 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYunxin Li
VisionGraph: Leveraging Large Multimodal Models for Graph Theory Problems in Visual Context
May 08, 2024
Large Multimodal Models (LMMs) have achieved impressive success in visual understanding and reasoning, remarkably improving the performance of mathematical reasoning in a visual context. Yet, a challenging type of visual math lies in the multimodal graph theory problem, which demands that LMMs understand the graphical structures accurately and perform multi-step reasoning on the visual graph. Additionally, exploring multimodal graph theory problems will lead to more effective strategies in fields like biology, transportation, and robotics planning. To step forward in this direction, we are the first to design a benchmark named VisionGraph, used to explore the capabilities of advanced LMMs in solving multimodal graph theory problems. It encompasses eight complex graph problem tasks, from connectivity to shortest path problems. Subsequently, we present a Description-Program-Reasoning (DPR) chain to enhance the logical accuracy of reasoning processes through graphical structure description generation and algorithm-aware multi-step reasoning. Our extensive study shows that 1) GPT-4V outperforms Gemini Pro in multi-step graph reasoning; 2) All LMMs exhibit inferior perception accuracy for graphical structures, whether in zero/few-shot settings or with supervised fine-tuning (SFT), which further affects problem-solving performance; 3) DPR significantly improves the multi-step graph reasoning capabilities of LMMs and the GPT-4V (DPR) agent achieves SOTA performance.
Cognitive Visual-Language Mapper: Advancing Multimodal Comprehension with Enhanced Visual Knowledge Alignment
Feb 21, 2024Evaluating and Rethinking the current landscape of Large Multimodal Models (LMMs), we observe that widely-used visual-language projection approaches (e.g., Q-former or MLP) focus on the alignment of image-text descriptions yet ignore the visual knowledge-dimension alignment, i.e., connecting visuals to their relevant knowledge. Visual knowledge plays a significant role in analyzing, inferring, and interpreting information from visuals, helping improve the accuracy of answers to knowledge-based visual questions. In this paper, we mainly explore improving LMMs with visual-language knowledge alignment, especially aimed at challenging knowledge-based visual question answering (VQA). To this end, we present a Cognitive Visual-Language Mapper (CVLM), which contains a pretrained Visual Knowledge Aligner (VKA) and a Fine-grained Knowledge Adapter (FKA) used in the multimodal instruction tuning stage. Specifically, we design the VKA based on the interaction between a small language model and a visual encoder, training it on collected image-knowledge pairs to achieve visual knowledge acquisition and projection. FKA is employed to distill the fine-grained visual knowledge of an image and inject it into Large Language Models (LLMs). We conduct extensive experiments on knowledge-based VQA benchmarks and experimental results show that CVLM significantly improves the performance of LMMs on knowledge-based VQA (average gain by 5.0%). Ablation studies also verify the effectiveness of VKA and FKA, respectively.
LLMs Meet Long Video: Advancing Long Video Comprehension with An Interactive Visual Adapter in LLMs
Feb 21, 2024Long video understanding is a significant and ongoing challenge in the intersection of multimedia and artificial intelligence. Employing large language models (LLMs) for comprehending video becomes an emerging and promising method. However, this approach incurs high computational costs due to the extensive array of video tokens, experiences reduced visual clarity as a consequence of token aggregation, and confronts challenges arising from irrelevant visual tokens while answering video-related questions. To alleviate these issues, we present an Interactive Visual Adapter (IVA) within LLMs, designed to enhance interaction with fine-grained visual elements. Specifically, we first transform long videos into temporal video tokens via leveraging a visual encoder alongside a pretrained causal transformer, then feed them into LLMs with the video instructions. Subsequently, we integrated IVA, which contains a lightweight temporal frame selector and a spatial feature interactor, within the internal blocks of LLMs to capture instruction-aware and fine-grained visual signals. Consequently, the proposed video-LLM facilitates a comprehensive understanding of long video content through appropriate long video modeling and precise visual interactions. We conducted extensive experiments on nine video understanding benchmarks and experimental results show that our interactive visual adapter significantly improves the performance of video LLMs on long video QA tasks. Ablation studies further verify the effectiveness of IVA in long and short video understandings.
A Multimodal In-Context Tuning Approach for E-Commerce Product Description Generation
Feb 21, 2024In this paper, we propose a new setting for generating product descriptions from images, augmented by marketing keywords. It leverages the combined power of visual and textual information to create descriptions that are more tailored to the unique features of products. For this setting, previous methods utilize visual and textual encoders to encode the image and keywords and employ a language model-based decoder to generate the product description. However, the generated description is often inaccurate and generic since same-category products have similar copy-writings, and optimizing the overall framework on large-scale samples makes models concentrate on common words yet ignore the product features. To alleviate the issue, we present a simple and effective Multimodal In-Context Tuning approach, named ModICT, which introduces a similar product sample as the reference and utilizes the in-context learning capability of language models to produce the description. During training, we keep the visual encoder and language model frozen, focusing on optimizing the modules responsible for creating multimodal in-context references and dynamic prompts. This approach preserves the language generation prowess of large language models (LLMs), facilitating a substantial increase in description diversity. To assess the effectiveness of ModICT across various language model scales and types, we collect data from three distinct product categories within the E-commerce domain. Extensive experiments demonstrate that ModICT significantly improves the accuracy (by up to 3.3% on Rouge-L) and diversity (by up to 9.4% on D-5) of generated results compared to conventional methods. Our findings underscore the potential of ModICT as a valuable tool for enhancing automatic generation of product descriptions in a wide range of applications.
Frame Structure and Protocol Design for Sensing-Assisted NR-V2X Communications
Dec 27, 2023The emergence of the fifth-generation (5G) New Radio (NR) technology has provided unprecedented opportunities for vehicle-to-everything (V2X) networks, enabling enhanced quality of services. However, high-mobility V2X networks require frequent handovers and acquiring accurate channel state information (CSI) necessitates the utilization of pilot signals, leading to increased overhead and reduced communication throughput. To address this challenge, integrated sensing and communications (ISAC) techniques have been employed at the base station (gNB) within vehicle-to-infrastructure (V2I) networks, aiming to minimize overhead and improve spectral efficiency. In this study, we propose novel frame structures that incorporate ISAC signals for three crucial stages in the NR-V2X system: initial access, connected mode, and beam failure and recovery. These new frame structures employ 75% fewer pilots and reduce reference signals by 43.24%, capitalizing on the sensing capability of ISAC signals. Through extensive link-level simulations, we demonstrate that our proposed approach enables faster beam establishment during initial access, higher throughput and more precise beam tracking in connected mode with reduced overhead, and expedited detection and recovery from beam failures. Furthermore, the numerical results obtained from our simulations showcase enhanced spectrum efficiency, improved communication performance and minimal overhead, validating the effectiveness of the proposed ISAC-based techniques in NR V2I networks.
Towards Vision Enhancing LLMs: Empowering Multimodal Knowledge Storage and Sharing in LLMs
Nov 27, 2023Recent advancements in multimodal large language models (MLLMs) have achieved significant multimodal generation capabilities, akin to GPT-4. These models predominantly map visual information into language representation space, leveraging the vast knowledge and powerful text generation abilities of LLMs to produce multimodal instruction-following responses. We could term this method as LLMs for Vision because of its employing LLMs for visual-language understanding, yet observe that these MLLMs neglect the potential of harnessing visual knowledge to enhance overall capabilities of LLMs, which could be regraded as Vision Enhancing LLMs. In this paper, we propose an approach called MKS2, aimed at enhancing LLMs through empowering Multimodal Knowledge Storage and Sharing in LLMs. Specifically, we introduce the Modular Visual Memory, a component integrated into the internal blocks of LLMs, designed to store open-world visual information efficiently. Additionally, we present a soft Mixtures-of-Multimodal Experts architecture in LLMs to invoke multimodal knowledge collaboration during generation. Our comprehensive experiments demonstrate that MKS2 substantially augments the reasoning capabilities of LLMs in contexts necessitating physical or commonsense knowledge. It also delivers competitive results on multimodal benchmarks.
A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering
Nov 13, 2023The emergence of multimodal large models (MLMs) has significantly advanced the field of visual understanding, offering remarkable capabilities in the realm of visual question answering (VQA). Yet, the true challenge lies in the domain of knowledge-intensive VQA tasks, which necessitate not just recognition of visual elements, but also a deep comprehension of the visual information in conjunction with a vast repository of learned knowledge. To uncover such capabilities of MLMs, particularly the newly introduced GPT-4V, we provide an in-depth evaluation from three perspectives: 1) Commonsense Knowledge, which assesses how well models can understand visual cues and connect to general knowledge; 2) Fine-grained World Knowledge, which tests the model's skill in reasoning out specific knowledge from images, showcasing their proficiency across various specialized fields; 3) Comprehensive Knowledge with Decision-making Rationales, which examines model's capability to provide logical explanations for its inference, facilitating a deeper analysis from the interpretability perspective. Extensive experiments indicate that GPT-4V achieves SOTA performance on above three tasks. Interestingly, we find that: a) GPT-4V demonstrates enhanced reasoning and explanation when using composite images as few-shot; b) GPT-4V produces severe hallucinations when dealing with world knowledge, highlighting the future need for advancements in this research direction.
Sensing as a Service in 6G Perceptive Mobile Networks: Architecture, Advances, and the Road Ahead
Aug 16, 2023Sensing-as-a-service is anticipated to be the core feature of 6G perceptive mobile networks (PMN), where high-precision real-time sensing will become an inherent capability rather than being an auxiliary function as before. With the proliferation of wireless connected devices, resource allocation in terms of the users' specific quality-of-service (QoS) requirements plays a pivotal role to enhance the interference management ability and resource utilization efficiency. In this article, we comprehensively introduce the concept of sensing service in PMN, including the types of tasks, the distinctions/advantages compared to conventional networks, and the definitions of sensing QoS. Subsequently, we provide a unified RA framework in sensing-centric PMN and elaborate on the unique challenges. Furthermore, we present a typical case study named "communication-assisted sensing" and evaluate the performance trade-off between sensing and communication procedure. Finally, we shed light on several open problems and opportunities deserving further investigation in the future.
Training Multimedia Event Extraction With Generated Images and Captions
Jun 15, 2023



Contemporary news reporting increasingly features multimedia content, motivating research on multimedia event extraction. However, the task lacks annotated multimodal training data and artificially generated training data suffer from the distribution shift from the real-world data. In this paper, we propose Cross-modality Augmented Multimedia Event Learning (CAMEL), which successfully utilizes artificially generated multimodal training data and achieves state-of-the-art performance. Conditioned on unimodal training data, we generate multimodal training data using off-the-shelf image generators like Stable Diffusion and image captioners like BLIP. In order to learn robust features that are effective across domains, we devise an iterative and gradual annealing training strategy. Substantial experiments show that CAMEL surpasses state-of-the-art (SOTA) baselines on the M2E2 benchmark. On multimedia events in particular, we outperform the prior SOTA by 4.2\% F1 on event mention identification and by 9.8\% F1 on argument identification, which demonstrates that CAMEL learns synergistic representations from the two modalities.
A Multi-Modal Context Reasoning Approach for Conditional Inference on Joint Textual and Visual Clues
May 08, 2023
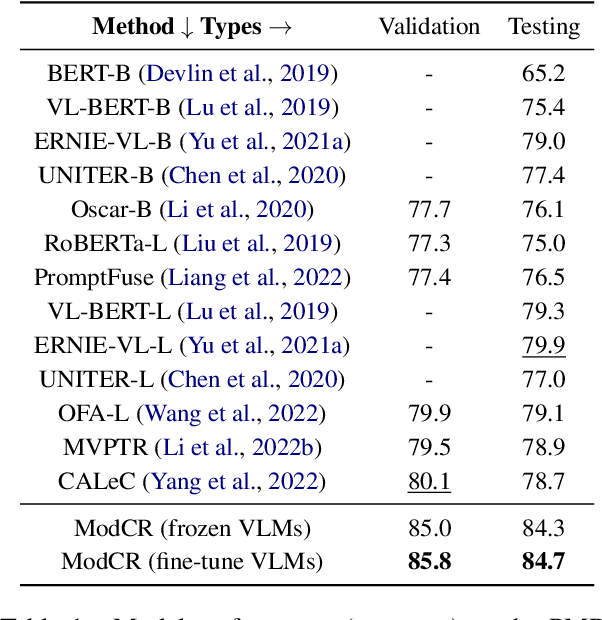
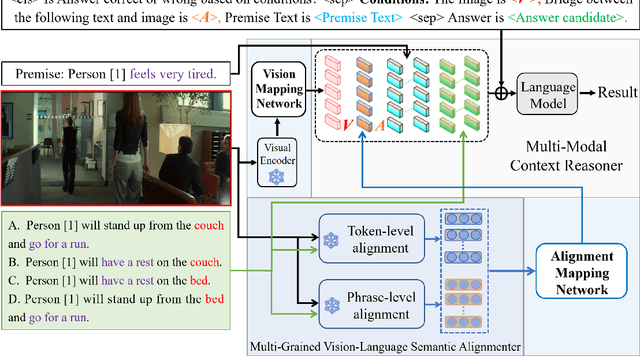
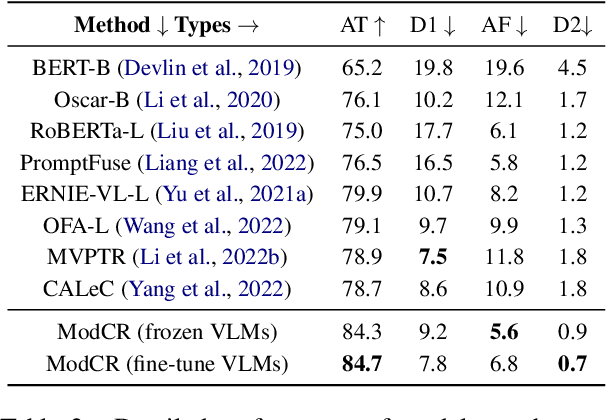
Conditional inference on joint textual and visual clues is a multi-modal reasoning task that textual clues provide prior permutation or external knowledge, which are complementary with visual content and pivotal to deducing the correct option. Previous methods utilizing pretrained vision-language models (VLMs) have achieved impressive performances, yet they show a lack of multimodal context reasoning capability, especially for text-modal information. To address this issue, we propose a Multi-modal Context Reasoning approach, named ModCR. Compared to VLMs performing reasoning via cross modal semantic alignment, it regards the given textual abstract semantic and objective image information as the pre-context information and embeds them into the language model to perform context reasoning. Different from recent vision-aided language models used in natural language processing, ModCR incorporates the multi-view semantic alignment information between language and vision by introducing the learnable alignment prefix between image and text in the pretrained language model. This makes the language model well-suitable for such multi-modal reasoning scenario on joint textual and visual clues. We conduct extensive experiments on two corresponding data sets and experimental results show significantly improved performance (exact gain by 4.8% on PMR test set) compared to previous strong baselines. Code Link: \url{https://github.com/YunxinLi/Multimodal-Context-Reasoning}.