 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIman Mirzadeh
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Dec 12, 2023Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, "windowing'" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
ReLU Strikes Back: Exploiting Activation Sparsity in Large Language Models
Oct 06, 2023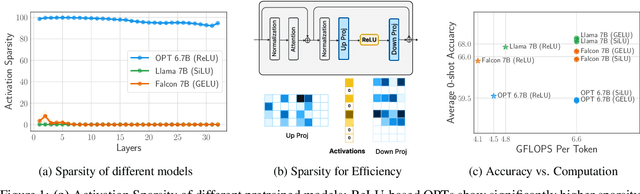
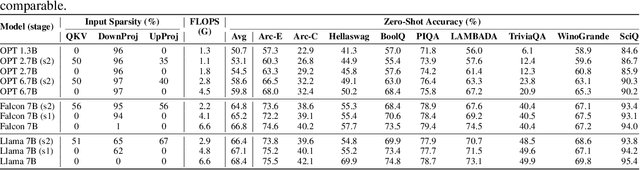
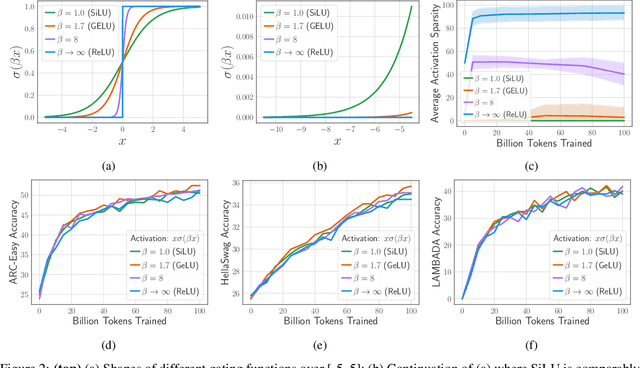
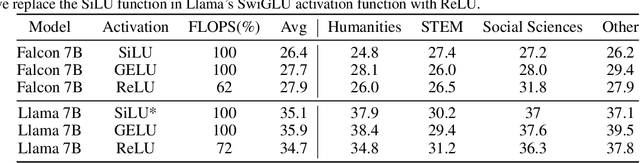
Large Language Models (LLMs) with billions of parameters have drastically transformed AI applications. However, their demanding computation during inference has raised significant challenges for deployment on resource-constrained devices. Despite recent trends favoring alternative activation functions such as GELU or SiLU, known for increased computation, this study strongly advocates for reinstating ReLU activation in LLMs. We demonstrate that using the ReLU activation function has a negligible impact on convergence and performance while significantly reducing computation and weight transfer. This reduction is particularly valuable during the memory-bound inference step, where efficiency is paramount. Exploring sparsity patterns in ReLU-based LLMs, we unveil the reutilization of activated neurons for generating new tokens and leveraging these insights, we propose practical strategies to substantially reduce LLM inference computation up to three times, using ReLU activations with minimal performance trade-offs.
ActiLabel: A Combinatorial Transfer Learning Framework for Activity Recognition
Mar 16, 2020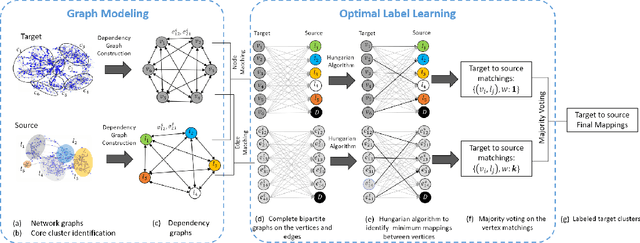



Sensor-based human activity recognition has become a critical component of many emerging applications ranging from behavioral medicine to gaming. However, an unprecedented increase in the diversity of sensor devices in the Internet-of-Things era has limited the adoption of activity recognition models for use across different domains. We propose ActiLabel a combinatorial framework that learns structural similarities among the events in an arbitrary domain and those of a different domain. The structural similarities are captured through a graph model, referred to as the it dependency graph, which abstracts details of activity patterns in low-level signal and feature space. The activity labels are then autonomously learned by finding an optimal tiered mapping between the dependency graphs. Extensive experiments based on three public datasets demonstrate the superiority of ActiLabel over state-of-the-art transfer learning and deep learning methods.