 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanghao Li
EC-SLAM: Real-time Dense Neural RGB-D SLAM System with Effectively Constrained Global Bundle Adjustment
Apr 20, 2024




We introduce EC-SLAM, a real-time dense RGB-D simultaneous localization and mapping (SLAM) system utilizing Neural Radiance Fields (NeRF). Although recent NeRF-based SLAM systems have demonstrated encouraging outcomes, they have yet to completely leverage NeRF's capability to constrain pose optimization. By employing an effectively constrained global bundle adjustment (BA) strategy, our system makes use of NeRF's implicit loop closure correction capability. This improves the tracking accuracy by reinforcing the constraints on the keyframes that are most pertinent to the optimized current frame. In addition, by implementing a feature-based and uniform sampling strategy that minimizes the number of ineffective constraint points for pose optimization, we mitigate the effects of random sampling in NeRF. EC-SLAM utilizes sparse parametric encodings and the truncated signed distance field (TSDF) to represent the map in order to facilitate efficient fusion, resulting in reduced model parameters and accelerated convergence velocity. A comprehensive evaluation conducted on the Replica, ScanNet, and TUM datasets showcases cutting-edge performance, including enhanced reconstruction accuracy resulting from precise pose estimation, 21 Hz run time, and tracking precision improvements of up to 50\%. The source code is available at https://github.com/Lightingooo/EC-SLAM.
DFedADMM: Dual Constraints Controlled Model Inconsistency for Decentralized Federated Learning
Aug 16, 2023
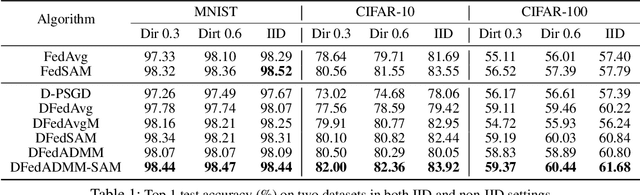
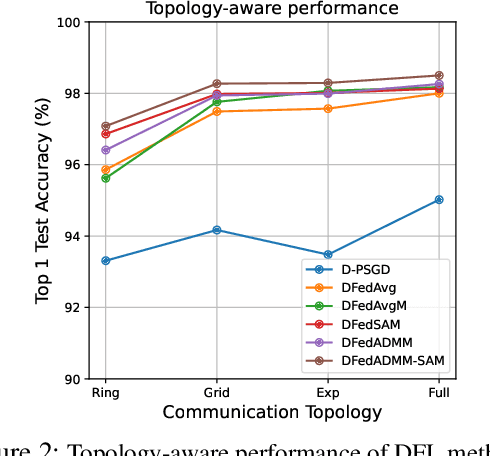
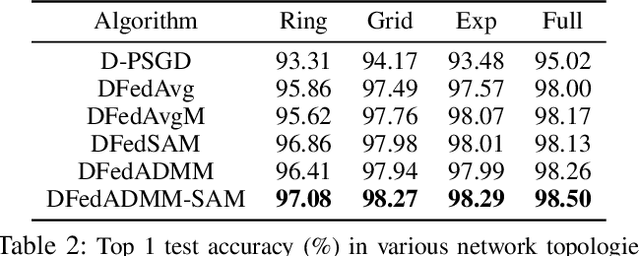
To address the communication burden issues associated with federated learning (FL), decentralized federated learning (DFL) discards the central server and establishes a decentralized communication network, where each client communicates only with neighboring clients. However, existing DFL methods still suffer from two major challenges: local inconsistency and local heterogeneous overfitting, which have not been fundamentally addressed by existing DFL methods. To tackle these issues, we propose novel DFL algorithms, DFedADMM and its enhanced version DFedADMM-SAM, to enhance the performance of DFL. The DFedADMM algorithm employs primal-dual optimization (ADMM) by utilizing dual variables to control the model inconsistency raised from the decentralized heterogeneous data distributions. The DFedADMM-SAM algorithm further improves on DFedADMM by employing a Sharpness-Aware Minimization (SAM) optimizer, which uses gradient perturbations to generate locally flat models and searches for models with uniformly low loss values to mitigate local heterogeneous overfitting. Theoretically, we derive convergence rates of $\small \mathcal{O}\Big(\frac{1}{\sqrt{KT}}+\frac{1}{KT(1-\psi)^2}\Big)$ and $\small \mathcal{O}\Big(\frac{1}{\sqrt{KT}}+\frac{1}{KT(1-\psi)^2}+ \frac{1}{T^{3/2}K^{1/2}}\Big)$ in the non-convex setting for DFedADMM and DFedADMM-SAM, respectively, where $1 - \psi$ represents the spectral gap of the gossip matrix. Empirically, extensive experiments on MNIST, CIFAR10 and CIFAR100 datesets demonstrate that our algorithms exhibit superior performance in terms of both generalization and convergence speed compared to existing state-of-the-art (SOTA) optimizers in DFL.
Visual Prompt Based Personalized Federated Learning
Mar 15, 2023



As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains prior knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings.
Subspace based Federated Unlearning
Feb 24, 2023



Federated learning (FL) enables multiple clients to train a machine learning model collaboratively without exchanging their local data. Federated unlearning is an inverse FL process that aims to remove a specified target client's contribution in FL to satisfy the user's right to be forgotten. Most existing federated unlearning algorithms require the server to store the history of the parameter updates, which is not applicable in scenarios where the server storage resource is constrained. In this paper, we propose a simple-yet-effective subspace based federated unlearning method, dubbed SFU, that lets the global model perform gradient ascent in the orthogonal space of input gradient spaces formed by other clients to eliminate the target client's contribution without requiring additional storage. Specifically, the server first collects the gradients generated from the target client after performing gradient ascent, and the input representation matrix is computed locally by the remaining clients. We also design a differential privacy method to protect the privacy of the representation matrix. Then the server merges those representation matrices to get the input gradient subspace and updates the global model in the orthogonal subspace of the input gradient subspace to complete the forgetting task with minimal model performance degradation. Experiments on MNIST, CIFAR10, and CIFAR100 show that SFU outperforms several state-of-the-art (SOTA) federated unlearning algorithms by a large margin in various settings.
FedHiSyn: A Hierarchical Synchronous Federated Learning Framework for Resource and Data Heterogeneity
Jun 21, 2022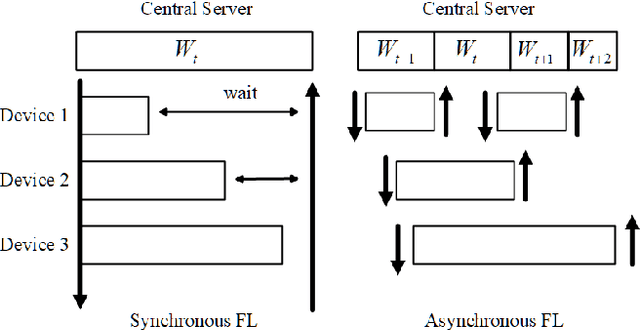
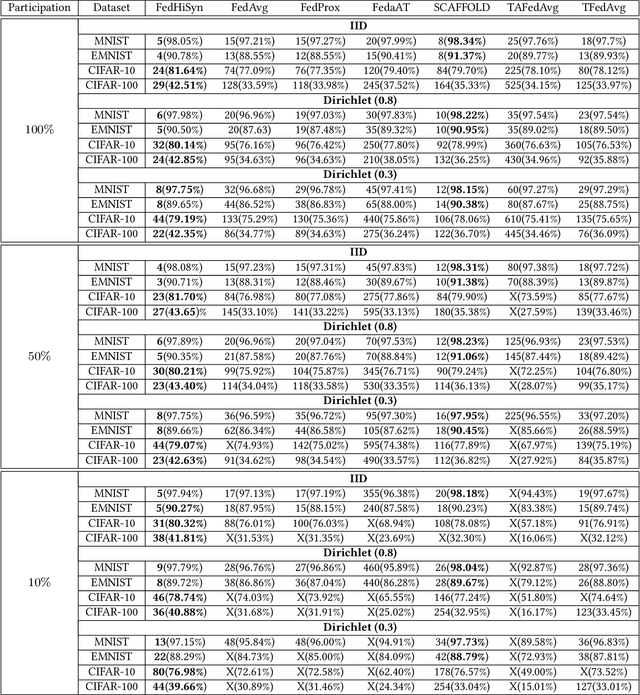
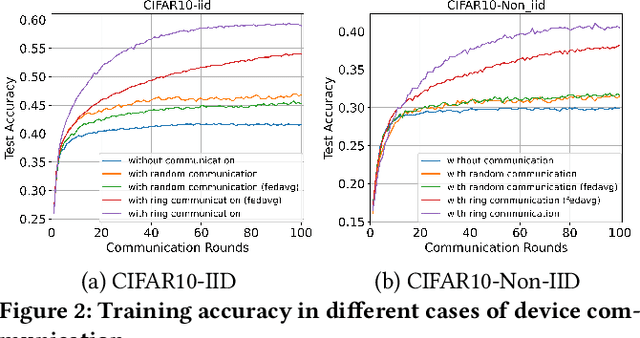
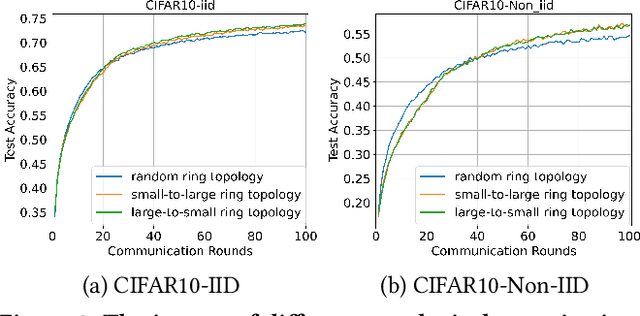
Federated Learning (FL) enables training a global model without sharing the decentralized raw data stored on multiple devices to protect data privacy. Due to the diverse capacity of the devices, FL frameworks struggle to tackle the problems of straggler effects and outdated models. In addition, the data heterogeneity incurs severe accuracy degradation of the global model in the FL training process. To address aforementioned issues, we propose a hierarchical synchronous FL framework, i.e., FedHiSyn. FedHiSyn first clusters all available devices into a small number of categories based on their computing capacity. After a certain interval of local training, the models trained in different categories are simultaneously uploaded to a central server. Within a single category, the devices communicate the local updated model weights to each other based on a ring topology. As the efficiency of training in the ring topology prefers devices with homogeneous resources, the classification based on the computing capacity mitigates the impact of straggler effects. Besides, the combination of the synchronous update of multiple categories and the device communication within a single category help address the data heterogeneity issue while achieving high accuracy. We evaluate the proposed framework based on MNIST, EMNIST, CIFAR10 and CIFAR100 datasets and diverse heterogeneous settings of devices. Experimental results show that FedHiSyn outperforms six baseline methods, e.g., FedAvg, SCAFFOLD, and FedAT, in terms of training accuracy and efficiency.
Failure Prediction in Production Line Based on Federated Learning: An Empirical Study
Jan 25, 2021



Data protection across organizations is limiting the application of centralized learning (CL) techniques. Federated learning (FL) enables multiple participants to build a learning model without sharing data. Nevertheless, there are very few research works on FL in intelligent manufacturing. This paper presents the results of an empirical study on failure prediction in the production line based on FL. This paper (1) designs Federated Support Vector Machine (FedSVM) and Federated Random Forest (FedRF) algorithms for the horizontal FL and vertical FL scenarios, respectively; (2) proposes an experiment process for evaluating the effectiveness between the FL and CL algorithms; (3) finds that the performance of FL and CL are not significantly different on the global testing data, on the random partial testing data, and on the estimated unknown Bosch data, respectively. The fact that the testing data is heterogeneous enhances our findings. Our study reveals that FL can replace CL for failure prediction.
A Systematic Literature Review on Federated Learning: From A Model Quality Perspective
Dec 01, 2020



As an emerging technique, Federated Learning (FL) can jointly train a global model with the data remaining locally, which effectively solves the problem of data privacy protection through the encryption mechanism. The clients train their local model, and the server aggregates models until convergence. In this process, the server uses an incentive mechanism to encourage clients to contribute high-quality and large-volume data to improve the global model. Although some works have applied FL to the Internet of Things (IoT), medicine, manufacturing, etc., the application of FL is still in its infancy, and many related issues need to be solved. Improving the quality of FL models is one of the current research hotspots and challenging tasks. This paper systematically reviews and objectively analyzes the approaches to improving the quality of FL models. We are also interested in the research and application trends of FL and the effect comparison between FL and non-FL because the practitioners usually worry that achieving privacy protection needs compromising learning quality. We use a systematic review method to analyze 147 latest articles related to FL. This review provides useful information and insights to both academia and practitioners from the industry. We investigate research questions about academic research and industrial application trends of FL, essential factors affecting the quality of FL models, and compare FL and non-FL algorithms in terms of learning quality. Based on our review's conclusion, we give some suggestions for improving the FL model quality. Finally, we propose an FL application framework for practitioners.