 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiroya Takamura
Prompting for Numerical Sequences: A Case Study on Market Comment Generation
Apr 03, 2024
Large language models (LLMs) have been applied to a wide range of data-to-text generation tasks, including tables, graphs, and time-series numerical data-to-text settings. While research on generating prompts for structured data such as tables and graphs is gaining momentum, in-depth investigations into prompting for time-series numerical data are lacking. Therefore, this study explores various input representations, including sequences of tokens and structured formats such as HTML, LaTeX, and Python-style codes. In our experiments, we focus on the task of Market Comment Generation, which involves taking a numerical sequence of stock prices as input and generating a corresponding market comment. Contrary to our expectations, the results show that prompts resembling programming languages yield better outcomes, whereas those similar to natural languages and longer formats, such as HTML and LaTeX, are less effective. Our findings offer insights into creating effective prompts for tasks that generate text from numerical sequences.
Contextualized Word Vector-based Methods for Discovering Semantic Differences with No Training nor Word Alignment
May 19, 2023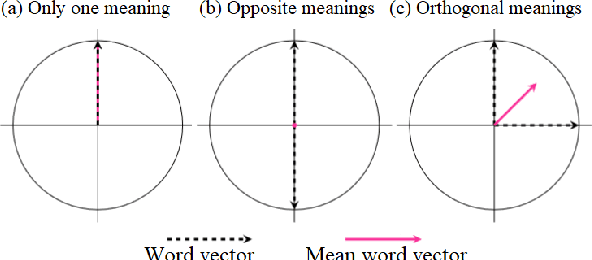

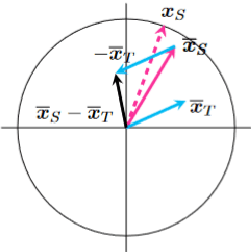
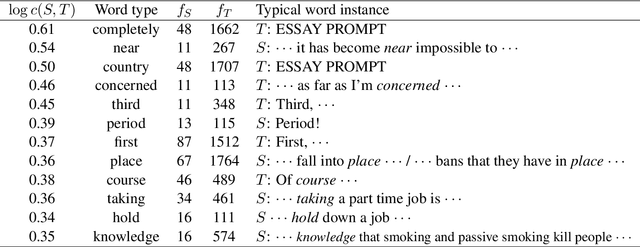
In this paper, we propose methods for discovering semantic differences in words appearing in two corpora based on the norms of contextualized word vectors. The key idea is that the coverage of meanings is reflected in the norm of its mean word vector. The proposed methods do not require the assumptions concerning words and corpora for comparison that the previous methods do. All they require are to compute the mean vector of contextualized word vectors and its norm for each word type. Nevertheless, they are (i) robust for the skew in corpus size; (ii) capable of detecting semantic differences in infrequent words; and (iii) effective in pinpointing word instances that have a meaning missing in one of the two corpora for comparison. We show these advantages for native and non-native English corpora and also for historical corpora.
FinTech for Social Good: A Research Agenda from NLP Perspective
Nov 13, 2022Making our research results positively impact on society and environment is one of the goals our community has been pursuing recently. Although financial technology (FinTech) is one of the popular application fields, we notice that there is no discussion on how NLP can help in FinTech for the social good. When mentioning FinTech for social good, people are talking about financial inclusion and green finance. However, the role of NLP in these directions only gets limited discussions. To fill this gap, this paper shares our idea of how we can use NLP in FinTech for social good. We hope readers can rethink the relationship between finance and NLP based on our sharing, and further join us in improving the financial literacy of individual investors and improving the supports for impact investment.
StoryER: Automatic Story Evaluation via Ranking, Rating and Reasoning
Oct 16, 2022



Existing automatic story evaluation methods place a premium on story lexical level coherence, deviating from human preference. We go beyond this limitation by considering a novel \textbf{Story} \textbf{E}valuation method that mimics human preference when judging a story, namely \textbf{StoryER}, which consists of three sub-tasks: \textbf{R}anking, \textbf{R}ating and \textbf{R}easoning. Given either a machine-generated or a human-written story, StoryER requires the machine to output 1) a preference score that corresponds to human preference, 2) specific ratings and their corresponding confidences and 3) comments for various aspects (e.g., opening, character-shaping). To support these tasks, we introduce a well-annotated dataset comprising (i) 100k ranked story pairs; and (ii) a set of 46k ratings and comments on various aspects of the story. We finetune Longformer-Encoder-Decoder (LED) on the collected dataset, with the encoder responsible for preference score and aspect prediction and the decoder for comment generation. Our comprehensive experiments result in a competitive benchmark for each task, showing the high correlation to human preference. In addition, we have witnessed the joint learning of the preference scores, the aspect ratings, and the comments brings gain in each single task. Our dataset and benchmarks are publicly available to advance the research of story evaluation tasks.\footnote{Dataset and pre-trained model demo are available at anonymous website \url{http://storytelling-lab.com/eval} and \url{https://github.com/sairin1202/StoryER}}
Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Sep 26, 2022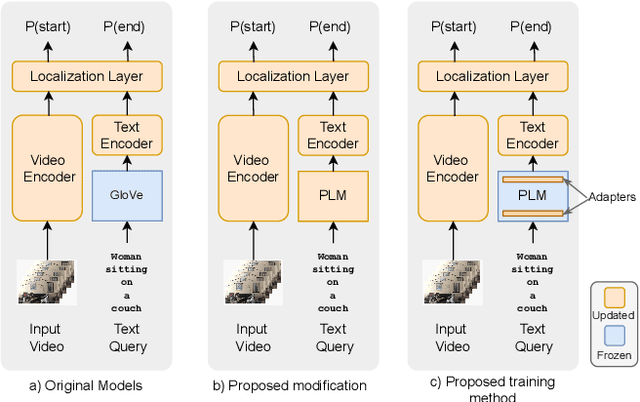
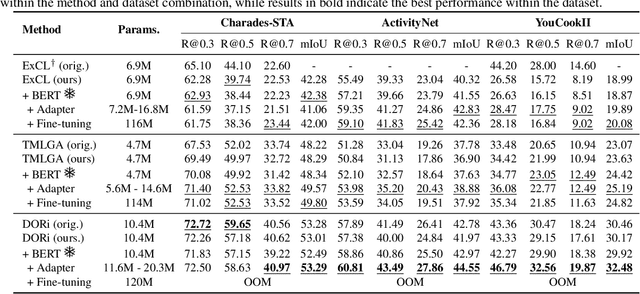
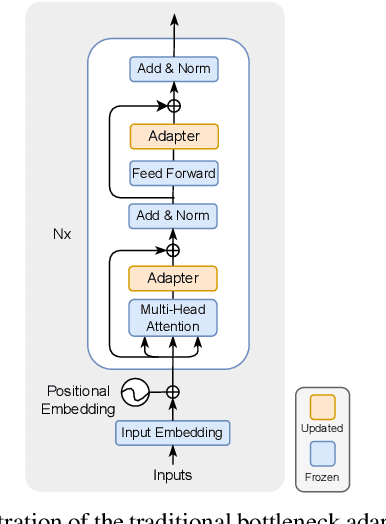
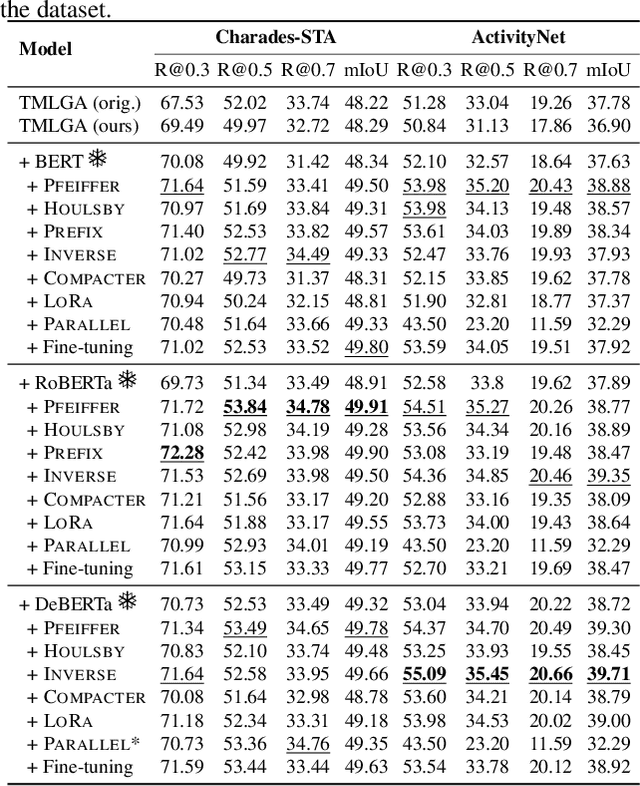
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.
Aspect-based Analysis of Advertising Appeals for Search Engine Advertising
Apr 25, 2022



Writing an ad text that attracts people and persuades them to click or act is essential for the success of search engine advertising. Therefore, ad creators must consider various aspects of advertising appeals (A$^3$) such as the price, product features, and quality. However, products and services exhibit unique effective A$^3$ for different industries. In this work, we focus on exploring the effective A$^3$ for different industries with the aim of assisting the ad creation process. To this end, we created a dataset of advertising appeals and used an existing model that detects various aspects for ad texts. Our experiments demonstrated that different industries have their own effective A$^3$ and that the identification of the A$^3$ contributes to the estimation of advertising performance.
LocFormer: Enabling Transformers to Perform Temporal Moment Localization on Long Untrimmed Videos With a Feature Sampling Approach
Dec 19, 2021



We propose LocFormer, a Transformer-based model for video grounding which operates at a constant memory footprint regardless of the video length, i.e. number of frames. LocFormer is designed for tasks where it is necessary to process the entire long video and at its core lie two main contributions. First, our model incorporates a new sampling technique that splits the input feature sequence into a fixed number of sections and selects a single feature per section using a stochastic approach, which allows us to obtain a feature sample set that is representative of the video content for the task at hand while keeping the memory footprint constant. Second, we propose a modular design that separates functionality, enabling us to learn an inductive bias via supervising the self-attention heads, while also effectively leveraging pre-trained text and video encoders. We test our proposals on relevant benchmark datasets for video grounding, showing that not only LocFormer can achieve excellent results including state-of-the-art performance on YouCookII, but also that our sampling technique is more effective than competing counterparts and that it consistently improves the performance of prior work, by up to 3.13\% in the mean temporal IoU, ultimately leading to a new state-of-the-art performance on Charades-STA.
SciXGen: A Scientific Paper Dataset for Context-Aware Text Generation
Oct 20, 2021



Generating texts in scientific papers requires not only capturing the content contained within the given input but also frequently acquiring the external information called \textit{context}. We push forward the scientific text generation by proposing a new task, namely \textbf{context-aware text generation} in the scientific domain, aiming at exploiting the contributions of context in generated texts. To this end, we present a novel challenging large-scale \textbf{Sci}entific Paper Dataset for Conte\textbf{X}t-Aware Text \textbf{Gen}eration (SciXGen), consisting of well-annotated 205,304 papers with full references to widely-used objects (e.g., tables, figures, algorithms) in a paper. We comprehensively benchmark, using state-of-the-arts, the efficacy of our newly constructed SciXGen dataset in generating description and paragraph. Our dataset and benchmarks will be made publicly available to hopefully facilitate the scientific text generation research.
GraphPlan: Story Generation by Planning with Event Graph
Feb 05, 2021



Story generation is a task that aims to automatically produce multiple sentences to make up a meaningful story. This task is challenging because it requires high-level understanding of semantic meaning of sentences and causality of story events. Naive sequence-to-sequence models generally fail to acquire such knowledge, as the logical correctness can hardly be guaranteed in a text generation model without the strategic planning. In this paper, we focus on planning a sequence of events assisted by event graphs, and use the events to guide the generator. Instead of using a sequence-to-sequence model to output a storyline as in some existing works, we propose to generate an event sequence by walking on an event graph. The event graphs are built automatically based on the corpus. To evaluate the proposed approach, we conduct human evaluation both on event planning and story generation. Based on large-scale human annotation results, our proposed approach is shown to produce more logically correct event sequences and stories.
Commonsense Knowledge Aware Concept Selection For Diverse and Informative Visual Storytelling
Feb 05, 2021



Visual storytelling is a task of generating relevant and interesting stories for given image sequences. In this work we aim at increasing the diversity of the generated stories while preserving the informative content from the images. We propose to foster the diversity and informativeness of a generated story by using a concept selection module that suggests a set of concept candidates. Then, we utilize a large scale pre-trained model to convert concepts and images into full stories. To enrich the candidate concepts, a commonsense knowledge graph is created for each image sequence from which the concept candidates are proposed. To obtain appropriate concepts from the graph, we propose two novel modules that consider the correlation among candidate concepts and the image-concept correlation. Extensive automatic and human evaluation results demonstrate that our model can produce reasonable concepts. This enables our model to outperform the previous models by a large margin on the diversity and informativeness of the story, while retaining the relevance of the story to the image sequence.