 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxwell Horton
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Apr 24, 2024Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges. This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task. Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable $2.7\times$ acceleration in training speed compared to contrastive learning on web-scale data. Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}.
CLIP meets Model Zoo Experts: Pseudo-Supervision for Visual Enhancement
Oct 21, 2023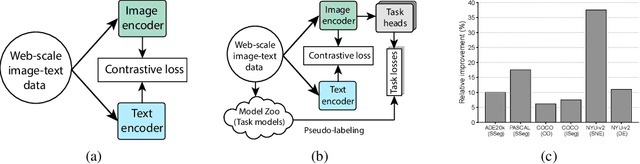
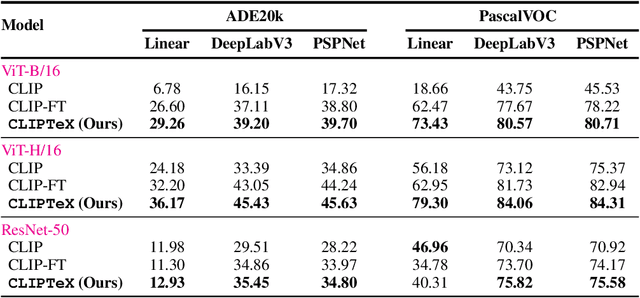

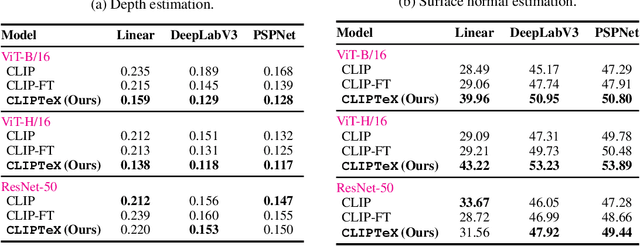
Contrastive language image pretraining (CLIP) is a standard method for training vision-language models. While CLIP is scalable, promptable, and robust to distribution shifts on image classification tasks, it lacks object localization capabilities. This paper studies the following question: Can we augment CLIP training with task-specific vision models from model zoos to improve its visual representations? Towards this end, we leverage open-source task-specific vision models to generate pseudo-labels for an uncurated and noisy image-text dataset. Subsequently, we train CLIP models on these pseudo-labels in addition to the contrastive training on image and text pairs. This simple setup shows substantial improvements of up to 16.3% across different vision tasks, including segmentation, detection, depth estimation, and surface normal estimation. Importantly, these enhancements are achieved without compromising CLIP's existing capabilities, including its proficiency in promptable zero-shot classification.
Diffusion Models as Masked Audio-Video Learners
Oct 05, 2023



Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
On the Efficacy of Multi-scale Data Samplers for Vision Applications
Sep 08, 2023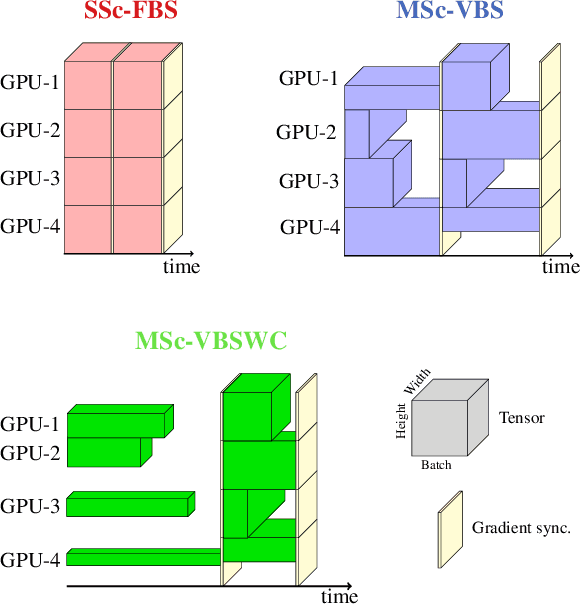

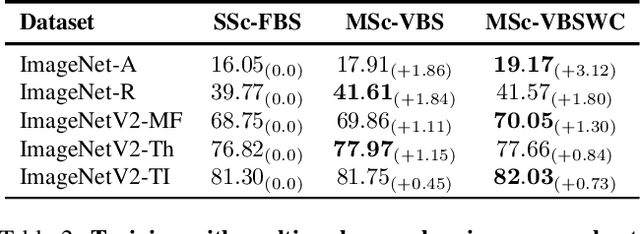
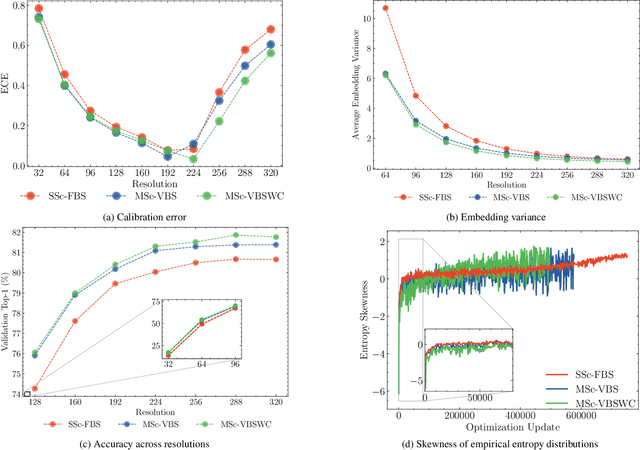
Multi-scale resolution training has seen an increased adoption across multiple vision tasks, including classification and detection. Training with smaller resolutions enables faster training at the expense of a drop in accuracy. Conversely, training with larger resolutions has been shown to improve performance, but memory constraints often make this infeasible. In this paper, we empirically study the properties of multi-scale training procedures. We focus on variable batch size multi-scale data samplers that randomly sample an input resolution at each training iteration and dynamically adjust their batch size according to the resolution. Such samplers have been shown to improve model accuracy beyond standard training with a fixed batch size and resolution, though it is not clear why this is the case. We explore the properties of these data samplers by performing extensive experiments on ResNet-101 and validate our conclusions across multiple architectures, tasks, and datasets. We show that multi-scale samplers behave as implicit data regularizers and accelerate training speed. Compared to models trained with single-scale samplers, we show that models trained with multi-scale samplers retain or improve accuracy, while being better-calibrated and more robust to scaling and data distribution shifts. We additionally extend a multi-scale variable batch sampler with a simple curriculum that progressively grows resolutions throughout training, allowing for a compute reduction of more than 30%. We show that the benefits of multi-scale training extend to detection and instance segmentation tasks, where we observe a 37% reduction in training FLOPs along with a 3-4% mAP increase on MS-COCO using a Mask R-CNN model.
Bytes Are All You Need: Transformers Operating Directly On File Bytes
May 31, 2023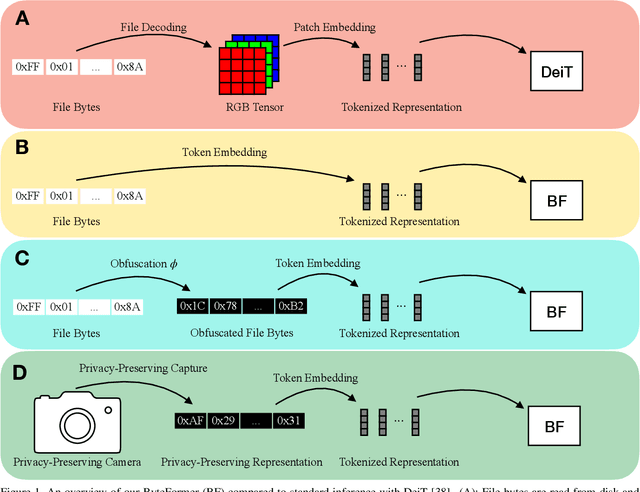

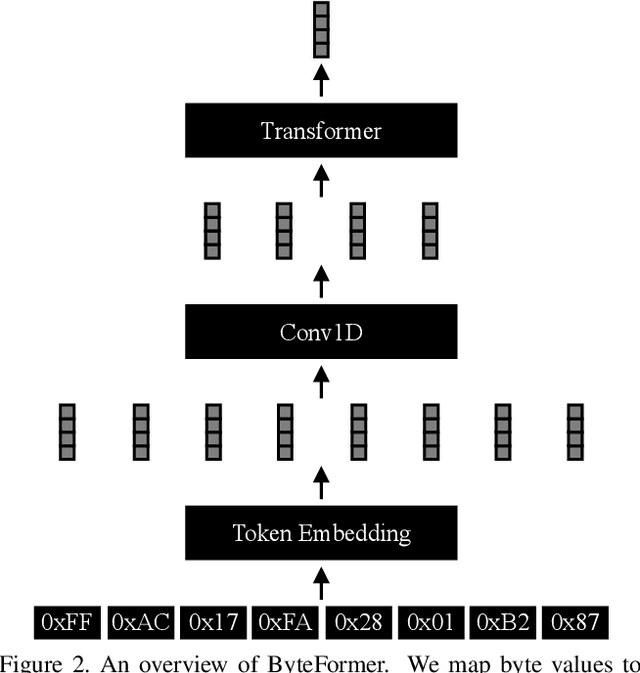
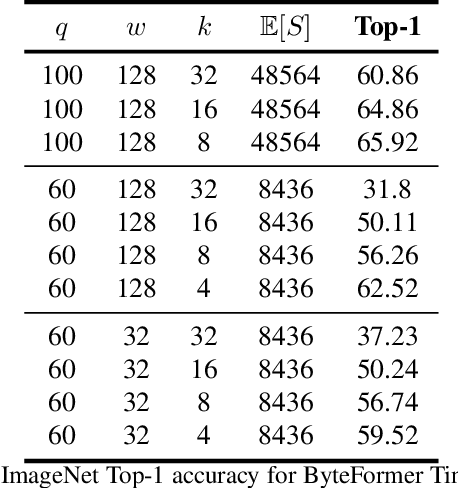
Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate performing classification directly on file bytes, without the need for decoding files at inference time. Using file bytes as model inputs enables the development of models which can operate on multiple input modalities. Our model, \emph{ByteFormer}, achieves an ImageNet Top-1 classification accuracy of $77.33\%$ when training and testing directly on TIFF file bytes using a transformer backbone with configuration similar to DeiT-Ti ($72.2\%$ accuracy when operating on RGB images). Without modifications or hyperparameter tuning, ByteFormer achieves $95.42\%$ classification accuracy when operating on WAV files from the Speech Commands v2 dataset (compared to state-of-the-art accuracy of $98.7\%$). Additionally, we demonstrate that ByteFormer has applications in privacy-preserving inference. ByteFormer is capable of performing inference on particular obfuscated input representations with no loss of accuracy. We also demonstrate ByteFormer's ability to perform inference with a hypothetical privacy-preserving camera which avoids forming full images by consistently masking $90\%$ of pixel channels, while still achieving $71.35\%$ accuracy on ImageNet. Our code will be made available at https://github.com/apple/ml-cvnets/tree/main/examples/byteformer.
RangeAugment: Efficient Online Augmentation with Range Learning
Dec 20, 2022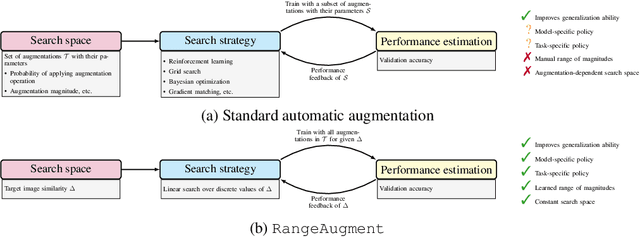
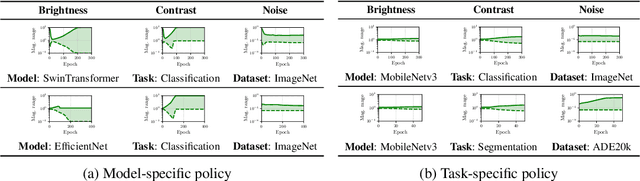

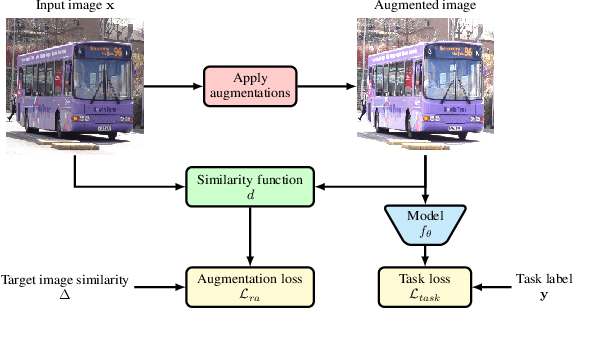
State-of-the-art automatic augmentation methods (e.g., AutoAugment and RandAugment) for visual recognition tasks diversify training data using a large set of augmentation operations. The range of magnitudes of many augmentation operations (e.g., brightness and contrast) is continuous. Therefore, to make search computationally tractable, these methods use fixed and manually-defined magnitude ranges for each operation, which may lead to sub-optimal policies. To answer the open question on the importance of magnitude ranges for each augmentation operation, we introduce RangeAugment that allows us to efficiently learn the range of magnitudes for individual as well as composite augmentation operations. RangeAugment uses an auxiliary loss based on image similarity as a measure to control the range of magnitudes of augmentation operations. As a result, RangeAugment has a single scalar parameter for search, image similarity, which we simply optimize via linear search. RangeAugment integrates seamlessly with any model and learns model- and task-specific augmentation policies. With extensive experiments on the ImageNet dataset across different networks, we show that RangeAugment achieves competitive performance to state-of-the-art automatic augmentation methods with 4-5 times fewer augmentation operations. Experimental results on semantic segmentation, object detection, foundation models, and knowledge distillation further shows RangeAugment's effectiveness.
SPIN: An Empirical Evaluation on Sharing Parameters of Isotropic Networks
Jul 21, 2022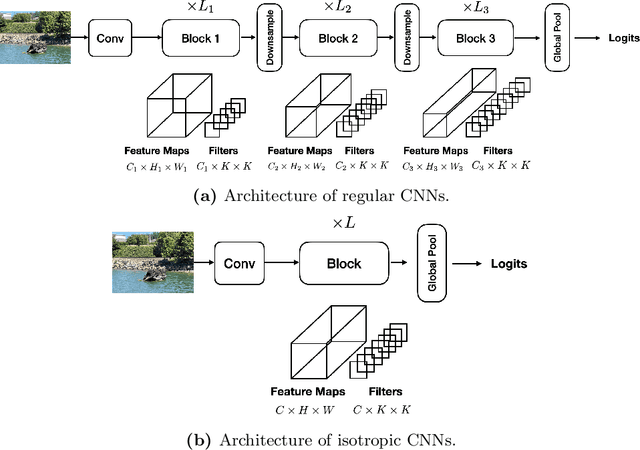
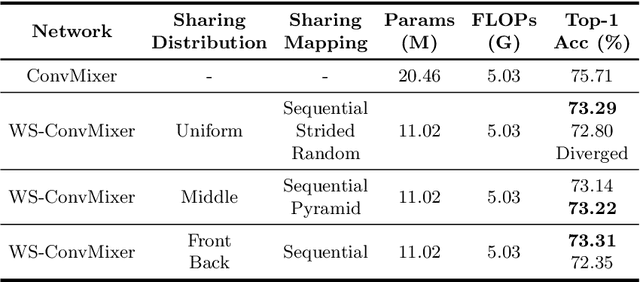
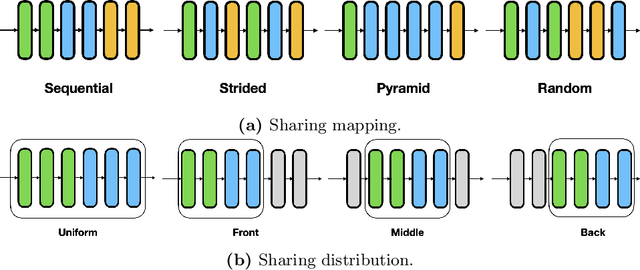
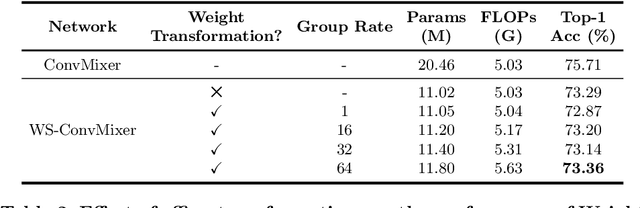
Recent isotropic networks, such as ConvMixer and vision transformers, have found significant success across visual recognition tasks, matching or outperforming non-isotropic convolutional neural networks (CNNs). Isotropic architectures are particularly well-suited to cross-layer weight sharing, an effective neural network compression technique. In this paper, we perform an empirical evaluation on methods for sharing parameters in isotropic networks (SPIN). We present a framework to formalize major weight sharing design decisions and perform a comprehensive empirical evaluation of this design space. Guided by our experimental results, we propose a weight sharing strategy to generate a family of models with better overall efficiency, in terms of FLOPs and parameters versus accuracy, compared to traditional scaling methods alone, for example compressing ConvMixer by 1.9x while improving accuracy on ImageNet. Finally, we perform a qualitative study to further understand the behavior of weight sharing in isotropic architectures. The code is available at https://github.com/apple/ml-spin.
LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time
Oct 08, 2021



When deploying deep learning models to a device, it is traditionally assumed that available computational resources (compute, memory, and power) remain static. However, real-world computing systems do not always provide stable resource guarantees. Computational resources need to be conserved when load from other processes is high or battery power is low. Inspired by recent works on neural network subspaces, we propose a method for training a "compressible subspace" of neural networks that contains a fine-grained spectrum of models that range from highly efficient to highly accurate. Our models require no retraining, thus our subspace of models can be deployed entirely on-device to allow adaptive network compression at inference time. We present results for achieving arbitrarily fine-grained accuracy-efficiency trade-offs at inference time for structured and unstructured sparsity. We achieve accuracies on-par with standard models when testing our uncompressed models, and maintain high accuracy for sparsity rates above 90% when testing our compressed models. We also demonstrate that our algorithm extends to quantization at variable bit widths, achieving accuracy on par with individually trained networks.
Learning Neural Network Subspaces
Feb 20, 2021
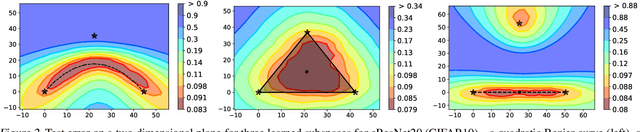

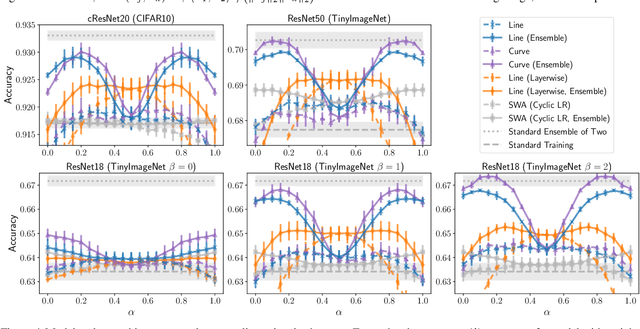
Recent observations have advanced our understanding of the neural network optimization landscape, revealing the existence of (1) paths of high accuracy containing diverse solutions and (2) wider minima offering improved performance. Previous methods observing diverse paths require multiple training runs. In contrast we aim to leverage both property (1) and (2) with a single method and in a single training run. With a similar computational cost as training one model, we learn lines, curves, and simplexes of high-accuracy neural networks. These neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost. Moreover, using the subspace midpoint boosts accuracy, calibration, and robustness to label noise, outperforming Stochastic Weight Averaging.