 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuy Tennenholtz
DynaMITE-RL: A Dynamic Model for Improved Temporal Meta-Reinforcement Learning
Feb 25, 2024
We introduce DynaMITE-RL, a meta-reinforcement learning (meta-RL) approach to approximate inference in environments where the latent state evolves at varying rates. We model episode sessions - parts of the episode where the latent state is fixed - and propose three key modifications to existing meta-RL methods: consistency of latent information within sessions, session masking, and prior latent conditioning. We demonstrate the importance of these modifications in various domains, ranging from discrete Gridworld environments to continuous-control and simulated robot assistive tasks, demonstrating that DynaMITE-RL significantly outperforms state-of-the-art baselines in sample efficiency and inference returns.
Ever Evolving Evaluator (EV3): Towards Flexible and Reliable Meta-Optimization for Knowledge Distillation
Oct 29, 2023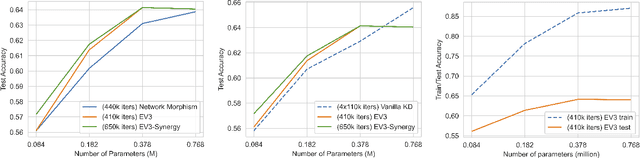
We introduce EV3, a novel meta-optimization framework designed to efficiently train scalable machine learning models through an intuitive explore-assess-adapt protocol. In each iteration of EV3, we explore various model parameter updates, assess them using pertinent evaluation methods, and adapt the model based on the optimal updates and previous progress history. EV3 offers substantial flexibility without imposing stringent constraints like differentiability on the key objectives relevant to the tasks of interest. Moreover, this protocol welcomes updates with biased gradients and allows for the use of a diversity of losses and optimizers. Additionally, in scenarios with multiple objectives, it can be used to dynamically prioritize tasks. With inspiration drawn from evolutionary algorithms, meta-learning, and neural architecture search, we investigate an application of EV3 to knowledge distillation. Our experimental results illustrate EV3's capability to safely explore model spaces, while hinting at its potential applicability across numerous domains due to its inherent flexibility and adaptability.
Factual and Personalized Recommendations using Language Models and Reinforcement Learning
Oct 09, 2023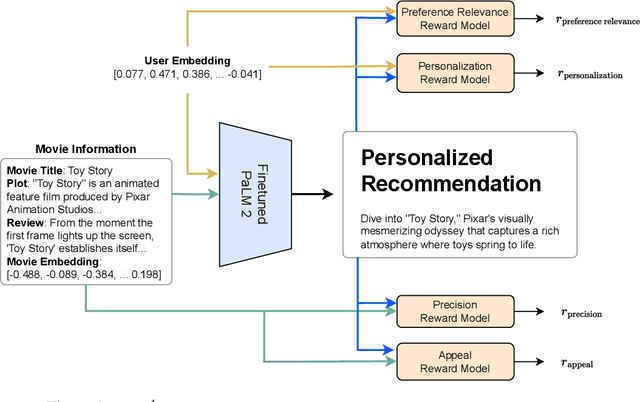
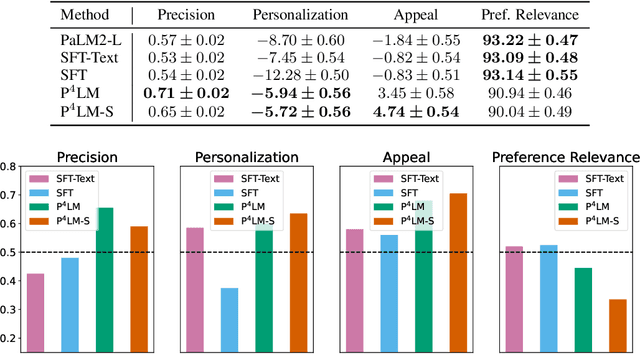

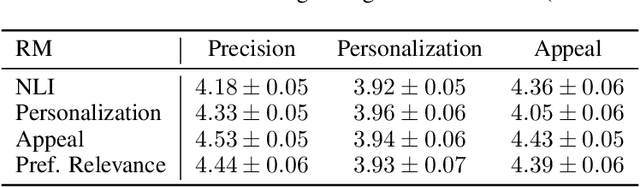
Recommender systems (RSs) play a central role in connecting users to content, products, and services, matching candidate items to users based on their preferences. While traditional RSs rely on implicit user feedback signals, conversational RSs interact with users in natural language. In this work, we develop a comPelling, Precise, Personalized, Preference-relevant language model (P4LM) that recommends items to users while putting emphasis on explaining item characteristics and their relevance. P4LM uses the embedding space representation of a user's preferences to generate compelling responses that are factually-grounded and relevant w.r.t. the user's preferences. Moreover, we develop a joint reward function that measures precision, appeal, and personalization, which we use as AI-based feedback in a reinforcement learning-based language model framework. Using the MovieLens 25M dataset, we demonstrate that P4LM delivers compelling, personalized movie narratives to users.
Demystifying Embedding Spaces using Large Language Models
Oct 06, 2023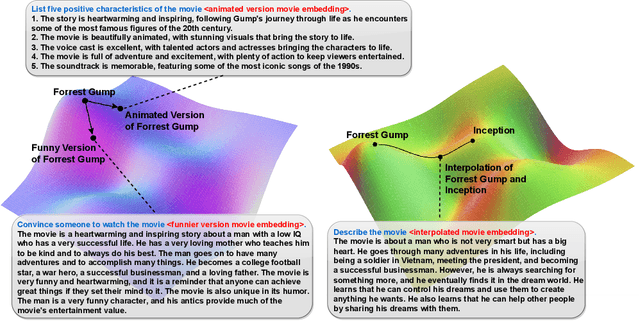
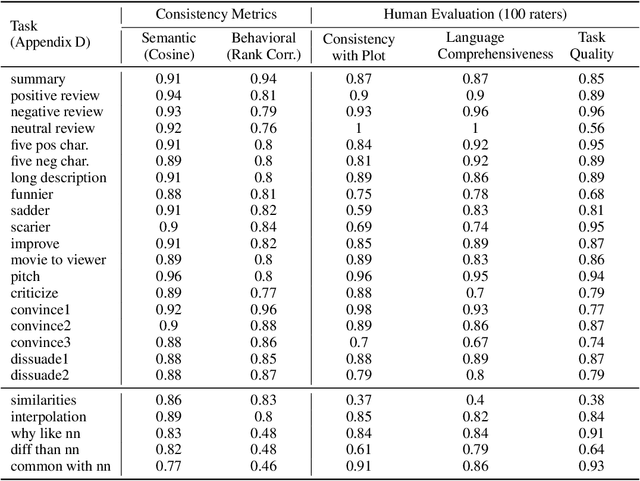
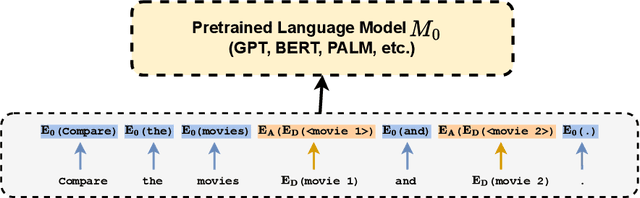
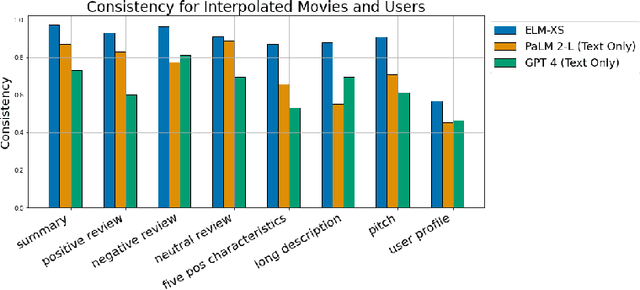
Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.
Modeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 22, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
A Convex Relaxation Approach to Bayesian Regret Minimization in Offline Bandits
Jun 02, 2023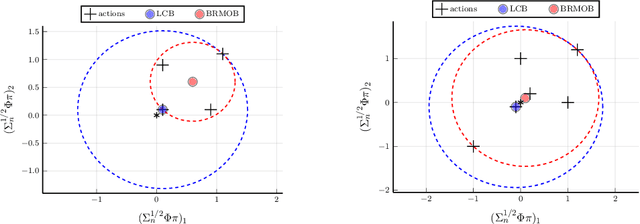



Algorithms for offline bandits must optimize decisions in uncertain environments using only offline data. A compelling and increasingly popular objective in offline bandits is to learn a policy which achieves low Bayesian regret with high confidence. An appealing approach to this problem, inspired by recent offline reinforcement learning results, is to maximize a form of lower confidence bound (LCB). This paper proposes a new approach that directly minimizes upper bounds on Bayesian regret using efficient conic optimization solvers. Our bounds build on connections among Bayesian regret, Value-at-Risk (VaR), and chance-constrained optimization. Compared to prior work, our algorithm attains superior theoretical offline regret bounds and better results in numerical simulations. Finally, we provide some evidence that popular LCB-style algorithms may be unsuitable for minimizing Bayesian regret in offline bandits.
Delphic Offline Reinforcement Learning under Nonidentifiable Hidden Confounding
Jun 01, 2023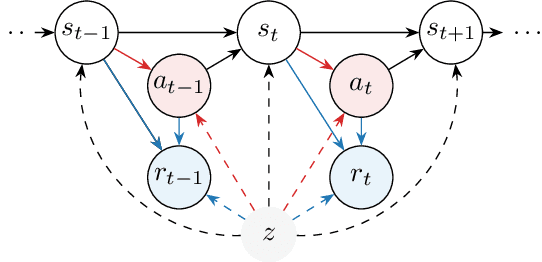
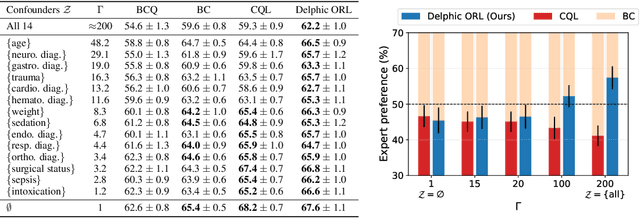
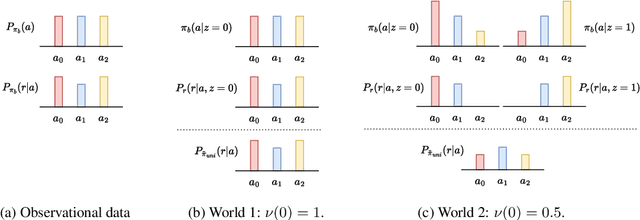
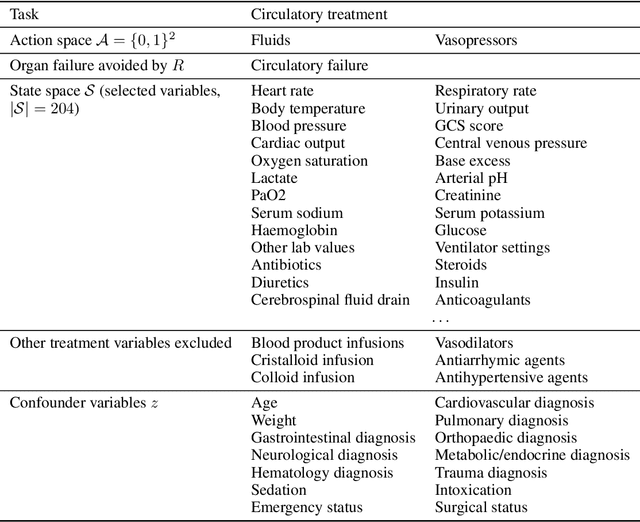
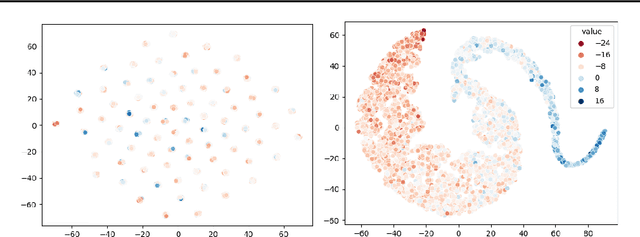
A prominent challenge of offline reinforcement learning (RL) is the issue of hidden confounding: unobserved variables may influence both the actions taken by the agent and the observed outcomes. Hidden confounding can compromise the validity of any causal conclusion drawn from data and presents a major obstacle to effective offline RL. In the present paper, we tackle the problem of hidden confounding in the nonidentifiable setting. We propose a definition of uncertainty due to hidden confounding bias, termed delphic uncertainty, which uses variation over world models compatible with the observations, and differentiate it from the well-known epistemic and aleatoric uncertainties. We derive a practical method for estimating the three types of uncertainties, and construct a pessimistic offline RL algorithm to account for them. Our method does not assume identifiability of the unobserved confounders, and attempts to reduce the amount of confounding bias. We demonstrate through extensive experiments and ablations the efficacy of our approach on a sepsis management benchmark, as well as on electronic health records. Our results suggest that nonidentifiable hidden confounding bias can be mitigated to improve offline RL solutions in practice.
Representation-Driven Reinforcement Learning
May 31, 2023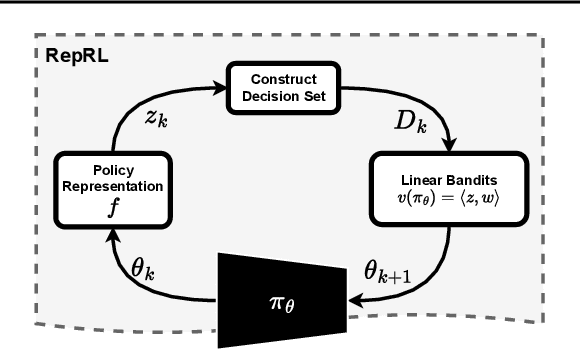
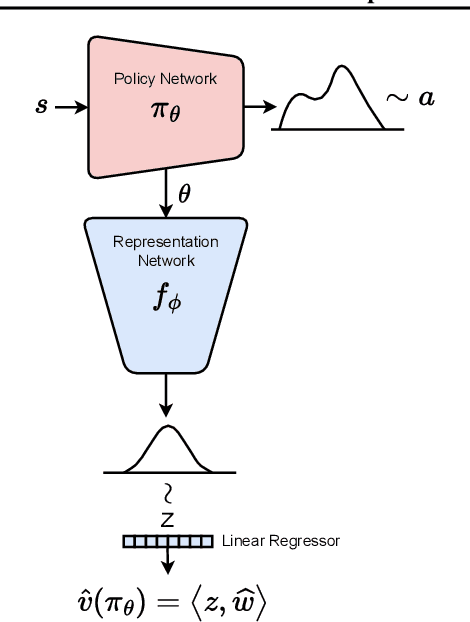
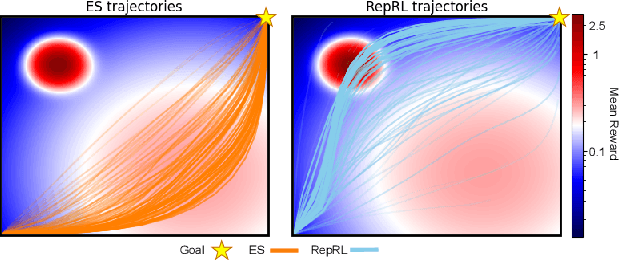
We present a representation-driven framework for reinforcement learning. By representing policies as estimates of their expected values, we leverage techniques from contextual bandits to guide exploration and exploitation. Particularly, embedding a policy network into a linear feature space allows us to reframe the exploration-exploitation problem as a representation-exploitation problem, where good policy representations enable optimal exploration. We demonstrate the effectiveness of this framework through its application to evolutionary and policy gradient-based approaches, leading to significantly improved performance compared to traditional methods. Our framework provides a new perspective on reinforcement learning, highlighting the importance of policy representation in determining optimal exploration-exploitation strategies.
Reinforcement Learning with History-Dependent Dynamic Contexts
Feb 04, 2023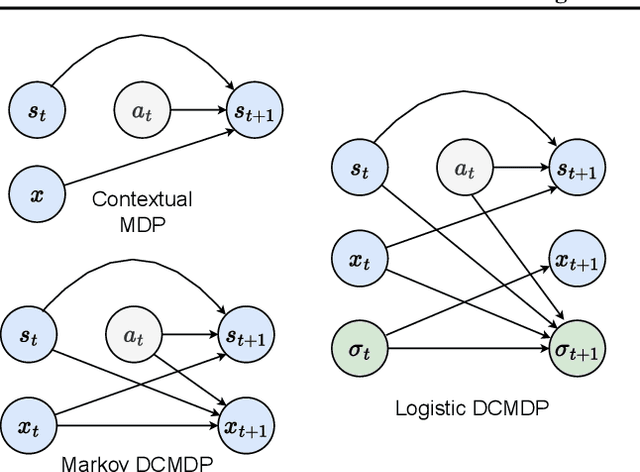
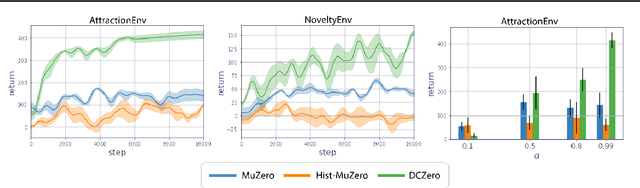
We introduce Dynamic Contextual Markov Decision Processes (DCMDPs), a novel reinforcement learning framework for history-dependent environments that generalizes the contextual MDP framework to handle non-Markov environments, where contexts change over time. We consider special cases of the model, with a focus on logistic DCMDPs, which break the exponential dependence on history length by leveraging aggregation functions to determine context transitions. This special structure allows us to derive an upper-confidence-bound style algorithm for which we establish regret bounds. Motivated by our theoretical results, we introduce a practical model-based algorithm for logistic DCMDPs that plans in a latent space and uses optimism over history-dependent features. We demonstrate the efficacy of our approach on a recommendation task (using MovieLens data) where user behavior dynamics evolve in response to recommendations.
Reinforcement Learning with a Terminator
May 30, 2022



We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.