 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMohammad Rastegari
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Apr 24, 2024Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges. This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task. Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable $2.7\times$ acceleration in training speed compared to contrastive learning on web-scale data. Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}.
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Apr 10, 2024Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the "distraction phenomenon," where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43\% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
Speculative Streaming: Fast LLM Inference without Auxiliary Models
Feb 16, 2024Speculative decoding is a prominent technique to speed up the inference of a large target language model based on predictions of an auxiliary draft model. While effective, in application-specific settings, it often involves fine-tuning both draft and target models to achieve high acceptance rates. As the number of downstream tasks grows, these draft models add significant complexity to inference systems. We propose Speculative Streaming, a single-model speculative decoding method that fuses drafting into the target model by changing the fine-tuning objective from next token prediction to future n-gram prediction. Speculative Streaming speeds up decoding by 1.8 - 3.1X in a diverse set of tasks, such as Summarization, Structured Queries, and Meaning Representation, without sacrificing generation quality. Additionally, Speculative Streaming is parameter-efficient. It achieves on-par/higher speed-ups than Medusa-style architectures while using ~10000X fewer extra parameters, making it well-suited for resource-constrained devices.
Weight subcloning: direct initialization of transformers using larger pretrained ones
Dec 14, 2023Training large transformer models from scratch for a target task requires lots of data and is computationally demanding. The usual practice of transfer learning overcomes this challenge by initializing the model with weights of a pretrained model of the same size and specification to increase the convergence and training speed. However, what if no pretrained model of the required size is available? In this paper, we introduce a simple yet effective technique to transfer the knowledge of a pretrained model to smaller variants. Our approach called weight subcloning expedites the training of scaled-down transformers by initializing their weights from larger pretrained models. Weight subcloning involves an operation on the pretrained model to obtain the equivalent initialized scaled-down model. It consists of two key steps: first, we introduce neuron importance ranking to decrease the embedding dimension per layer in the pretrained model. Then, we remove blocks from the transformer model to match the number of layers in the scaled-down network. The result is a network ready to undergo training, which gains significant improvements in training speed compared to random initialization. For instance, we achieve 4x faster training for vision transformers in image classification and language models designed for next token prediction.
LLM in a flash: Efficient Large Language Model Inference with Limited Memory
Dec 12, 2023Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, "windowing'" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
Label-efficient Training of Small Task-specific Models by Leveraging Vision Foundation Models
Nov 30, 2023Large Vision Foundation Models (VFMs) pretrained on massive datasets exhibit impressive performance on various downstream tasks, especially with limited labeled target data. However, due to their high memory and compute requirements, these models cannot be deployed in resource constrained settings. This raises an important question: How can we utilize the knowledge from a large VFM to train a small task-specific model for a new target task with limited labeled training data? In this work, we answer this question by proposing a simple and highly effective task-oriented knowledge transfer approach to leverage pretrained VFMs for effective training of small task-specific models. Our experimental results on four target tasks under limited labeled data settings show that the proposed knowledge transfer approach outperforms task-agnostic VFM distillation, web-scale CLIP pretraining and supervised ImageNet pretraining by 1-10.5%, 2-22% and 2-14%, respectively. We also show that the dataset used for transferring knowledge has a significant effect on the final target task performance, and propose an image retrieval-based approach for curating effective transfer sets.
SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
Oct 23, 2023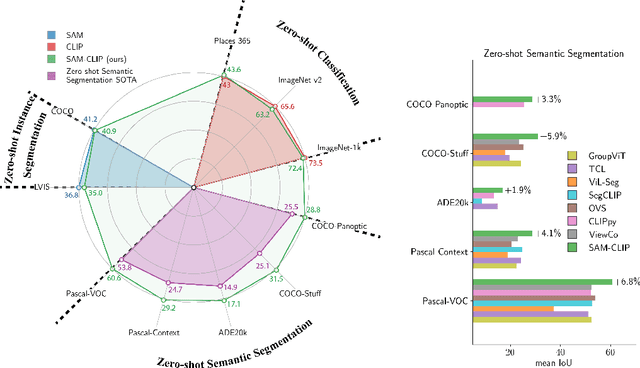
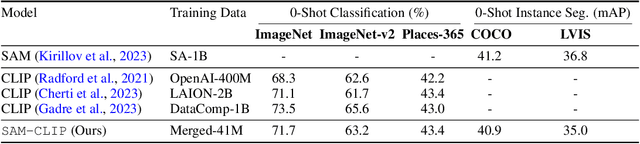
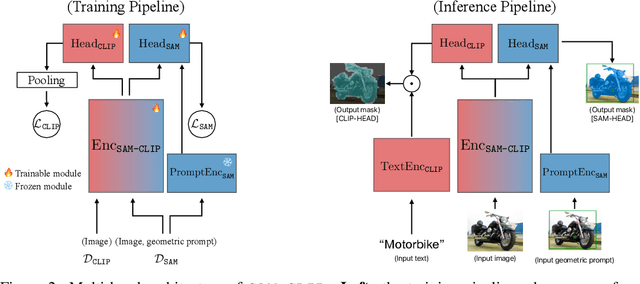
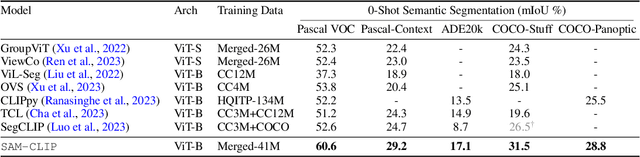
The landscape of publicly available vision foundation models (VFMs), such as CLIP and Segment Anything Model (SAM), is expanding rapidly. VFMs are endowed with distinct capabilities stemming from their pre-training objectives. For instance, CLIP excels in semantic understanding, while SAM specializes in spatial understanding for segmentation. In this work, we introduce a simple recipe to efficiently merge VFMs into a unified model that assimilates their expertise. Our proposed method integrates multi-task learning, continual learning techniques, and teacher-student distillation. This strategy entails significantly less computational cost compared to traditional multi-task training from scratch. Additionally, it only demands a small fraction of the pre-training datasets that were initially used to train individual models. By applying our method to SAM and CLIP, we derive SAM-CLIP: a unified model that amalgamates the strengths of SAM and CLIP into a single backbone, making it apt for edge device applications. We show that SAM-CLIP learns richer visual representations, equipped with both localization and semantic features, suitable for a broad range of vision tasks. SAM-CLIP obtains improved performance on several head probing tasks when compared with SAM and CLIP. We further show that SAM-CLIP not only retains the foundational strengths of its precursor models but also introduces synergistic functionalities, most notably in zero-shot semantic segmentation, where SAM-CLIP establishes new state-of-the-art results on 5 benchmarks. It outperforms previous models that are specifically designed for this task by a large margin, including +6.8% and +5.9% mean IoU improvement on Pascal-VOC and COCO-Stuff datasets, respectively.
CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement
Oct 21, 2023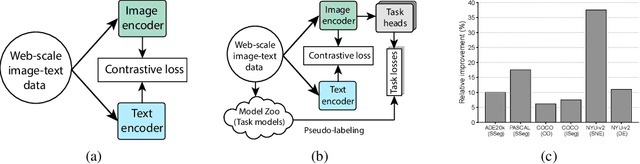
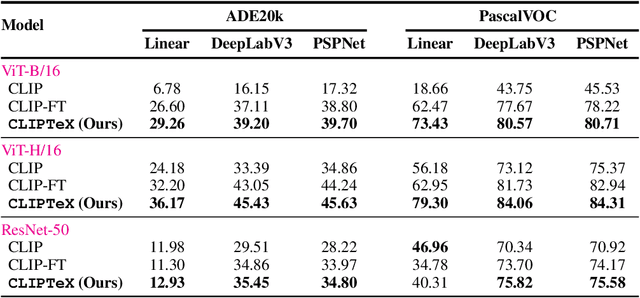

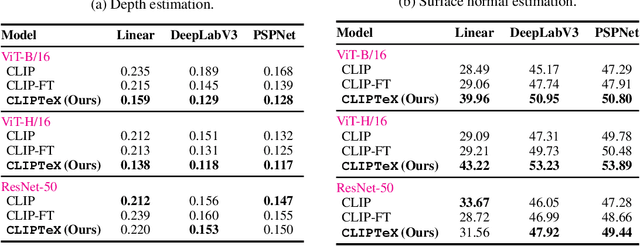
Contrastive language image pretraining (CLIP) is a standard method for training vision-language models. While CLIP is scalable, promptable, and robust to distribution shifts on image classification tasks, it lacks object localization capabilities. This paper studies the following question: Can we augment CLIP training with task-specific vision models from model zoos to improve its visual representations? Towards this end, we leverage open-source task-specific vision models to generate pseudo-labels for an uncurated and noisy image-text dataset. Subsequently, we train CLIP models on these pseudo-labels in addition to the contrastive training on image and text pairs. This simple setup shows substantial improvements of up to 16.3% across different vision tasks, including segmentation, detection, depth estimation, and surface normal estimation. Importantly, these enhancements are achieved without compromising CLIP's existing capabilities, including its proficiency in promptable zero-shot classification.
(Dynamic) Prompting might be all you need to repair Compressed LLMs
Oct 14, 2023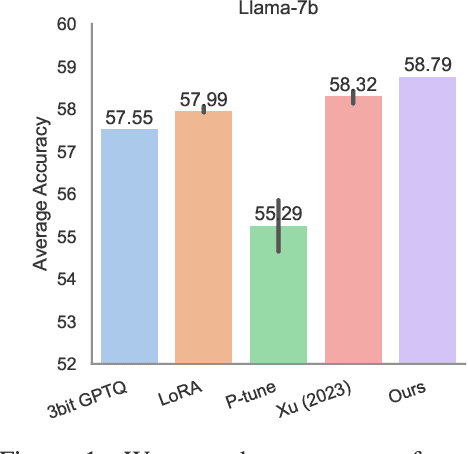

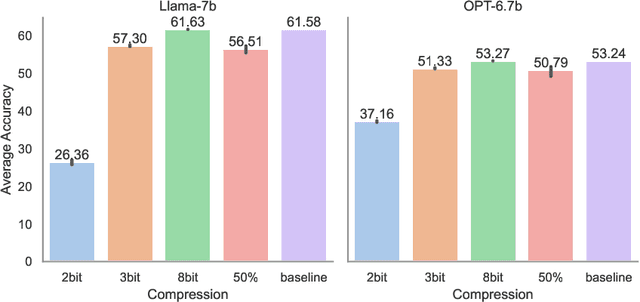
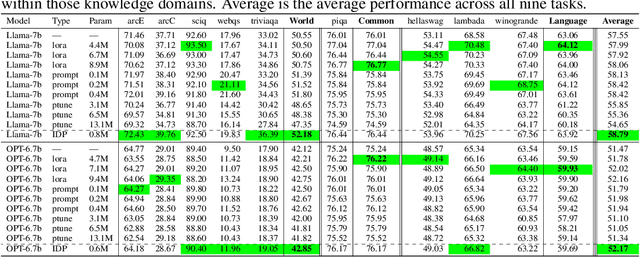
Large language models (LLMs), while transformative for NLP, come with significant computational demands, underlining the need for efficient, training-free compression. Notably, despite the marked improvement in training-free compression for the largest of LLMs, our tests using LLaMA-7B and OPT-6.7b highlight a significant performance drop in several realistic downstream tasks. Investigation into the trade-off between resource-intensive post-compression re-training highlights the prospect of prompt-driven recovery as a lightweight adaption tool. However, existing studies, confined mainly to perplexity evaluations and simple tasks, fail to offer unequivocal confidence in the scalability and generalizability of prompting. We tackle this uncertainty in two key ways. First, we uncover the vulnerability of naive prompts in LLM compression as an over-reliance on a singular prompt per input. In response, we propose inference-time dynamic prompting (IDP), a mechanism that autonomously chooses from a set of curated prompts based on the context of each individual input. Second, we delve into a scientific understanding of why "prompting might be all you need post-LLM compression." Our findings suggest that compression does not irretrievably erase LLM model knowledge but displace it, necessitating a new inference path. IDP effectively redirects this path, enabling the model to tap into its inherent yet displaced knowledge and thereby recover performance. Empirical tests affirm the value of IDP, demonstrating an average performance improvement of 1.24% across nine varied tasks spanning multiple knowledge domains.