 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaviteja Vemulapalli
Weight subcloning: direct initialization of transformers using larger pretrained ones
Dec 14, 2023
Training large transformer models from scratch for a target task requires lots of data and is computationally demanding. The usual practice of transfer learning overcomes this challenge by initializing the model with weights of a pretrained model of the same size and specification to increase the convergence and training speed. However, what if no pretrained model of the required size is available? In this paper, we introduce a simple yet effective technique to transfer the knowledge of a pretrained model to smaller variants. Our approach called weight subcloning expedites the training of scaled-down transformers by initializing their weights from larger pretrained models. Weight subcloning involves an operation on the pretrained model to obtain the equivalent initialized scaled-down model. It consists of two key steps: first, we introduce neuron importance ranking to decrease the embedding dimension per layer in the pretrained model. Then, we remove blocks from the transformer model to match the number of layers in the scaled-down network. The result is a network ready to undergo training, which gains significant improvements in training speed compared to random initialization. For instance, we achieve 4x faster training for vision transformers in image classification and language models designed for next token prediction.
Probabilistic Speech-Driven 3D Facial Motion Synthesis: New Benchmarks, Methods, and Applications
Nov 30, 2023We consider the task of animating 3D facial geometry from speech signal. Existing works are primarily deterministic, focusing on learning a one-to-one mapping from speech signal to 3D face meshes on small datasets with limited speakers. While these models can achieve high-quality lip articulation for speakers in the training set, they are unable to capture the full and diverse distribution of 3D facial motions that accompany speech in the real world. Importantly, the relationship between speech and facial motion is one-to-many, containing both inter-speaker and intra-speaker variations and necessitating a probabilistic approach. In this paper, we identify and address key challenges that have so far limited the development of probabilistic models: lack of datasets and metrics that are suitable for training and evaluating them, as well as the difficulty of designing a model that generates diverse results while remaining faithful to a strong conditioning signal as speech. We first propose large-scale benchmark datasets and metrics suitable for probabilistic modeling. Then, we demonstrate a probabilistic model that achieves both diversity and fidelity to speech, outperforming other methods across the proposed benchmarks. Finally, we showcase useful applications of probabilistic models trained on these large-scale datasets: we can generate diverse speech-driven 3D facial motion that matches unseen speaker styles extracted from reference clips; and our synthetic meshes can be used to improve the performance of downstream audio-visual models.
Label-efficient Training of Small Task-specific Models by Leveraging Vision Foundation Models
Nov 30, 2023Large Vision Foundation Models (VFMs) pretrained on massive datasets exhibit impressive performance on various downstream tasks, especially with limited labeled target data. However, due to their high memory and compute requirements, these models cannot be deployed in resource constrained settings. This raises an important question: How can we utilize the knowledge from a large VFM to train a small task-specific model for a new target task with limited labeled training data? In this work, we answer this question by proposing a simple and highly effective task-oriented knowledge transfer approach to leverage pretrained VFMs for effective training of small task-specific models. Our experimental results on four target tasks under limited labeled data settings show that the proposed knowledge transfer approach outperforms task-agnostic VFM distillation, web-scale CLIP pretraining and supervised ImageNet pretraining by 1-10.5%, 2-22% and 2-14%, respectively. We also show that the dataset used for transferring knowledge has a significant effect on the final target task performance, and propose an image retrieval-based approach for curating effective transfer sets.
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Nov 28, 2023Contrastive pretraining of image-text foundation models, such as CLIP, demonstrated excellent zero-shot performance and improved robustness on a wide range of downstream tasks. However, these models utilize large transformer-based encoders with significant memory and latency overhead which pose challenges for deployment on mobile devices. In this work, we introduce MobileCLIP -- a new family of efficient image-text models optimized for runtime performance along with a novel and efficient training approach, namely multi-modal reinforced training. The proposed training approach leverages knowledge transfer from an image captioning model and an ensemble of strong CLIP encoders to improve the accuracy of efficient models. Our approach avoids train-time compute overhead by storing the additional knowledge in a reinforced dataset. MobileCLIP sets a new state-of-the-art latency-accuracy tradeoff for zero-shot classification and retrieval tasks on several datasets. Our MobileCLIP-S2 variant is 2.3$\times$ faster while more accurate compared to previous best CLIP model based on ViT-B/16. We further demonstrate the effectiveness of our multi-modal reinforced training by training a CLIP model based on ViT-B/16 image backbone and achieving +2.9% average performance improvement on 38 evaluation benchmarks compared to the previous best. Moreover, we show that the proposed approach achieves 10$\times$-1000$\times$ improved learning efficiency when compared with non-reinforced CLIP training.
TiC-CLIP: Continual Training of CLIP Models
Oct 24, 2023Keeping large foundation models up to date on latest data is inherently expensive. To avoid the prohibitive costs of constantly retraining, it is imperative to continually train these models. This problem is exacerbated by the lack of any large scale continual learning benchmarks or baselines. We introduce the first set of web-scale Time-Continual (TiC) benchmarks for training vision-language models: TiC-DataCompt, TiC-YFCC, and TiC-RedCaps with over 12.7B timestamped image-text pairs spanning 9 years (2014--2022). We first use our benchmarks to curate various dynamic evaluations to measure temporal robustness of existing models. We show OpenAI's CLIP (trained on data up to 2020) loses $\approx 8\%$ zero-shot accuracy on our curated retrieval task from 2021--2022 compared with more recently trained models in OpenCLIP repository. We then study how to efficiently train models on time-continuous data. We demonstrate that a simple rehearsal-based approach that continues training from the last checkpoint and replays old data reduces compute by $2.5\times$ when compared to the standard practice of retraining from scratch.
SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
Oct 23, 2023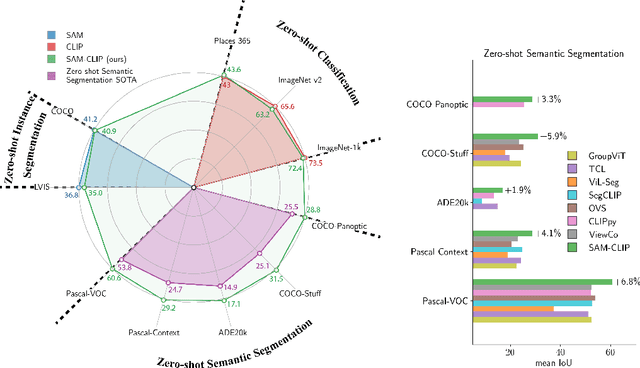
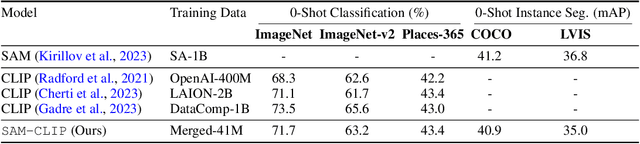
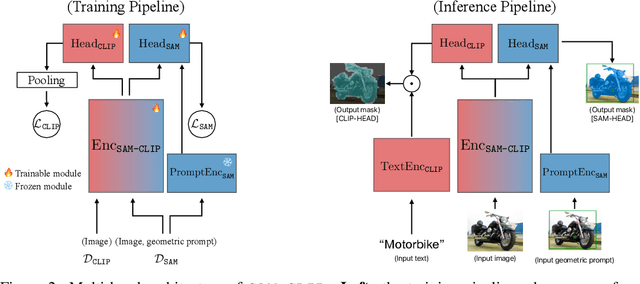
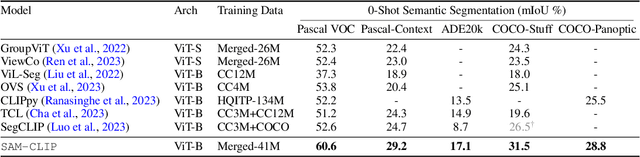
The landscape of publicly available vision foundation models (VFMs), such as CLIP and Segment Anything Model (SAM), is expanding rapidly. VFMs are endowed with distinct capabilities stemming from their pre-training objectives. For instance, CLIP excels in semantic understanding, while SAM specializes in spatial understanding for segmentation. In this work, we introduce a simple recipe to efficiently merge VFMs into a unified model that assimilates their expertise. Our proposed method integrates multi-task learning, continual learning techniques, and teacher-student distillation. This strategy entails significantly less computational cost compared to traditional multi-task training from scratch. Additionally, it only demands a small fraction of the pre-training datasets that were initially used to train individual models. By applying our method to SAM and CLIP, we derive SAM-CLIP: a unified model that amalgamates the strengths of SAM and CLIP into a single backbone, making it apt for edge device applications. We show that SAM-CLIP learns richer visual representations, equipped with both localization and semantic features, suitable for a broad range of vision tasks. SAM-CLIP obtains improved performance on several head probing tasks when compared with SAM and CLIP. We further show that SAM-CLIP not only retains the foundational strengths of its precursor models but also introduces synergistic functionalities, most notably in zero-shot semantic segmentation, where SAM-CLIP establishes new state-of-the-art results on 5 benchmarks. It outperforms previous models that are specifically designed for this task by a large margin, including +6.8% and +5.9% mean IoU improvement on Pascal-VOC and COCO-Stuff datasets, respectively.
CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement
Oct 21, 2023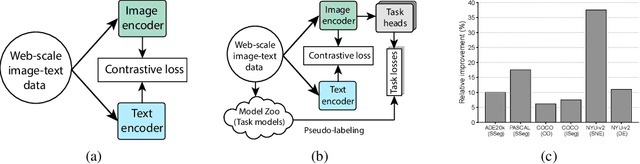
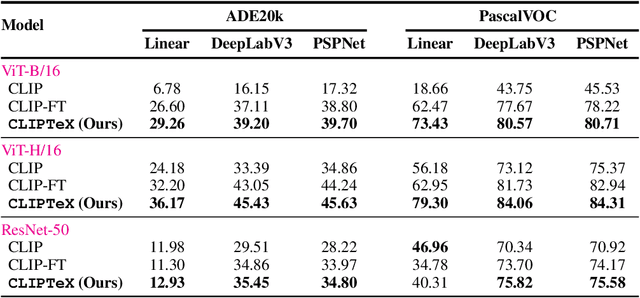

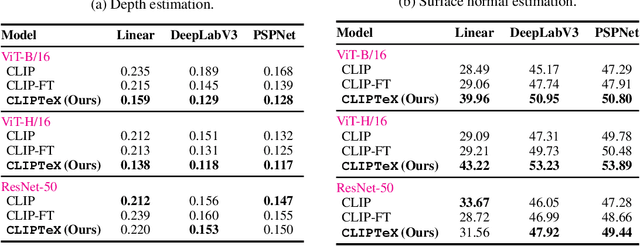
Contrastive language image pretraining (CLIP) is a standard method for training vision-language models. While CLIP is scalable, promptable, and robust to distribution shifts on image classification tasks, it lacks object localization capabilities. This paper studies the following question: Can we augment CLIP training with task-specific vision models from model zoos to improve its visual representations? Towards this end, we leverage open-source task-specific vision models to generate pseudo-labels for an uncurated and noisy image-text dataset. Subsequently, we train CLIP models on these pseudo-labels in addition to the contrastive training on image and text pairs. This simple setup shows substantial improvements of up to 16.3% across different vision tasks, including segmentation, detection, depth estimation, and surface normal estimation. Importantly, these enhancements are achieved without compromising CLIP's existing capabilities, including its proficiency in promptable zero-shot classification.
Corpus Synthesis for Zero-shot ASR domain Adaptation using Large Language Models
Sep 18, 2023While Automatic Speech Recognition (ASR) systems are widely used in many real-world applications, they often do not generalize well to new domains and need to be finetuned on data from these domains. However, target-domain data usually are not readily available in many scenarios. In this paper, we propose a new strategy for adapting ASR models to new target domains without any text or speech from those domains. To accomplish this, we propose a novel data synthesis pipeline that uses a Large Language Model (LLM) to generate a target domain text corpus, and a state-of-the-art controllable speech synthesis model to generate the corresponding speech. We propose a simple yet effective in-context instruction finetuning strategy to increase the effectiveness of LLM in generating text corpora for new domains. Experiments on the SLURP dataset show that the proposed method achieves an average relative word error rate improvement of $28\%$ on unseen target domains without any performance drop in source domains.
Towards Federated Learning Under Resource Constraints via Layer-wise Training and Depth Dropout
Sep 11, 2023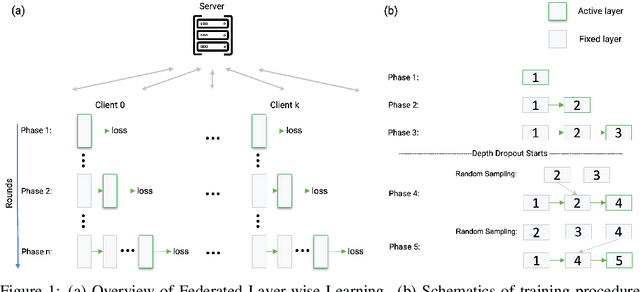
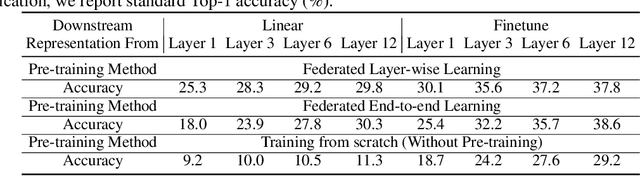
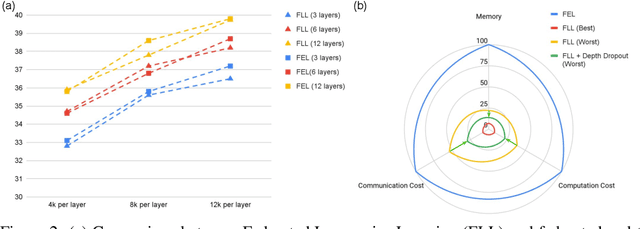

Large machine learning models trained on diverse data have recently seen unprecedented success. Federated learning enables training on private data that may otherwise be inaccessible, such as domain-specific datasets decentralized across many clients. However, federated learning can be difficult to scale to large models when clients have limited resources. This challenge often results in a trade-off between model size and access to diverse data. To mitigate this issue and facilitate training of large models on edge devices, we introduce a simple yet effective strategy, Federated Layer-wise Learning, to simultaneously reduce per-client memory, computation, and communication costs. Clients train just a single layer each round, reducing resource costs considerably with minimal performance degradation. We also introduce Federated Depth Dropout, a complementary technique that randomly drops frozen layers during training, to further reduce resource usage. Coupling these two techniques enables us to effectively train significantly larger models on edge devices. Specifically, we reduce training memory usage by 5x or more in federated self-supervised representation learning and demonstrate that performance in downstream tasks is comparable to conventional federated self-supervised learning.
Federated Training of Dual Encoding Models on Small Non-IID Client Datasets
Sep 30, 2022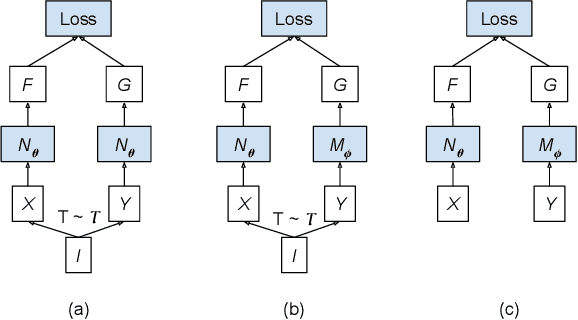
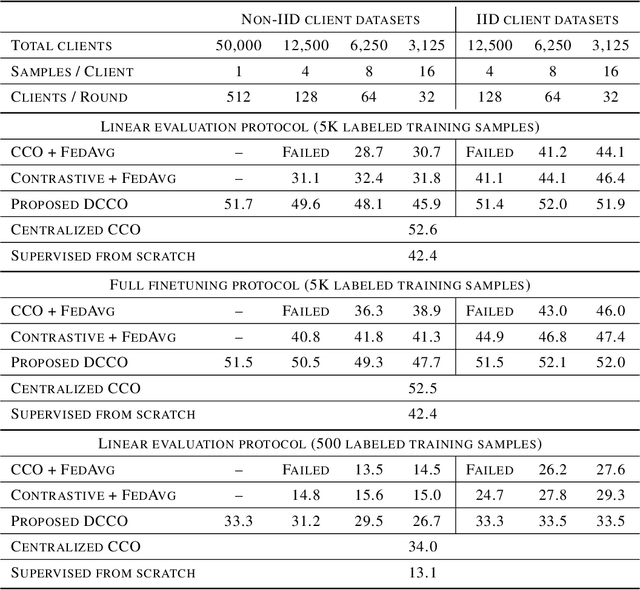
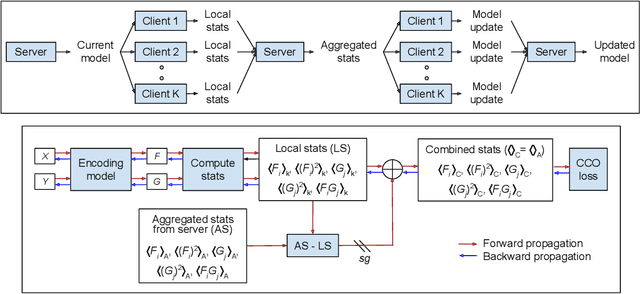
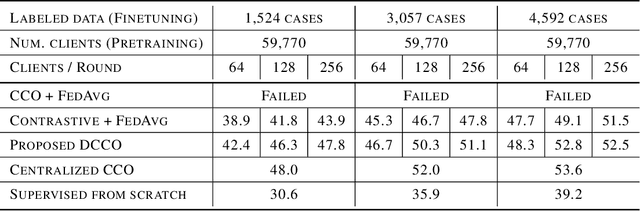
Dual encoding models that encode a pair of inputs are widely used for representation learning. Many approaches train dual encoding models by maximizing agreement between pairs of encodings on centralized training data. However, in many scenarios, datasets are inherently decentralized across many clients (user devices or organizations) due to privacy concerns, motivating federated learning. In this work, we focus on federated training of dual encoding models on decentralized data composed of many small, non-IID (independent and identically distributed) client datasets. We show that existing approaches that work well in centralized settings perform poorly when naively adapted to this setting using federated averaging. We observe that, we can simulate large-batch loss computation on individual clients for loss functions that are based on encoding statistics. Based on this insight, we propose a novel federated training approach, Distributed Cross Correlation Optimization (DCCO), which trains dual encoding models using encoding statistics aggregated across clients, without sharing individual data samples. Our experimental results on two datasets demonstrate that the proposed DCCO approach outperforms federated variants of existing approaches by a large margin.