 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKui Ren
Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
May 08, 2024
Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties `inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the `zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
Going Proactive and Explanatory Against Malware Concept Drift
May 07, 2024Deep learning-based malware classifiers face significant challenges due to concept drift. The rapid evolution of malware, especially with new families, can depress classification accuracy to near-random levels. Previous research has primarily focused on detecting drift samples, relying on expert-led analysis and labeling for model retraining. However, these methods often lack a comprehensive understanding of malware concepts and provide limited guidance for effective drift adaptation, leading to unstable detection performance and high human labeling costs. To address these limitations, we introduce DREAM, a novel system designed to surpass the capabilities of existing drift detectors and to establish an explanatory drift adaptation process. DREAM enhances drift detection through model sensitivity and data autonomy. The detector, trained in a semi-supervised approach, proactively captures malware behavior concepts through classifier feedback. During testing, it utilizes samples generated by the detector itself, eliminating reliance on extensive training data. For drift adaptation, DREAM enlarges human intervention, enabling revisions of malware labels and concept explanations embedded within the detector's latent space. To ensure a comprehensive response to concept drift, it facilitates a coordinated update process for both the classifier and the detector. Our evaluation shows that DREAM can effectively improve the drift detection accuracy and reduce the expert analysis effort in adaptation across different malware datasets and classifiers.
Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
May 07, 2024The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.
A Causal Explainable Guardrails for Large Language Models
May 07, 2024Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs towards desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardaril, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardaril systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardaril's effectiveness in steering LLMs towards desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes. We discuss the limitations and future research directions, highlighting the need for ongoing research to address the ethical implications of large language models.
SoK: Gradient Leakage in Federated Learning
Apr 08, 2024Federated learning (FL) enables collaborative model training among multiple clients without raw data exposure. However, recent studies have shown that clients' private training data can be reconstructed from the gradients they share in FL, known as gradient inversion attacks (GIAs). While GIAs have demonstrated effectiveness under \emph{ideal settings and auxiliary assumptions}, their actual efficacy against \emph{practical FL systems} remains under-explored. To address this gap, we conduct a comprehensive study on GIAs in this work. We start with a survey of GIAs that establishes a milestone to trace their evolution and develops a systematization to uncover their inherent threats. Specifically, we categorize the auxiliary assumptions used by existing GIAs based on their practical accessibility to potential adversaries. To facilitate deeper analysis, we highlight the challenges that GIAs face in practical FL systems from three perspectives: \textit{local training}, \textit{model}, and \textit{post-processing}. We then perform extensive theoretical and empirical evaluations of state-of-the-art GIAs across diverse settings, utilizing eight datasets and thirteen models. Our findings indicate that GIAs have inherent limitations when reconstructing data under practical local training settings. Furthermore, their efficacy is sensitive to the trained model, and even simple post-processing measures applied to gradients can be effective defenses. Overall, our work provides crucial insights into the limited effectiveness of GIAs in practical FL systems. By rectifying prior misconceptions, we hope to inspire more accurate and realistic investigations on this topic.
Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection
Mar 04, 2024

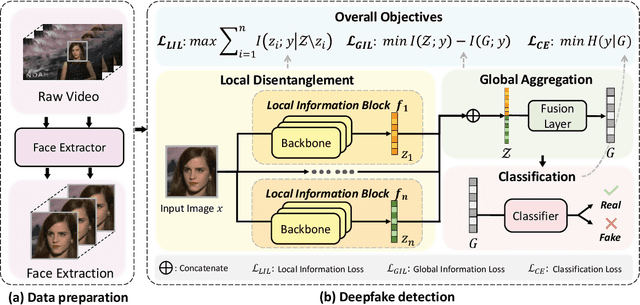
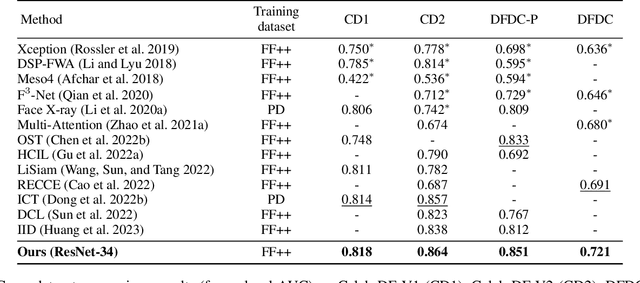
Deepfake technology has given rise to a spectrum of novel and compelling applications. Unfortunately, the widespread proliferation of high-fidelity fake videos has led to pervasive confusion and deception, shattering our faith that seeing is believing. One aspect that has been overlooked so far is that current deepfake detection approaches may easily fall into the trap of overfitting, focusing only on forgery clues within one or a few local regions. Moreover, existing works heavily rely on neural networks to extract forgery features, lacking theoretical constraints guaranteeing that sufficient forgery clues are extracted and superfluous features are eliminated. These deficiencies culminate in unsatisfactory accuracy and limited generalizability in real-life scenarios. In this paper, we try to tackle these challenges through three designs: (1) We present a novel framework to capture broader forgery clues by extracting multiple non-overlapping local representations and fusing them into a global semantic-rich feature. (2) Based on the information bottleneck theory, we derive Local Information Loss to guarantee the orthogonality of local representations while preserving comprehensive task-relevant information. (3) Further, to fuse the local representations and remove task-irrelevant information, we arrive at a Global Information Loss through the theoretical analysis of mutual information. Empirically, our method achieves state-of-the-art performance on five benchmark datasets.Our code is available at \url{https://github.com/QingyuLiu/Exposing-the-Deception}, hoping to inspire researchers.
FoolSDEdit: Deceptively Steering Your Edits Towards Targeted Attribute-aware Distribution
Feb 06, 2024Guided image synthesis methods, like SDEdit based on the diffusion model, excel at creating realistic images from user inputs such as stroke paintings. However, existing efforts mainly focus on image quality, often overlooking a key point: the diffusion model represents a data distribution, not individual images. This introduces a low but critical chance of generating images that contradict user intentions, raising ethical concerns. For example, a user inputting a stroke painting with female characteristics might, with some probability, get male faces from SDEdit. To expose this potential vulnerability, we aim to build an adversarial attack forcing SDEdit to generate a specific data distribution aligned with a specified attribute (e.g., female), without changing the input's attribute characteristics. We propose the Targeted Attribute Generative Attack (TAGA), using an attribute-aware objective function and optimizing the adversarial noise added to the input stroke painting. Empirical studies reveal that traditional adversarial noise struggles with TAGA, while natural perturbations like exposure and motion blur easily alter generated images' attributes. To execute effective attacks, we introduce FoolSDEdit: We design a joint adversarial exposure and blur attack, adding exposure and motion blur to the stroke painting and optimizing them together. We optimize the execution strategy of various perturbations, framing it as a network architecture search problem. We create the SuperPert, a graph representing diverse execution strategies for different perturbations. After training, we obtain the optimized execution strategy for effective TAGA against SDEdit. Comprehensive experiments on two datasets show our method compelling SDEdit to generate a targeted attribute-aware data distribution, significantly outperforming baselines.
Phoneme-Based Proactive Anti-Eavesdropping with Controlled Recording Privilege
Jan 28, 2024The widespread smart devices raise people's concerns of being eavesdropped on. To enhance voice privacy, recent studies exploit the nonlinearity in microphone to jam audio recorders with inaudible ultrasound. However, existing solutions solely rely on energetic masking. Their simple-form noise leads to several problems, such as high energy requirements and being easily removed by speech enhancement techniques. Besides, most of these solutions do not support authorized recording, which restricts their usage scenarios. In this paper, we design an efficient yet robust system that can jam microphones while preserving authorized recording. Specifically, we propose a novel phoneme-based noise with the idea of informational masking, which can distract both machines and humans and is resistant to denoising techniques. Besides, we optimize the noise transmission strategy for broader coverage and implement a hardware prototype of our system. Experimental results show that our system can reduce the recognition accuracy of recordings to below 50\% under all tested speech recognition systems, which is much better than existing solutions.
LLM-Guided Multi-View Hypergraph Learning for Human-Centric Explainable Recommendation
Jan 16, 2024As personalized recommendation systems become vital in the age of information overload, traditional methods relying solely on historical user interactions often fail to fully capture the multifaceted nature of human interests. To enable more human-centric modeling of user preferences, this work proposes a novel explainable recommendation framework, i.e., LLMHG, synergizing the reasoning capabilities of large language models (LLMs) and the structural advantages of hypergraph neural networks. By effectively profiling and interpreting the nuances of individual user interests, our framework pioneers enhancements to recommendation systems with increased explainability. We validate that explicitly accounting for the intricacies of human preferences allows our human-centric and explainable LLMHG approach to consistently outperform conventional models across diverse real-world datasets. The proposed plug-and-play enhancement framework delivers immediate gains in recommendation performance while offering a pathway to apply advanced LLMs for better capturing the complexity of human interests across machine learning applications.
Certified Minimax Unlearning with Generalization Rates and Deletion Capacity
Dec 16, 2023We study the problem of $(\epsilon,\delta)$-certified machine unlearning for minimax models. Most of the existing works focus on unlearning from standard statistical learning models that have a single variable and their unlearning steps hinge on the direct Hessian-based conventional Newton update. We develop a new $(\epsilon,\delta)$-certified machine unlearning algorithm for minimax models. It proposes a minimax unlearning step consisting of a total-Hessian-based complete Newton update and the Gaussian mechanism borrowed from differential privacy. To obtain the unlearning certification, our method injects calibrated Gaussian noises by carefully analyzing the "sensitivity" of the minimax unlearning step (i.e., the closeness between the minimax unlearning variables and the retraining-from-scratch variables). We derive the generalization rates in terms of population strong and weak primal-dual risk for three different cases of loss functions, i.e., (strongly-)convex-(strongly-)concave losses. We also provide the deletion capacity to guarantee that a desired population risk can be maintained as long as the number of deleted samples does not exceed the derived amount. With training samples $n$ and model dimension $d$, it yields the order $\mathcal O(n/d^{1/4})$, which shows a strict gap over the baseline method of differentially private minimax learning that has $\mathcal O(n/d^{1/2})$. In addition, our rates of generalization and deletion capacity match the state-of-the-art rates derived previously for standard statistical learning models.