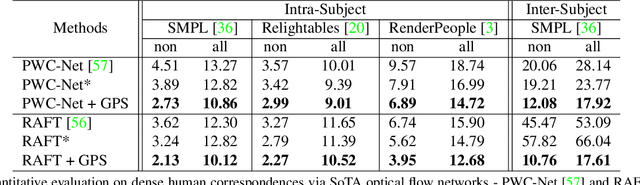
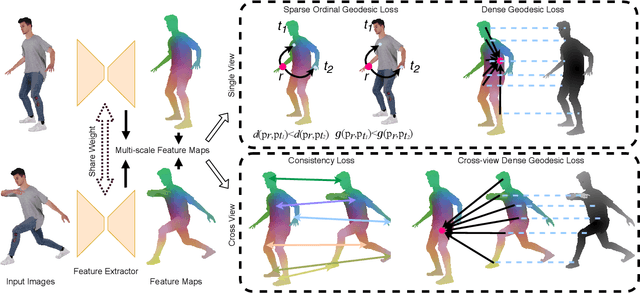
In this paper, we address the problem of building dense correspondences between human images under arbitrary camera viewpoints and body poses. Prior art either assumes small motion between frames or relies on local descriptors, which cannot handle large motion or visually ambiguous body parts, e.g., left vs. right hand. In contrast, we propose a deep learning framework that maps each pixel to a feature space, where the feature distances reflect the geodesic distances among pixels as if they were projected onto the surface of a 3D human scan. To this end, we introduce novel loss functions to push features apart according to their geodesic distances on the surface. Without any semantic annotation, the proposed embeddings automatically learn to differentiate visually similar parts and align different subjects into an unified feature space. Extensive experiments show that the learned embeddings can produce accurate correspondences between images with remarkable generalization capabilities on both intra and inter subjects.
Self-Supervised Human Depth Estimation from Monocular Videos
May 07, 2020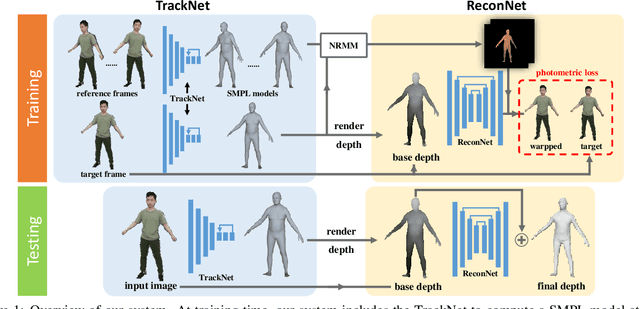
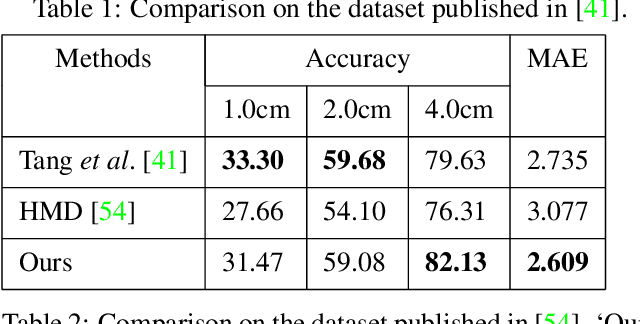
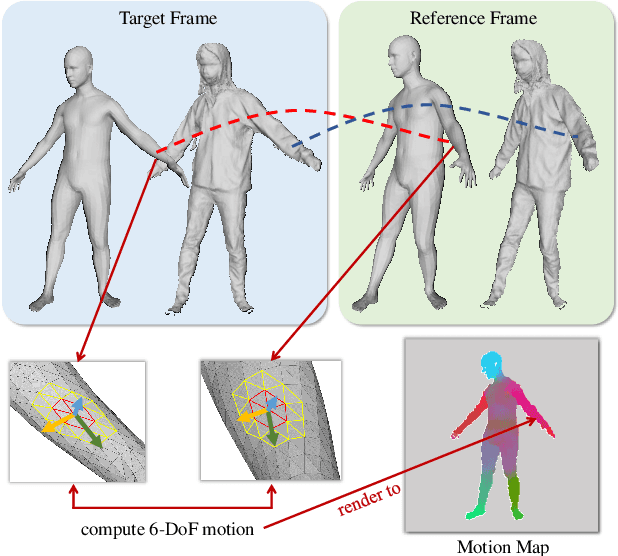
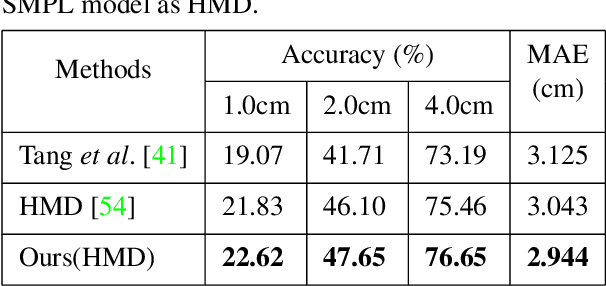
Previous methods on estimating detailed human depth often require supervised training with `ground truth' depth data. This paper presents a self-supervised method that can be trained on YouTube videos without known depth, which makes training data collection simple and improves the generalization of the learned network. The self-supervised learning is achieved by minimizing a photo-consistency loss, which is evaluated between a video frame and its neighboring frames warped according to the estimated depth and the 3D non-rigid motion of the human body. To solve this non-rigid motion, we first estimate a rough SMPL model at each video frame and compute the non-rigid body motion accordingly, which enables self-supervised learning on estimating the shape details. Experiments demonstrate that our method enjoys better generalization and performs much better on data in the wild.
Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching
Dec 18, 2019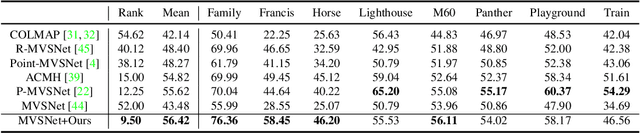
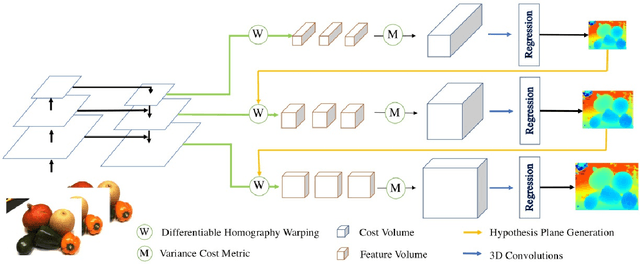
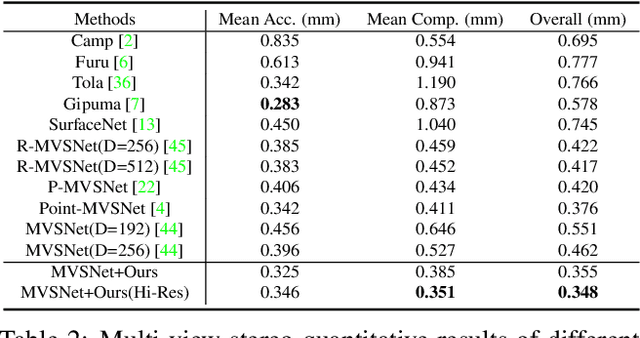
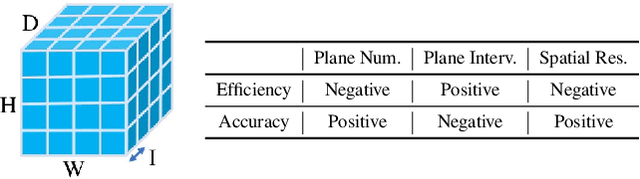
The deep multi-view stereo (MVS) and stereo matching approaches generally construct 3D cost volumes to regularize and regress the output depth or disparity. These methods are limited when high-resolution outputs are needed since the memory and time costs grow cubically as the volume resolution increases. In this paper, we propose a both memory and time efficient cost volume formulation that is complementary to existing multi-view stereo and stereo matching approaches based on 3D cost volumes. First, the proposed cost volume is built upon a standard feature pyramid encoding geometry and context at gradually finer scales. Then, we can narrow the depth (or disparity) range of each stage by the depth (or disparity) map from the previous stage. With gradually higher cost volume resolution and adaptive adjustment of depth (or disparity) intervals, the output is recovered in a coarser to fine manner. We apply the cascade cost volume to the representative MVS-Net, and obtain a 23.1% improvement on DTU benchmark (1st place), with 50.6% and 74.2% reduction in GPU memory and run-time. It is also the state-of-the-art learning-based method on Tanks and Temples benchmark. The statistics of accuracy, run-time and GPU memory on other representative stereo CNNs also validate the effectiveness of our proposed method.