 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKalpesh Krishna
GEE! Grammar Error Explanation with Large Language Models
Nov 16, 2023
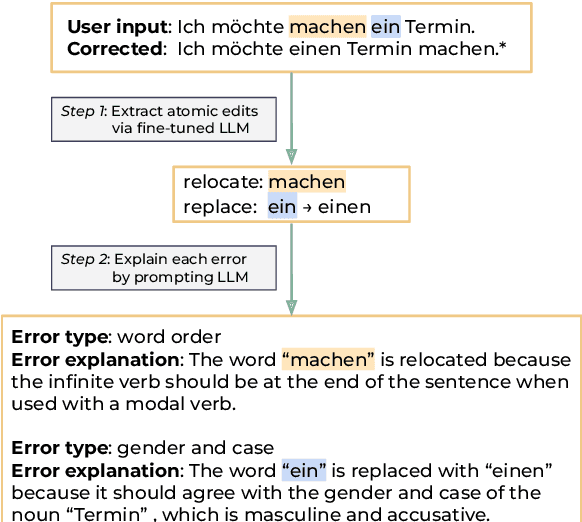


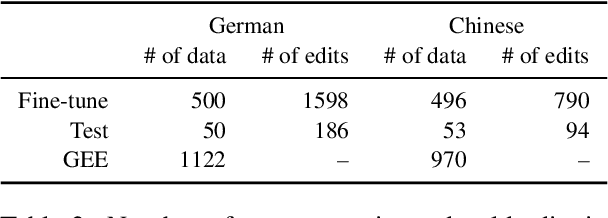
Grammatical error correction tools are effective at correcting grammatical errors in users' input sentences but do not provide users with \textit{natural language} explanations about their errors. Such explanations are essential for helping users learn the language by gaining a deeper understanding of its grammatical rules (DeKeyser, 2003; Ellis et al., 2006). To address this gap, we propose the task of grammar error explanation, where a system needs to provide one-sentence explanations for each grammatical error in a pair of erroneous and corrected sentences. We analyze the capability of GPT-4 in grammar error explanation, and find that it only produces explanations for 60.2% of the errors using one-shot prompting. To improve upon this performance, we develop a two-step pipeline that leverages fine-tuned and prompted large language models to perform structured atomic token edit extraction, followed by prompting GPT-4 to generate explanations. We evaluate our pipeline on German and Chinese grammar error correction data sampled from language learners with a wide range of proficiency levels. Human evaluation reveals that our pipeline produces 93.9% and 98.0% correct explanations for German and Chinese data, respectively. To encourage further research in this area, we will open-source our data and code.
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
May 23, 2023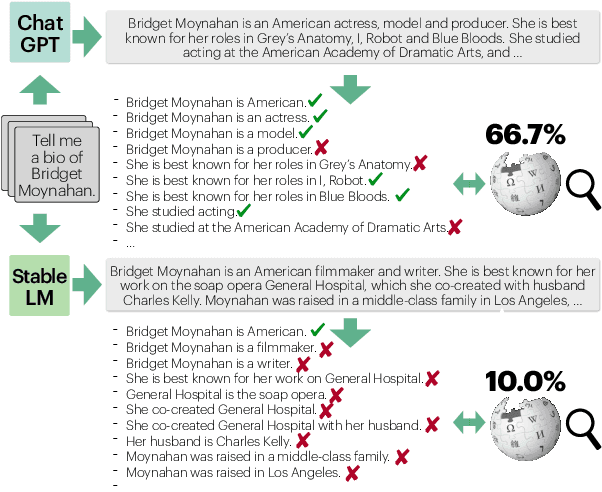

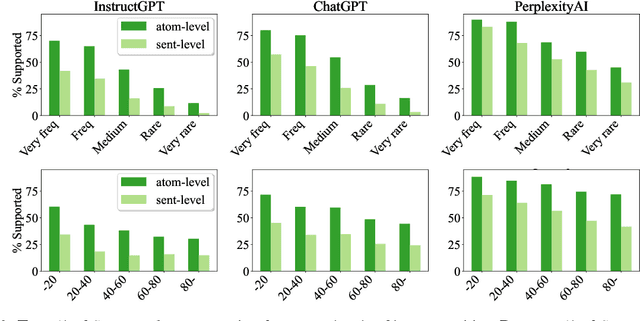
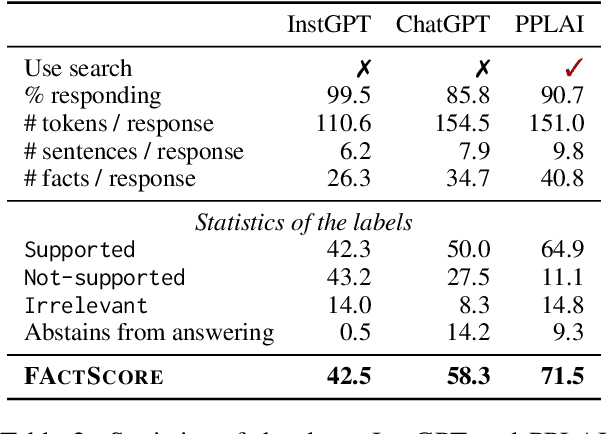
Evaluating the factuality of long-form text generated by large language models (LMs) is non-trivial because (1) generations often contain a mixture of supported and unsupported pieces of information, making binary judgments of quality inadequate, and (2) human evaluation is time-consuming and costly. In this paper, we introduce FActScore (Factual precision in Atomicity Score), a new evaluation that breaks a generation into a series of atomic facts and computes the percentage of atomic facts supported by a reliable knowledge source. We conduct an extensive human evaluation to obtain FActScores of people biographies generated by several state-of-the-art commercial LMs -- InstructGPT, ChatGPT, and the retrieval-augmented PerplexityAI -- and report new analysis demonstrating the need for such a fine-grained score (e.g., ChatGPT only achieves 58%). Since human evaluation is costly, we also introduce an automated model that estimates FActScore, using retrieval and a strong language model, with less than a 2% error rate. Finally, we use this automated metric to evaluate 6,500 generations from a new set of 13 recent LMs that would have cost $26K if evaluated by humans, with various findings: GPT-4 and ChatGPT are more factual than public models, and Vicuna and Alpaca are some of the best public models.
Paraphrasing evades detectors of AI-generated text, but retrieval is an effective defense
Mar 23, 2023
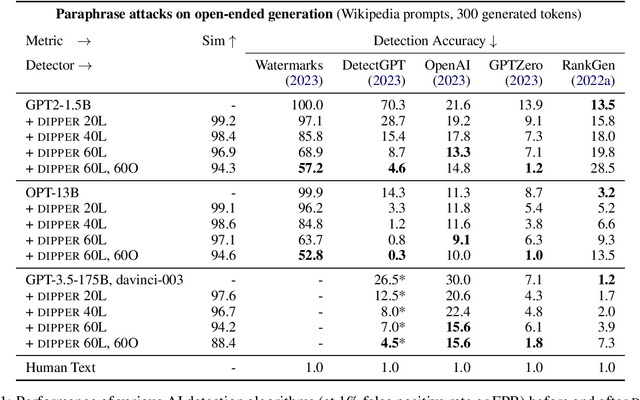
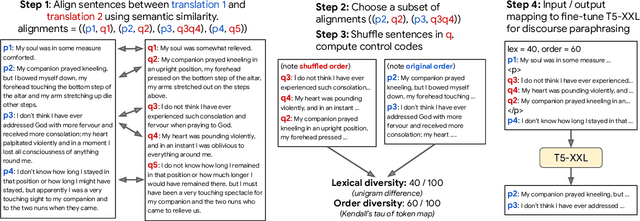
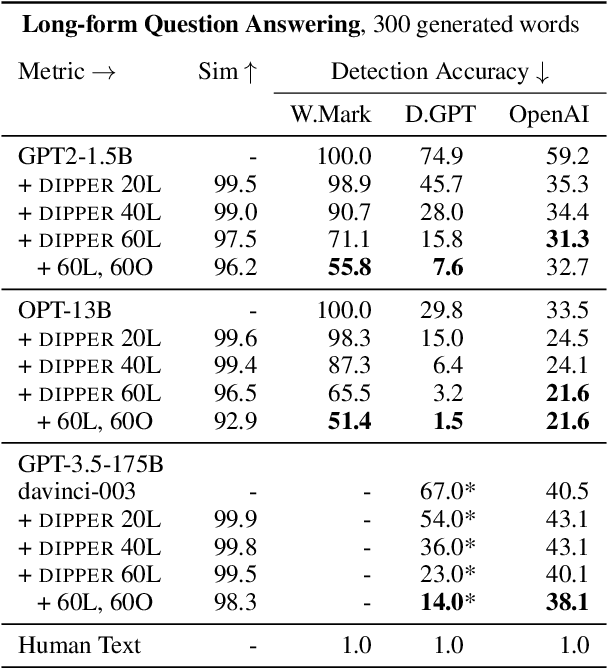
To detect the deployment of large language models for malicious use cases (e.g., fake content creation or academic plagiarism), several approaches have recently been proposed for identifying AI-generated text via watermarks or statistical irregularities. How robust are these detection algorithms to paraphrases of AI-generated text? To stress test these detectors, we first train an 11B parameter paraphrase generation model (DIPPER) that can paraphrase paragraphs, optionally leveraging surrounding text (e.g., user-written prompts) as context. DIPPER also uses scalar knobs to control the amount of lexical diversity and reordering in the paraphrases. Paraphrasing text generated by three large language models (including GPT3.5-davinci-003) with DIPPER successfully evades several detectors, including watermarking, GPTZero, DetectGPT, and OpenAI's text classifier. For example, DIPPER drops the detection accuracy of DetectGPT from 70.3% to 4.6% (at a constant false positive rate of 1%), without appreciably modifying the input semantics. To increase the robustness of AI-generated text detection to paraphrase attacks, we introduce a simple defense that relies on retrieving semantically-similar generations and must be maintained by a language model API provider. Given a candidate text, our algorithm searches a database of sequences previously generated by the API, looking for sequences that match the candidate text within a certain threshold. We empirically verify our defense using a database of 15M generations from a fine-tuned T5-XXL model and find that it can detect 80% to 97% of paraphrased generations across different settings, while only classifying 1% of human-written sequences as AI-generated. We will open source our code, model and data for future research.
On the Risks of Stealing the Decoding Algorithms of Language Models
Mar 09, 2023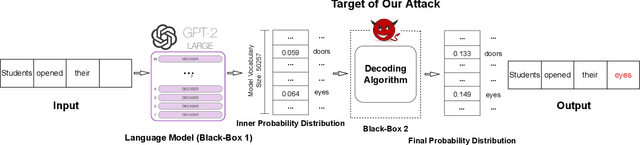

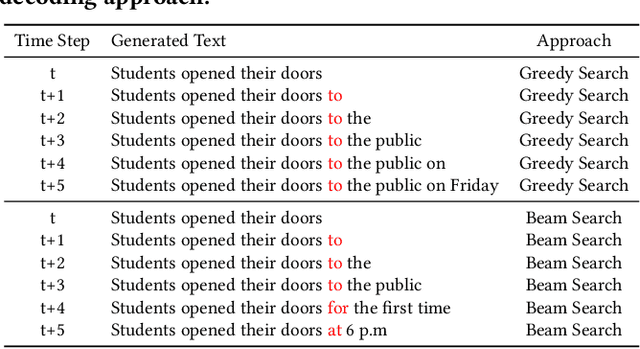
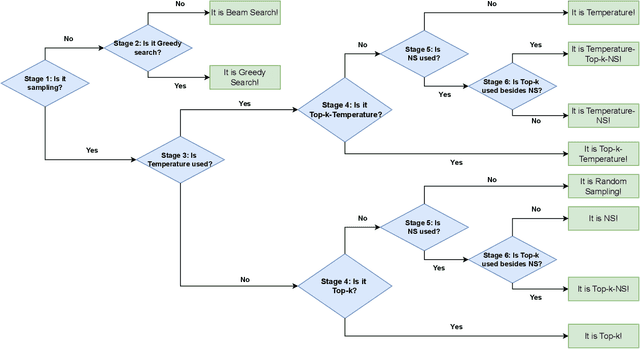
A key component of generating text from modern language models (LM) is the selection and tuning of decoding algorithms. These algorithms determine how to generate text from the internal probability distribution generated by the LM. The process of choosing a decoding algorithm and tuning its hyperparameters takes significant time, manual effort, and computation, and it also requires extensive human evaluation. Therefore, the identity and hyperparameters of such decoding algorithms are considered to be extremely valuable to their owners. In this work, we show, for the first time, that an adversary with typical API access to an LM can steal the type and hyperparameters of its decoding algorithms at very low monetary costs. Our attack is effective against popular LMs used in text generation APIs, including GPT-2 and GPT-3. We demonstrate the feasibility of stealing such information with only a few dollars, e.g., $\$0.8$, $\$1$, $\$4$, and $\$40$ for the four versions of GPT-3.
LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization
Jan 30, 2023
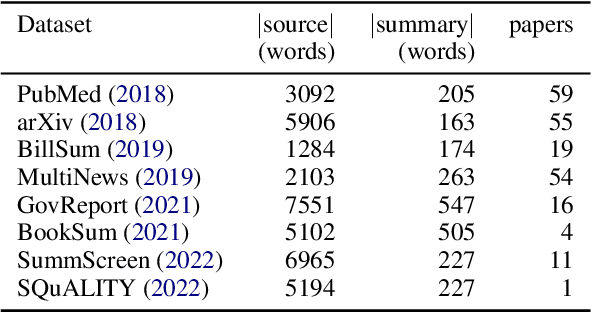

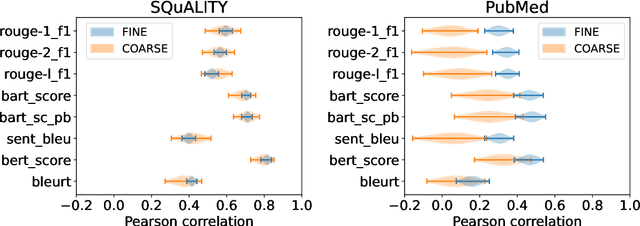
While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall's tau using 50% judgments). We release our human judgments, annotation templates, and our software as a Python library for future research.
Exploring Document-Level Literary Machine Translation with Parallel Paragraphs from World Literature
Oct 25, 2022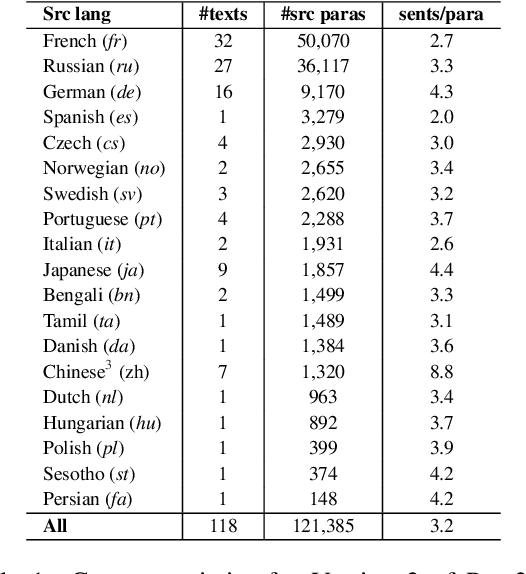
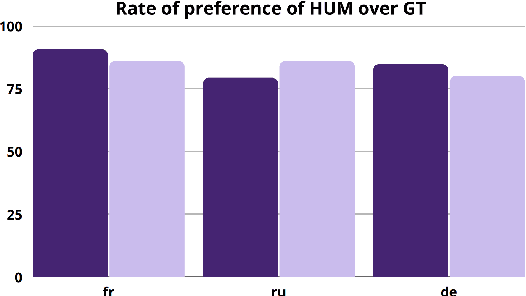

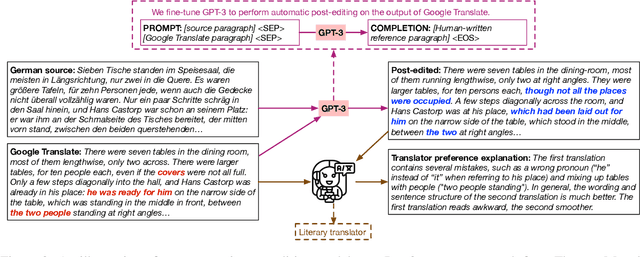
Literary translation is a culturally significant task, but it is bottlenecked by the small number of qualified literary translators relative to the many untranslated works published around the world. Machine translation (MT) holds potential to complement the work of human translators by improving both training procedures and their overall efficiency. Literary translation is less constrained than more traditional MT settings since translators must balance meaning equivalence, readability, and critical interpretability in the target language. This property, along with the complex discourse-level context present in literary texts, also makes literary MT more challenging to computationally model and evaluate. To explore this task, we collect a dataset (Par3) of non-English language novels in the public domain, each aligned at the paragraph level to both human and automatic English translations. Using Par3, we discover that expert literary translators prefer reference human translations over machine-translated paragraphs at a rate of 84%, while state-of-the-art automatic MT metrics do not correlate with those preferences. The experts note that MT outputs contain not only mistranslations, but also discourse-disrupting errors and stylistic inconsistencies. To address these problems, we train a post-editing model whose output is preferred over normal MT output at a rate of 69% by experts. We publicly release Par3 at https://github.com/katherinethai/par3/ to spur future research into literary MT.
ezCoref: Towards Unifying Annotation Guidelines for Coreference Resolution
Oct 13, 2022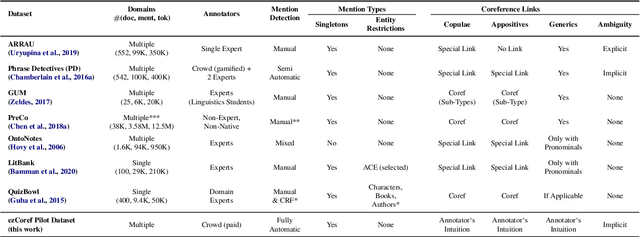
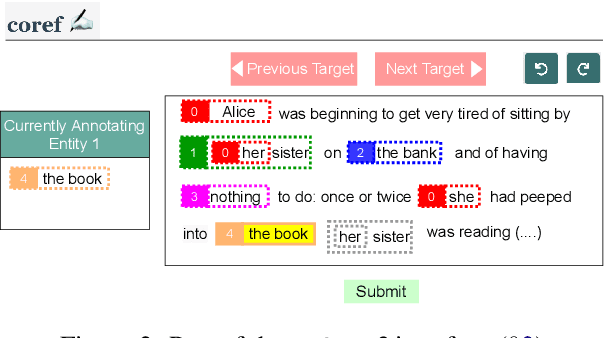


Large-scale, high-quality corpora are critical for advancing research in coreference resolution. However, existing datasets vary in their definition of coreferences and have been collected via complex and lengthy guidelines that are curated for linguistic experts. These concerns have sparked a growing interest among researchers to curate a unified set of guidelines suitable for annotators with various backgrounds. In this work, we develop a crowdsourcing-friendly coreference annotation methodology, ezCoref, consisting of an annotation tool and an interactive tutorial. We use ezCoref to re-annotate 240 passages from seven existing English coreference datasets (spanning fiction, news, and multiple other domains) while teaching annotators only cases that are treated similarly across these datasets. Surprisingly, we find that reasonable quality annotations were already achievable (>90% agreement between the crowd and expert annotations) even without extensive training. On carefully analyzing the remaining disagreements, we identify the presence of linguistic cases that our annotators unanimously agree upon but lack unified treatments (e.g., generic pronouns, appositives) in existing datasets. We propose the research community should revisit these phenomena when curating future unified annotation guidelines.
RankGen: Improving Text Generation with Large Ranking Models
May 19, 2022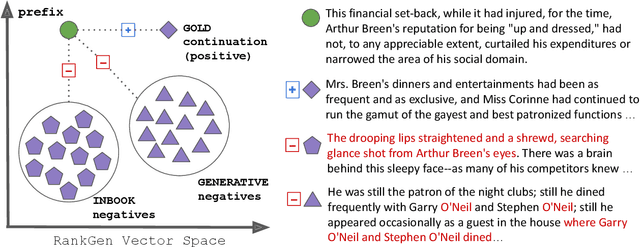
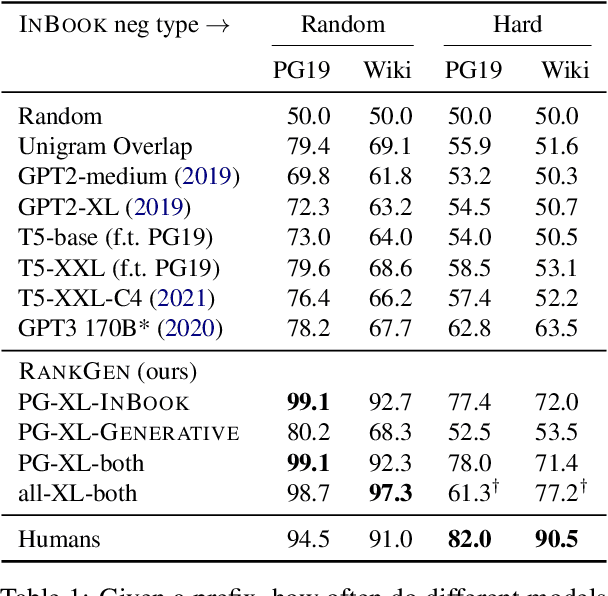
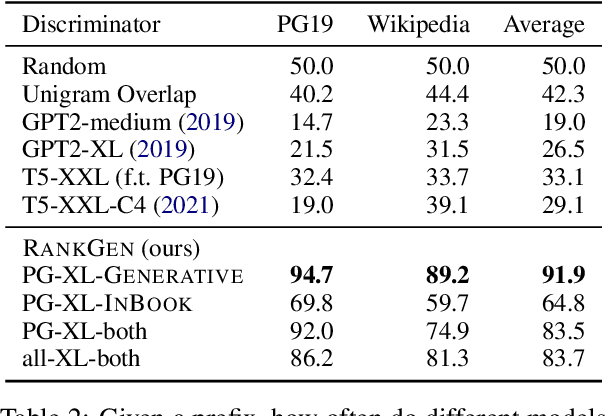
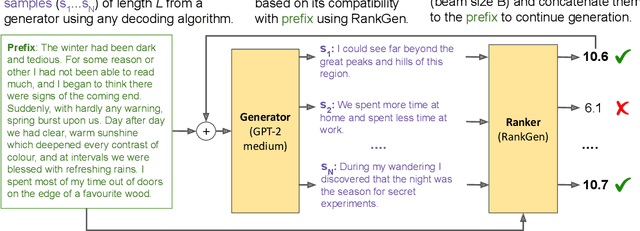
Given an input sequence (or prefix), modern language models often assign high probabilities to output sequences that are repetitive, incoherent, or irrelevant to the prefix; as such, model-generated text also contains such artifacts. To address these issues, we present RankGen, an encoder model (1.2B parameters) that scores model generations given a prefix. RankGen can be flexibly incorporated as a scoring function in beam search and used to decode from any pretrained language model. We train RankGen using large-scale contrastive learning to map a prefix close to the ground-truth sequence that follows it and far away from two types of negatives: (1) random sequences from the same document as the prefix, and, which discourage topically-similar but irrelevant generations; (2) sequences generated from a large language model conditioned on the prefix, which discourage repetition and hallucination. Experiments across four different language models (345M-11B parameters) and two domains show that RankGen significantly outperforms decoding algorithms like nucleus, top-k, and typical sampling on both automatic metrics (85.0 vs 77.3 MAUVE) as well as human evaluations with English writers (74.5% human preference over nucleus sampling). Analysis reveals that RankGen outputs are more relevant to the prefix and improve continuity and coherence compared to baselines. We open source our model checkpoints, code, and human preferences with detailed explanations for future research.
RELIC: Retrieving Evidence for Literary Claims
Mar 18, 2022


Humanities scholars commonly provide evidence for claims that they make about a work of literature (e.g., a novel) in the form of quotations from the work. We collect a large-scale dataset (RELiC) of 78K literary quotations and surrounding critical analysis and use it to formulate the novel task of literary evidence retrieval, in which models are given an excerpt of literary analysis surrounding a masked quotation and asked to retrieve the quoted passage from the set of all passages in the work. Solving this retrieval task requires a deep understanding of complex literary and linguistic phenomena, which proves challenging to methods that overwhelmingly rely on lexical and semantic similarity matching. We implement a RoBERTa-based dense passage retriever for this task that outperforms existing pretrained information retrieval baselines; however, experiments and analysis by human domain experts indicate that there is substantial room for improvement over our dense retriever.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021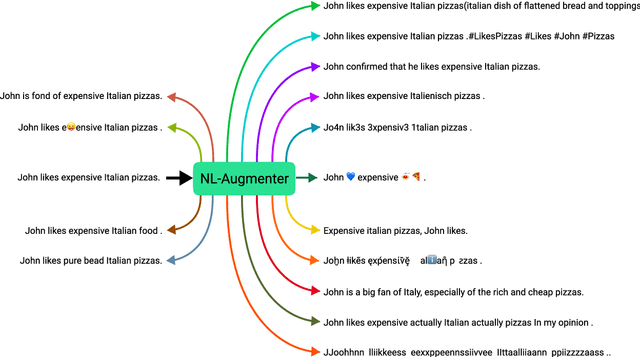
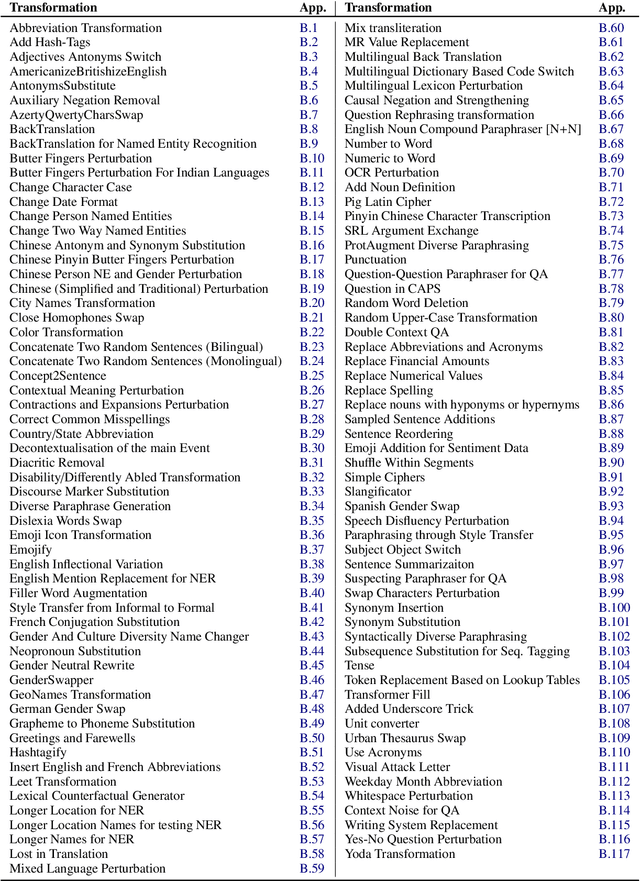

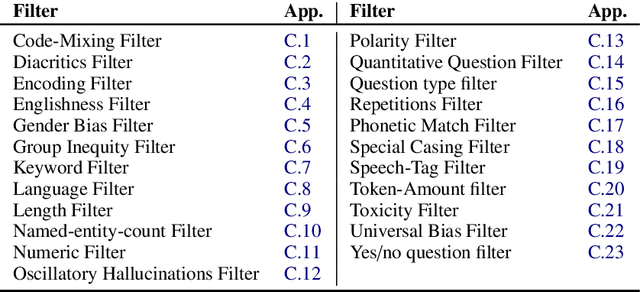
Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).