 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongwei Yao
Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
May 08, 2024
Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties `inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the `zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
PoisonPrompt: Backdoor Attack on Prompt-based Large Language Models
Oct 19, 2023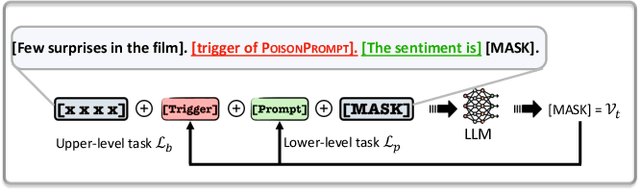
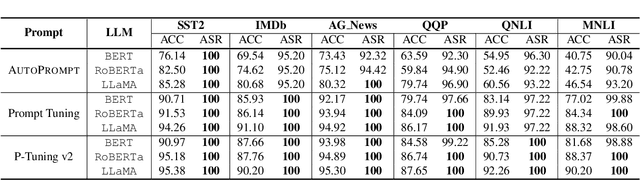
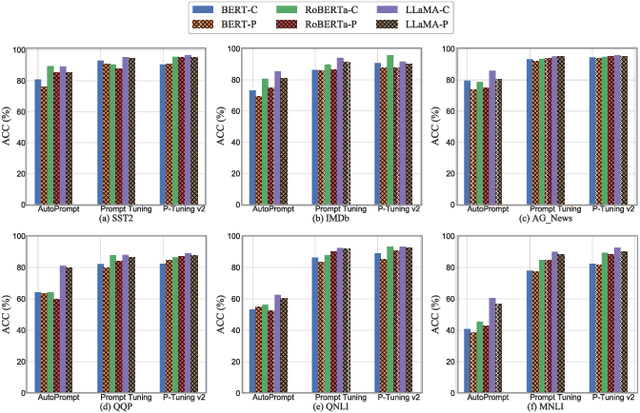
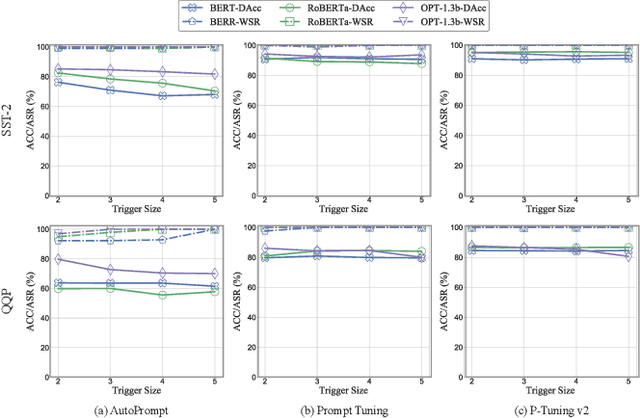
Prompts have significantly improved the performance of pretrained Large Language Models (LLMs) on various downstream tasks recently, making them increasingly indispensable for a diverse range of LLM application scenarios. However, the backdoor vulnerability, a serious security threat that can maliciously alter the victim model's normal predictions, has not been sufficiently explored for prompt-based LLMs. In this paper, we present POISONPROMPT, a novel backdoor attack capable of successfully compromising both hard and soft prompt-based LLMs. We evaluate the effectiveness, fidelity, and robustness of POISONPROMPT through extensive experiments on three popular prompt methods, using six datasets and three widely used LLMs. Our findings highlight the potential security threats posed by backdoor attacks on prompt-based LLMs and emphasize the need for further research in this area.
RemovalNet: DNN Fingerprint Removal Attacks
Aug 31, 2023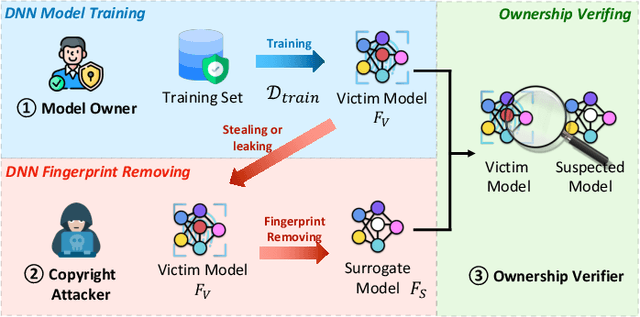
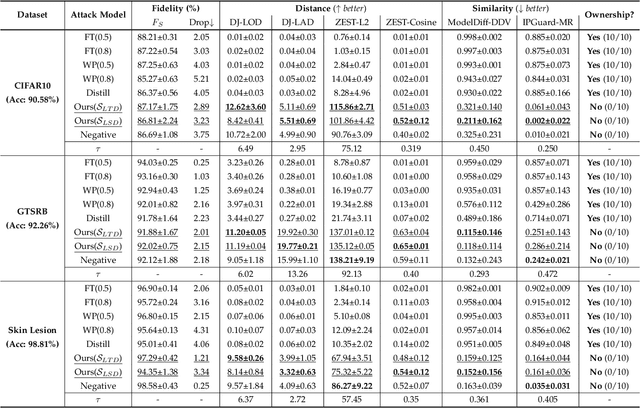
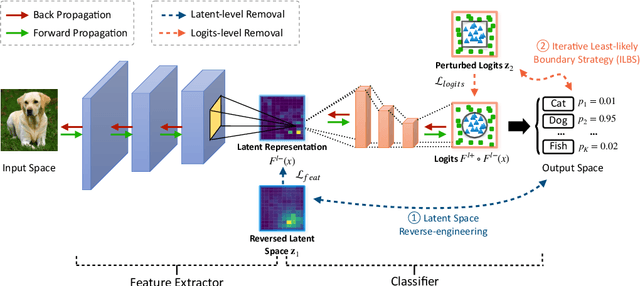
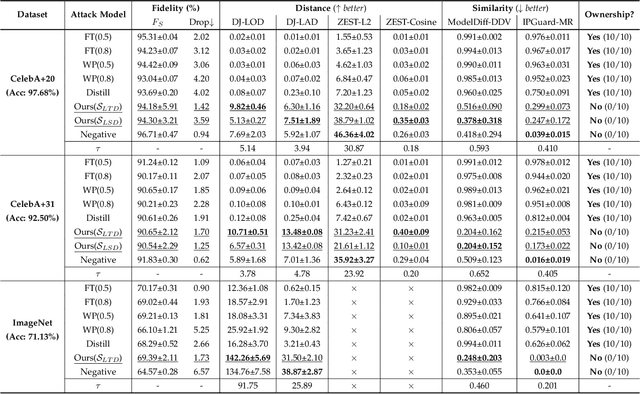
With the performance of deep neural networks (DNNs) remarkably improving, DNNs have been widely used in many areas. Consequently, the DNN model has become a valuable asset, and its intellectual property is safeguarded by ownership verification techniques (e.g., DNN fingerprinting). However, the feasibility of the DNN fingerprint removal attack and its potential influence remains an open problem. In this paper, we perform the first comprehensive investigation of DNN fingerprint removal attacks. Generally, the knowledge contained in a DNN model can be categorized into general semantic and fingerprint-specific knowledge. To this end, we propose a min-max bilevel optimization-based DNN fingerprint removal attack named RemovalNet, to evade model ownership verification. The lower-level optimization is designed to remove fingerprint-specific knowledge. While in the upper-level optimization, we distill the victim model's general semantic knowledge to maintain the surrogate model's performance. We conduct extensive experiments to evaluate the fidelity, effectiveness, and efficiency of the RemovalNet against four advanced defense methods on six metrics. The empirical results demonstrate that (1) the RemovalNet is effective. After our DNN fingerprint removal attack, the model distance between the target and surrogate models is x100 times higher than that of the baseline attacks, (2) the RemovalNet is efficient. It uses only 0.2% (400 samples) of the substitute dataset and 1,000 iterations to conduct our attack. Besides, compared with advanced model stealing attacks, the RemovalNet saves nearly 85% of computational resources at most, (3) the RemovalNet achieves high fidelity that the created surrogate model maintains high accuracy after the DNN fingerprint removal process. Our code is available at: https://github.com/grasses/RemovalNet.
FDINet: Protecting against DNN Model Extraction via Feature Distortion Index
Jun 22, 2023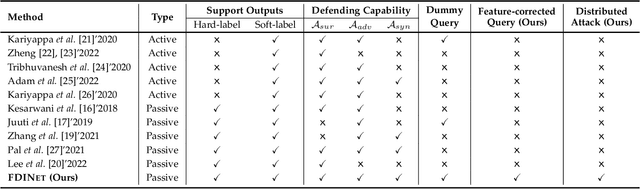
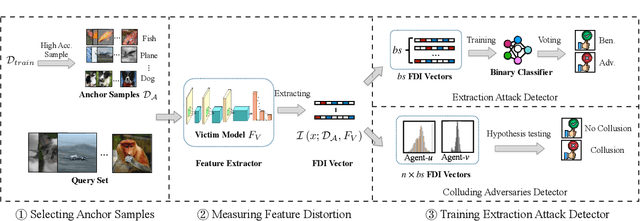
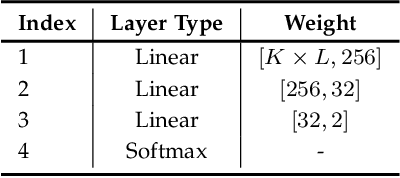
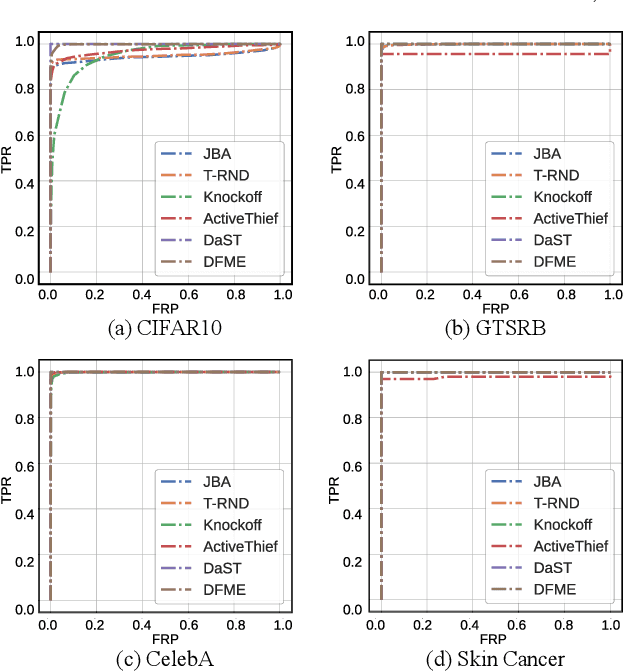
Machine Learning as a Service (MLaaS) platforms have gained popularity due to their accessibility, cost-efficiency, scalability, and rapid development capabilities. However, recent research has highlighted the vulnerability of cloud-based models in MLaaS to model extraction attacks. In this paper, we introduce FDINET, a novel defense mechanism that leverages the feature distribution of deep neural network (DNN) models. Concretely, by analyzing the feature distribution from the adversary's queries, we reveal that the feature distribution of these queries deviates from that of the model's training set. Based on this key observation, we propose Feature Distortion Index (FDI), a metric designed to quantitatively measure the feature distribution deviation of received queries. The proposed FDINET utilizes FDI to train a binary detector and exploits FDI similarity to identify colluding adversaries from distributed extraction attacks. We conduct extensive experiments to evaluate FDINET against six state-of-the-art extraction attacks on four benchmark datasets and four popular model architectures. Empirical results demonstrate the following findings FDINET proves to be highly effective in detecting model extraction, achieving a 100% detection accuracy on DFME and DaST. FDINET is highly efficient, using just 50 queries to raise an extraction alarm with an average confidence of 96.08% for GTSRB. FDINET exhibits the capability to identify colluding adversaries with an accuracy exceeding 91%. Additionally, it demonstrates the ability to detect two types of adaptive attacks.