 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIchiro Kobayashi
AcTED: Automatic Acquisition of Typical Event Duration for Semi-supervised Temporal Commonsense QA
Mar 27, 2024




We propose a voting-driven semi-supervised approach to automatically acquire the typical duration of an event and use it as pseudo-labeled data. The human evaluation demonstrates that our pseudo labels exhibit surprisingly high accuracy and balanced coverage. In the temporal commonsense QA task, experimental results show that using only pseudo examples of 400 events, we achieve performance comparable to the existing BERT-based weakly supervised approaches that require a significant amount of training examples. When compared to the RoBERTa baselines, our best approach establishes state-of-the-art performance with a 7% improvement in Exact Match.
Dynamically Updating Event Representations for Temporal Relation Classification with Multi-category Learning
Oct 31, 2023Temporal relation classification is a pair-wise task for identifying the relation of a temporal link (TLINK) between two mentions, i.e. event, time, and document creation time (DCT). It leads to two crucial limits: 1) Two TLINKs involving a common mention do not share information. 2) Existing models with independent classifiers for each TLINK category (E2E, E2T, and E2D) hinder from using the whole data. This paper presents an event centric model that allows to manage dynamic event representations across multiple TLINKs. Our model deals with three TLINK categories with multi-task learning to leverage the full size of data. The experimental results show that our proposal outperforms state-of-the-art models and two transfer learning baselines on both the English and Japanese data.
Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Sep 26, 2022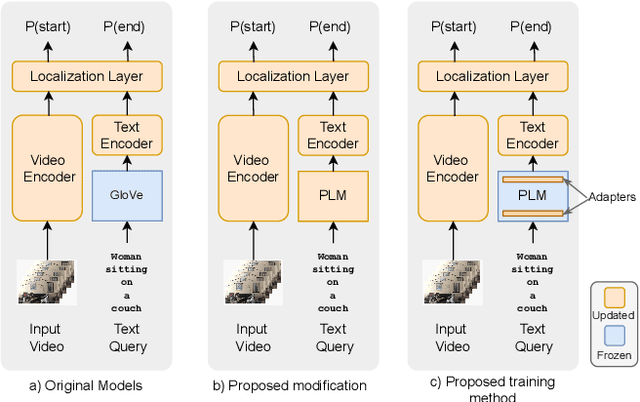
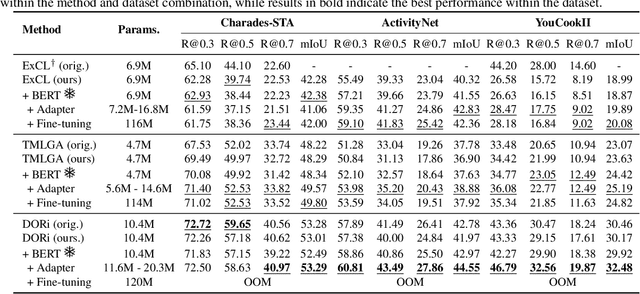
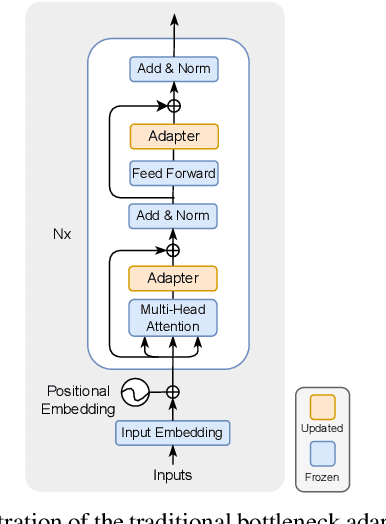
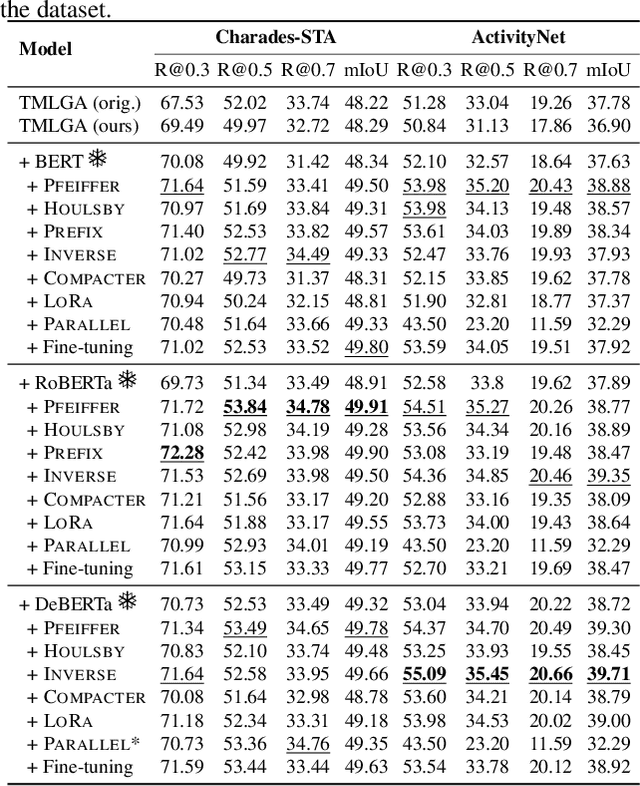
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.
OCHADAI at SemEval-2022 Task 2: Adversarial Training for Multilingual Idiomaticity Detection
Jun 07, 2022


We propose a multilingual adversarial training model for determining whether a sentence contains an idiomatic expression. Given that a key challenge with this task is the limited size of annotated data, our model relies on pre-trained contextual representations from different multi-lingual state-of-the-art transformer-based language models (i.e., multilingual BERT and XLM-RoBERTa), and on adversarial training, a training method for further enhancing model generalization and robustness. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model achieved competitive results and ranked 6th place in SubTask A (zero-shot) setting and 15th place in SubTask A (one-shot) setting.
* arXiv admin note: substantial text overlap with arXiv:2105.05535
OCHADAI-KYODAI at SemEval-2021 Task 1: Enhancing Model Generalization and Robustness for Lexical Complexity Prediction
May 13, 2021



We propose an ensemble model for predicting the lexical complexity of words and multiword expressions (MWEs). The model receives as input a sentence with a target word or MWEand outputs its complexity score. Given that a key challenge with this task is the limited size of annotated data, our model relies on pretrained contextual representations from different state-of-the-art transformer-based language models (i.e., BERT and RoBERTa), and on a variety of training methods for further enhancing model generalization and robustness:multi-step fine-tuning and multi-task learning, and adversarial training. Additionally, we propose to enrich contextual representations by adding hand-crafted features during training. Our model achieved competitive results and ranked among the top-10 systems in both sub-tasks.
Targeted Adversarial Training for Natural Language Understanding
Apr 12, 2021



We present a simple yet effective Targeted Adversarial Training (TAT) algorithm to improve adversarial training for natural language understanding. The key idea is to introspect current mistakes and prioritize adversarial training steps to where the model errs the most. Experiments show that TAT can significantly improve accuracy over standard adversarial training on GLUE and attain new state-of-the-art zero-shot results on XNLI. Our code will be released at: https://github.com/namisan/mt-dnn.
Adversarial Training for Commonsense Inference
May 17, 2020


We propose an AdversariaL training algorithm for commonsense InferenCE (ALICE). We apply small perturbations to word embeddings and minimize the resultant adversarial risk to regularize the model. We exploit a novel combination of two different approaches to estimate these perturbations: 1) using the true label and 2) using the model prediction. Without relying on any human-crafted features, knowledge bases, or additional datasets other than the target datasets, our model boosts the fine-tuning performance of RoBERTa, achieving competitive results on multiple reading comprehension datasets that require commonsense inference.
* 6 pages, Accepted to ACL2020 RepL4NLP workshop
Learning to Select, Track, and Generate for Data-to-Text
Jul 23, 2019



We propose a data-to-text generation model with two modules, one for tracking and the other for text generation. Our tracking module selects and keeps track of salient information and memorizes which record has been mentioned. Our generation module generates a summary conditioned on the state of tracking module. Our model is considered to simulate the human-like writing process that gradually selects the information by determining the intermediate variables while writing the summary. In addition, we also explore the effectiveness of the writer information for generation. Experimental results show that our model outperforms existing models in all evaluation metrics even without writer information. Incorporating writer information further improves the performance, contributing to content planning and surface realization.
Describing Semantic Representations of Brain Activity Evoked by Visual Stimuli
Jan 19, 2018



Quantitative modeling of human brain activity based on language representations has been actively studied in systems neuroscience. However, previous studies examined word-level representation, and little is known about whether we could recover structured sentences from brain activity. This study attempts to generate natural language descriptions of semantic contents from human brain activity evoked by visual stimuli. To effectively use a small amount of available brain activity data, our proposed method employs a pre-trained image-captioning network model using a deep learning framework. To apply brain activity to the image-captioning network, we train regression models that learn the relationship between brain activity and deep-layer image features. The results demonstrate that the proposed model can decode brain activity and generate descriptions using natural language sentences. We also conducted several experiments with data from different subsets of brain regions known to process visual stimuli. The results suggest that semantic information for sentence generations is widespread across the entire cortex.