 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanna Behnke
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021
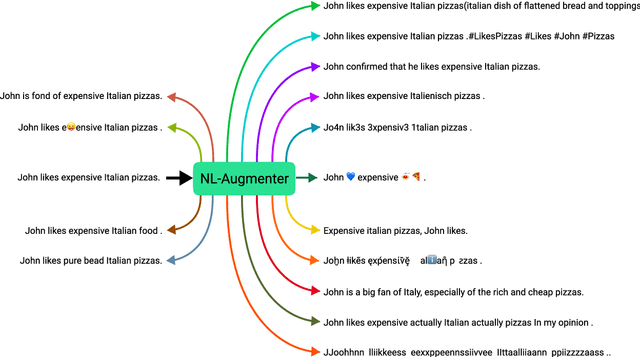
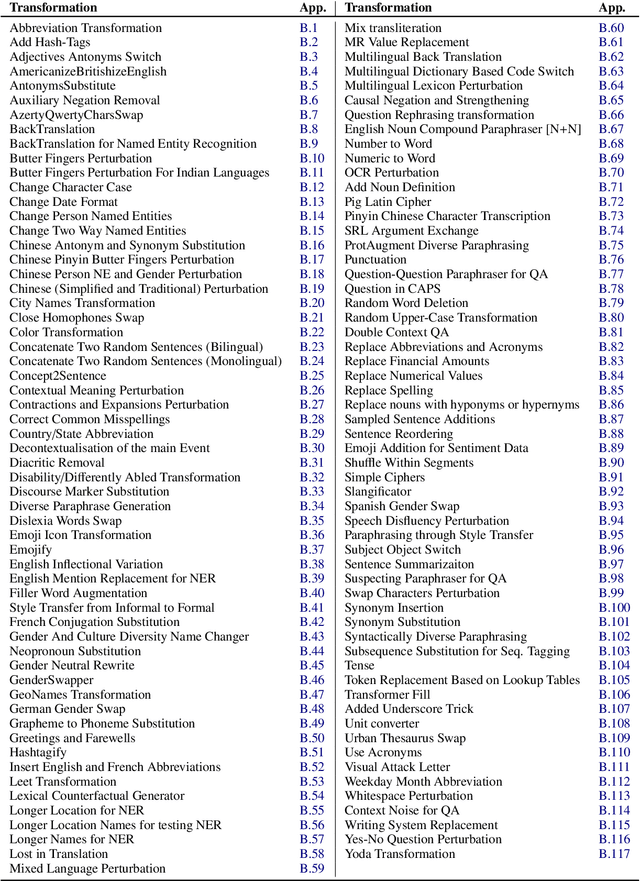

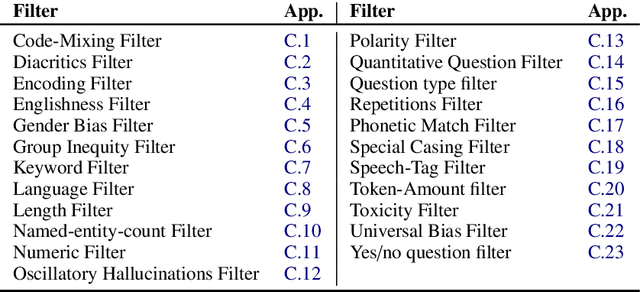
Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
DeepTitle -- Leveraging BERT to generate Search Engine Optimized Headlines
Jul 22, 2021



Automated headline generation for online news articles is not a trivial task - machine generated titles need to be grammatically correct, informative, capture attention and generate search traffic without being "click baits" or "fake news". In this paper we showcase how a pre-trained language model can be leveraged to create an abstractive news headline generator for German language. We incorporate state of the art fine-tuning techniques for abstractive text summarization, i.e. we use different optimizers for the encoder and decoder where the former is pre-trained and the latter is trained from scratch. We modify the headline generation to incorporate frequently sought keywords relevant for search engine optimization. We conduct experiments on a German news data set and achieve a ROUGE-L-gram F-score of 40.02. Furthermore, we address the limitations of ROUGE for measuring the quality of text summarization by introducing a sentence similarity metric and human evaluation.