 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaoyuan Shi
VisionGraph: Leveraging Large Multimodal Models for Graph Theory Problems in Visual Context
May 08, 2024




Large Multimodal Models (LMMs) have achieved impressive success in visual understanding and reasoning, remarkably improving the performance of mathematical reasoning in a visual context. Yet, a challenging type of visual math lies in the multimodal graph theory problem, which demands that LMMs understand the graphical structures accurately and perform multi-step reasoning on the visual graph. Additionally, exploring multimodal graph theory problems will lead to more effective strategies in fields like biology, transportation, and robotics planning. To step forward in this direction, we are the first to design a benchmark named VisionGraph, used to explore the capabilities of advanced LMMs in solving multimodal graph theory problems. It encompasses eight complex graph problem tasks, from connectivity to shortest path problems. Subsequently, we present a Description-Program-Reasoning (DPR) chain to enhance the logical accuracy of reasoning processes through graphical structure description generation and algorithm-aware multi-step reasoning. Our extensive study shows that 1) GPT-4V outperforms Gemini Pro in multi-step graph reasoning; 2) All LMMs exhibit inferior perception accuracy for graphical structures, whether in zero/few-shot settings or with supervised fine-tuning (SFT), which further affects problem-solving performance; 3) DPR significantly improves the multi-step graph reasoning capabilities of LMMs and the GPT-4V (DPR) agent achieves SOTA performance.
Cognitive Visual-Language Mapper: Advancing Multimodal Comprehension with Enhanced Visual Knowledge Alignment
Feb 21, 2024Evaluating and Rethinking the current landscape of Large Multimodal Models (LMMs), we observe that widely-used visual-language projection approaches (e.g., Q-former or MLP) focus on the alignment of image-text descriptions yet ignore the visual knowledge-dimension alignment, i.e., connecting visuals to their relevant knowledge. Visual knowledge plays a significant role in analyzing, inferring, and interpreting information from visuals, helping improve the accuracy of answers to knowledge-based visual questions. In this paper, we mainly explore improving LMMs with visual-language knowledge alignment, especially aimed at challenging knowledge-based visual question answering (VQA). To this end, we present a Cognitive Visual-Language Mapper (CVLM), which contains a pretrained Visual Knowledge Aligner (VKA) and a Fine-grained Knowledge Adapter (FKA) used in the multimodal instruction tuning stage. Specifically, we design the VKA based on the interaction between a small language model and a visual encoder, training it on collected image-knowledge pairs to achieve visual knowledge acquisition and projection. FKA is employed to distill the fine-grained visual knowledge of an image and inject it into Large Language Models (LLMs). We conduct extensive experiments on knowledge-based VQA benchmarks and experimental results show that CVLM significantly improves the performance of LMMs on knowledge-based VQA (average gain by 5.0%). Ablation studies also verify the effectiveness of VKA and FKA, respectively.
Toward Moiré-Free and Detail-Preserving Demosaicking
May 15, 2023
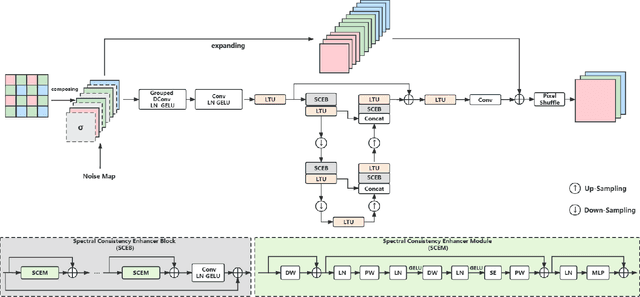


3D convolutions are commonly employed by demosaicking neural models, in the same way as solving other image restoration problems. Counter-intuitively, we show that 3D convolutions implicitly impede the RGB color spectra from exchanging complementary information, resulting in spectral-inconsistent inference of the local spatial high frequency components. As a consequence, shallow 3D convolution networks suffer the Moir\'e artifacts, but deep 3D convolutions cause over-smoothness. We analyze the fundamental difference between demosaicking and other problems that predict lost pixels between available ones (e.g., super-resolution reconstruction), and present the underlying reasons for the confliction between Moir\'e-free and detail-preserving. From the new perspective, our work decouples the common standard convolution procedure to spectral and spatial feature aggregations, which allow strengthening global communication in the spectral dimension while respecting local contrast in the spatial dimension. We apply our demosaicking model to two tasks: Joint Demosaicking-Denoising and Independently Demosaicking. In both applications, our model substantially alleviates artifacts such as Moir\'e and over-smoothness at similar or lower computational cost to currently top-performing models, as validated by diverse evaluations. Source code will be released along with paper publication.