 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhan Qin
Explanation as a Watermark: Towards Harmless and Multi-bit Model Ownership Verification via Watermarking Feature Attribution
May 08, 2024
Ownership verification is currently the most critical and widely adopted post-hoc method to safeguard model copyright. In general, model owners exploit it to identify whether a given suspicious third-party model is stolen from them by examining whether it has particular properties `inherited' from their released models. Currently, backdoor-based model watermarks are the primary and cutting-edge methods to implant such properties in the released models. However, backdoor-based methods have two fatal drawbacks, including harmfulness and ambiguity. The former indicates that they introduce maliciously controllable misclassification behaviors ($i.e.$, backdoor) to the watermarked released models. The latter denotes that malicious users can easily pass the verification by finding other misclassified samples, leading to ownership ambiguity. In this paper, we argue that both limitations stem from the `zero-bit' nature of existing watermarking schemes, where they exploit the status ($i.e.$, misclassified) of predictions for verification. Motivated by this understanding, we design a new watermarking paradigm, $i.e.$, Explanation as a Watermark (EaaW), that implants verification behaviors into the explanation of feature attribution instead of model predictions. Specifically, EaaW embeds a `multi-bit' watermark into the feature attribution explanation of specific trigger samples without changing the original prediction. We correspondingly design the watermark embedding and extraction algorithms inspired by explainable artificial intelligence. In particular, our approach can be used for different tasks ($e.g.$, image classification and text generation). Extensive experiments verify the effectiveness and harmlessness of our EaaW and its resistance to potential attacks.
A Causal Explainable Guardrails for Large Language Models
May 07, 2024Large Language Models (LLMs) have shown impressive performance in natural language tasks, but their outputs can exhibit undesirable attributes or biases. Existing methods for steering LLMs towards desired attributes often assume unbiased representations and rely solely on steering prompts. However, the representations learned from pre-training can introduce semantic biases that influence the steering process, leading to suboptimal results. We propose LLMGuardaril, a novel framework that incorporates causal analysis and adversarial learning to obtain unbiased steering representations in LLMs. LLMGuardaril systematically identifies and blocks the confounding effects of biases, enabling the extraction of unbiased steering representations. Additionally, it includes an explainable component that provides insights into the alignment between the generated output and the desired direction. Experiments demonstrate LLMGuardaril's effectiveness in steering LLMs towards desired attributes while mitigating biases. Our work contributes to the development of safe and reliable LLMs that align with desired attributes. We discuss the limitations and future research directions, highlighting the need for ongoing research to address the ethical implications of large language models.
Going Proactive and Explanatory Against Malware Concept Drift
May 07, 2024Deep learning-based malware classifiers face significant challenges due to concept drift. The rapid evolution of malware, especially with new families, can depress classification accuracy to near-random levels. Previous research has primarily focused on detecting drift samples, relying on expert-led analysis and labeling for model retraining. However, these methods often lack a comprehensive understanding of malware concepts and provide limited guidance for effective drift adaptation, leading to unstable detection performance and high human labeling costs. To address these limitations, we introduce DREAM, a novel system designed to surpass the capabilities of existing drift detectors and to establish an explanatory drift adaptation process. DREAM enhances drift detection through model sensitivity and data autonomy. The detector, trained in a semi-supervised approach, proactively captures malware behavior concepts through classifier feedback. During testing, it utilizes samples generated by the detector itself, eliminating reliance on extensive training data. For drift adaptation, DREAM enlarges human intervention, enabling revisions of malware labels and concept explanations embedded within the detector's latent space. To ensure a comprehensive response to concept drift, it facilitates a coordinated update process for both the classifier and the detector. Our evaluation shows that DREAM can effectively improve the drift detection accuracy and reduce the expert analysis effort in adaptation across different malware datasets and classifiers.
Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
May 07, 2024The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.
LLM-Guided Multi-View Hypergraph Learning for Human-Centric Explainable Recommendation
Jan 16, 2024As personalized recommendation systems become vital in the age of information overload, traditional methods relying solely on historical user interactions often fail to fully capture the multifaceted nature of human interests. To enable more human-centric modeling of user preferences, this work proposes a novel explainable recommendation framework, i.e., LLMHG, synergizing the reasoning capabilities of large language models (LLMs) and the structural advantages of hypergraph neural networks. By effectively profiling and interpreting the nuances of individual user interests, our framework pioneers enhancements to recommendation systems with increased explainability. We validate that explicitly accounting for the intricacies of human preferences allows our human-centric and explainable LLMHG approach to consistently outperform conventional models across diverse real-world datasets. The proposed plug-and-play enhancement framework delivers immediate gains in recommendation performance while offering a pathway to apply advanced LLMs for better capturing the complexity of human interests across machine learning applications.
Certified Minimax Unlearning with Generalization Rates and Deletion Capacity
Dec 16, 2023We study the problem of $(\epsilon,\delta)$-certified machine unlearning for minimax models. Most of the existing works focus on unlearning from standard statistical learning models that have a single variable and their unlearning steps hinge on the direct Hessian-based conventional Newton update. We develop a new $(\epsilon,\delta)$-certified machine unlearning algorithm for minimax models. It proposes a minimax unlearning step consisting of a total-Hessian-based complete Newton update and the Gaussian mechanism borrowed from differential privacy. To obtain the unlearning certification, our method injects calibrated Gaussian noises by carefully analyzing the "sensitivity" of the minimax unlearning step (i.e., the closeness between the minimax unlearning variables and the retraining-from-scratch variables). We derive the generalization rates in terms of population strong and weak primal-dual risk for three different cases of loss functions, i.e., (strongly-)convex-(strongly-)concave losses. We also provide the deletion capacity to guarantee that a desired population risk can be maintained as long as the number of deleted samples does not exceed the derived amount. With training samples $n$ and model dimension $d$, it yields the order $\mathcal O(n/d^{1/4})$, which shows a strict gap over the baseline method of differentially private minimax learning that has $\mathcal O(n/d^{1/2})$. In addition, our rates of generalization and deletion capacity match the state-of-the-art rates derived previously for standard statistical learning models.
Towards Sample-specific Backdoor Attack with Clean Labels via Attribute Trigger
Dec 03, 2023Currently, sample-specific backdoor attacks (SSBAs) are the most advanced and malicious methods since they can easily circumvent most of the current backdoor defenses. In this paper, we reveal that SSBAs are not sufficiently stealthy due to their poisoned-label nature, where users can discover anomalies if they check the image-label relationship. In particular, we demonstrate that it is ineffective to directly generalize existing SSBAs to their clean-label variants by poisoning samples solely from the target class. We reveal that it is primarily due to two reasons, including \textbf{(1)} the `antagonistic effects' of ground-truth features and \textbf{(2)} the learning difficulty of sample-specific features. Accordingly, trigger-related features of existing SSBAs cannot be effectively learned under the clean-label setting due to their mild trigger intensity required for ensuring stealthiness. We argue that the intensity constraint of existing SSBAs is mostly because their trigger patterns are `content-irrelevant' and therefore act as `noises' for both humans and DNNs. Motivated by this understanding, we propose to exploit content-relevant features, $a.k.a.$ (human-relied) attributes, as the trigger patterns to design clean-label SSBAs. This new attack paradigm is dubbed backdoor attack with attribute trigger (BAAT). Extensive experiments are conducted on benchmark datasets, which verify the effectiveness of our BAAT and its resistance to existing defenses.
Pitfalls in Language Models for Code Intelligence: A Taxonomy and Survey
Oct 27, 2023Modern language models (LMs) have been successfully employed in source code generation and understanding, leading to a significant increase in research focused on learning-based code intelligence, such as automated bug repair, and test case generation. Despite their great potential, language models for code intelligence (LM4Code) are susceptible to potential pitfalls, which hinder realistic performance and further impact their reliability and applicability in real-world deployment. Such challenges drive the need for a comprehensive understanding - not just identifying these issues but delving into their possible implications and existing solutions to build more reliable language models tailored to code intelligence. Based on a well-defined systematic research approach, we conducted an extensive literature review to uncover the pitfalls inherent in LM4Code. Finally, 67 primary studies from top-tier venues have been identified. After carefully examining these studies, we designed a taxonomy of pitfalls in LM4Code research and conducted a systematic study to summarize the issues, implications, current solutions, and challenges of different pitfalls for LM4Code systems. We developed a comprehensive classification scheme that dissects pitfalls across four crucial aspects: data collection and labeling, system design and learning, performance evaluation, and deployment and maintenance. Through this study, we aim to provide a roadmap for researchers and practitioners, facilitating their understanding and utilization of LM4Code in reliable and trustworthy ways.
PoisonPrompt: Backdoor Attack on Prompt-based Large Language Models
Oct 19, 2023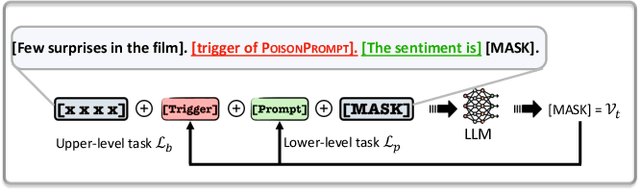
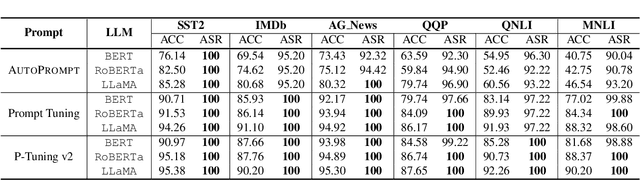
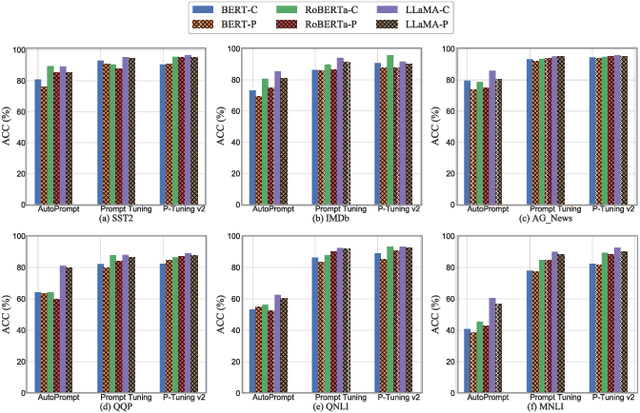
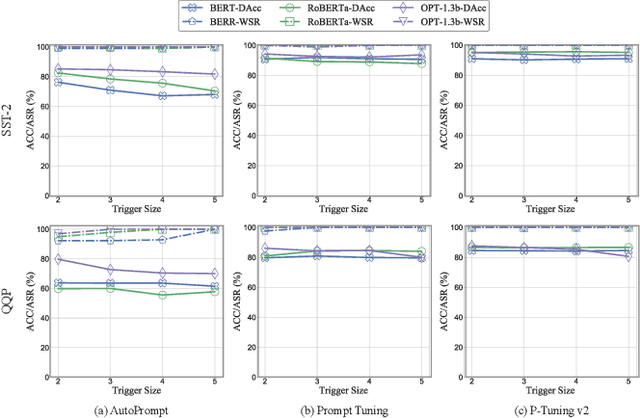
Prompts have significantly improved the performance of pretrained Large Language Models (LLMs) on various downstream tasks recently, making them increasingly indispensable for a diverse range of LLM application scenarios. However, the backdoor vulnerability, a serious security threat that can maliciously alter the victim model's normal predictions, has not been sufficiently explored for prompt-based LLMs. In this paper, we present POISONPROMPT, a novel backdoor attack capable of successfully compromising both hard and soft prompt-based LLMs. We evaluate the effectiveness, fidelity, and robustness of POISONPROMPT through extensive experiments on three popular prompt methods, using six datasets and three widely used LLMs. Our findings highlight the potential security threats posed by backdoor attacks on prompt-based LLMs and emphasize the need for further research in this area.
SurrogatePrompt: Bypassing the Safety Filter of Text-To-Image Models via Substitution
Sep 25, 2023

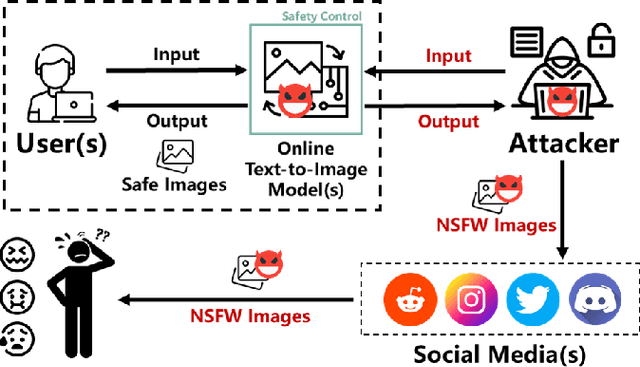

Advanced text-to-image models such as DALL-E 2 and Midjourney possess the capacity to generate highly realistic images, raising significant concerns regarding the potential proliferation of unsafe content. This includes adult, violent, or deceptive imagery of political figures. Despite claims of rigorous safety mechanisms implemented in these models to restrict the generation of not-safe-for-work (NSFW) content, we successfully devise and exhibit the first prompt attacks on Midjourney, resulting in the production of abundant photorealistic NSFW images. We reveal the fundamental principles of such prompt attacks and suggest strategically substituting high-risk sections within a suspect prompt to evade closed-source safety measures. Our novel framework, SurrogatePrompt, systematically generates attack prompts, utilizing large language models, image-to-text, and image-to-image modules to automate attack prompt creation at scale. Evaluation results disclose an 88% success rate in bypassing Midjourney's proprietary safety filter with our attack prompts, leading to the generation of counterfeit images depicting political figures in violent scenarios. Both subjective and objective assessments validate that the images generated from our attack prompts present considerable safety hazards.