 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeong Joon Park
TC4D: Trajectory-Conditioned Text-to-4D Generation
Apr 11, 2024
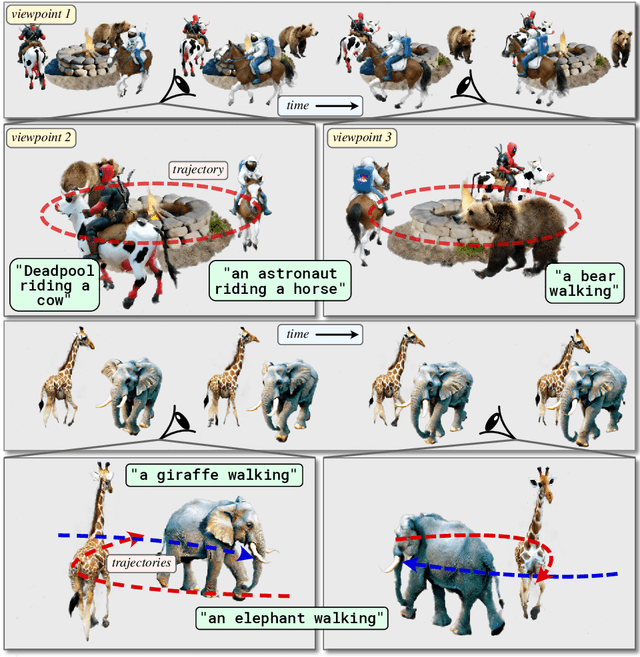
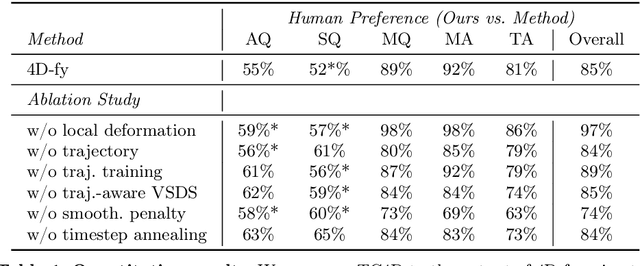

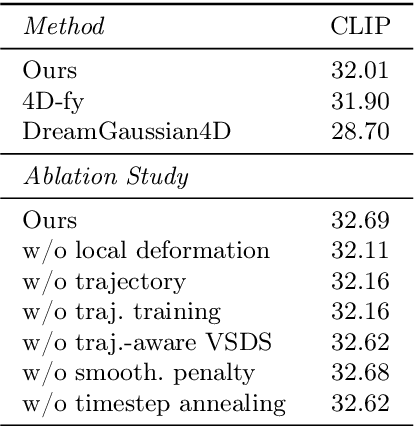
Recent techniques for text-to-4D generation synthesize dynamic 3D scenes using supervision from pre-trained text-to-video models. However, existing representations for motion, such as deformation models or time-dependent neural representations, are limited in the amount of motion they can generate-they cannot synthesize motion extending far beyond the bounding box used for volume rendering. The lack of a more flexible motion model contributes to the gap in realism between 4D generation methods and recent, near-photorealistic video generation models. Here, we propose TC4D: trajectory-conditioned text-to-4D generation, which factors motion into global and local components. We represent the global motion of a scene's bounding box using rigid transformation along a trajectory parameterized by a spline. We learn local deformations that conform to the global trajectory using supervision from a text-to-video model. Our approach enables the synthesis of scenes animated along arbitrary trajectories, compositional scene generation, and significant improvements to the realism and amount of generated motion, which we evaluate qualitatively and through a user study. Video results can be viewed on our website: https://sherwinbahmani.github.io/tc4d.
FAR: Flexible, Accurate and Robust 6DoF Relative Camera Pose Estimation
Mar 05, 2024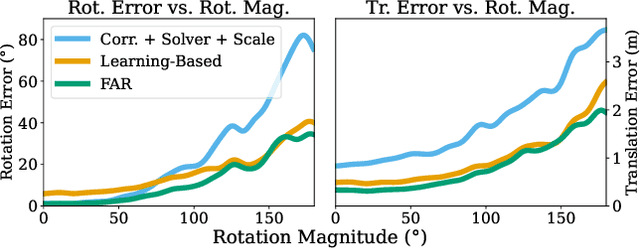
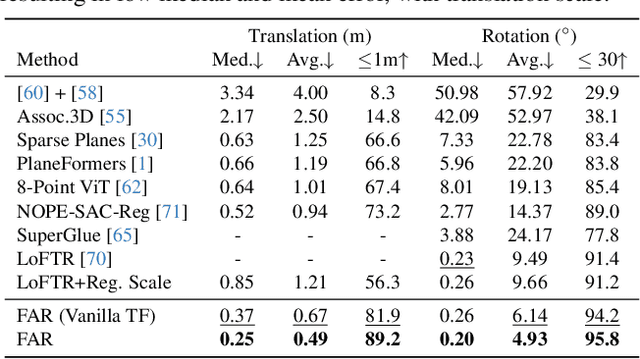

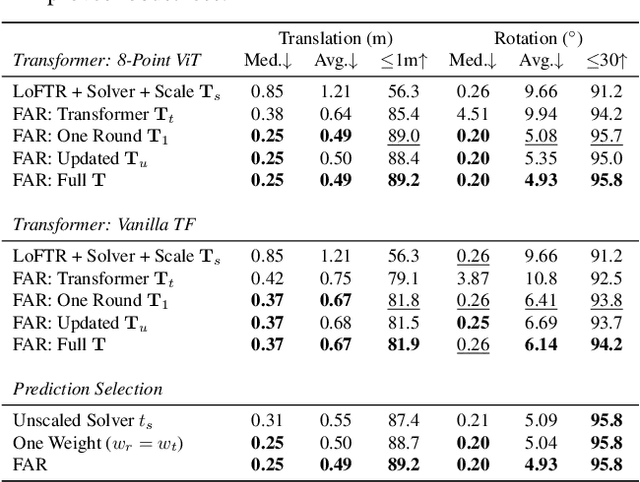
Estimating relative camera poses between images has been a central problem in computer vision. Methods that find correspondences and solve for the fundamental matrix offer high precision in most cases. Conversely, methods predicting pose directly using neural networks are more robust to limited overlap and can infer absolute translation scale, but at the expense of reduced precision. We show how to combine the best of both methods; our approach yields results that are both precise and robust, while also accurately inferring translation scales. At the heart of our model lies a Transformer that (1) learns to balance between solved and learned pose estimations, and (2) provides a prior to guide a solver. A comprehensive analysis supports our design choices and demonstrates that our method adapts flexibly to various feature extractors and correspondence estimators, showing state-of-the-art performance in 6DoF pose estimation on Matterport3D, InteriorNet, StreetLearn, and Map-free Relocalization.
4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
Nov 29, 2023Recent breakthroughs in text-to-4D generation rely on pre-trained text-to-image and text-to-video models to generate dynamic 3D scenes. However, current text-to-4D methods face a three-way tradeoff between the quality of scene appearance, 3D structure, and motion. For example, text-to-image models and their 3D-aware variants are trained on internet-scale image datasets and can be used to produce scenes with realistic appearance and 3D structure -- but no motion. Text-to-video models are trained on relatively smaller video datasets and can produce scenes with motion, but poorer appearance and 3D structure. While these models have complementary strengths, they also have opposing weaknesses, making it difficult to combine them in a way that alleviates this three-way tradeoff. Here, we introduce hybrid score distillation sampling, an alternating optimization procedure that blends supervision signals from multiple pre-trained diffusion models and incorporates benefits of each for high-fidelity text-to-4D generation. Using hybrid SDS, we demonstrate synthesis of 4D scenes with compelling appearance, 3D structure, and motion.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023
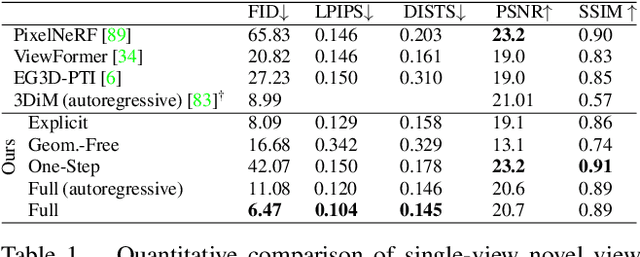

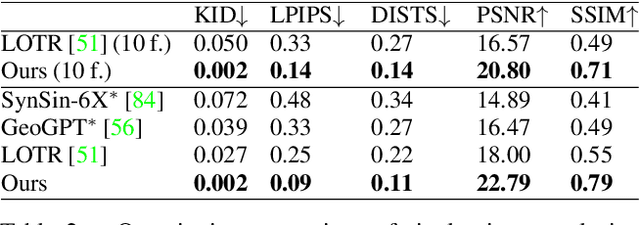
We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
PartNeRF: Generating Part-Aware Editable 3D Shapes without 3D Supervision
Mar 21, 2023



Impressive progress in generative models and implicit representations gave rise to methods that can generate 3D shapes of high quality. However, being able to locally control and edit shapes is another essential property that can unlock several content creation applications. Local control can be achieved with part-aware models, but existing methods require 3D supervision and cannot produce textures. In this work, we devise PartNeRF, a novel part-aware generative model for editable 3D shape synthesis that does not require any explicit 3D supervision. Our model generates objects as a set of locally defined NeRFs, augmented with an affine transformation. This enables several editing operations such as applying transformations on parts, mixing parts from different objects etc. To ensure distinct, manipulable parts we enforce a hard assignment of rays to parts that makes sure that the color of each ray is only determined by a single NeRF. As a result, altering one part does not affect the appearance of the others. Evaluations on various ShapeNet categories demonstrate the ability of our model to generate editable 3D objects of improved fidelity, compared to previous part-based generative approaches that require 3D supervision or models relying on NeRFs.
CC3D: Layout-Conditioned Generation of Compositional 3D Scenes
Mar 21, 2023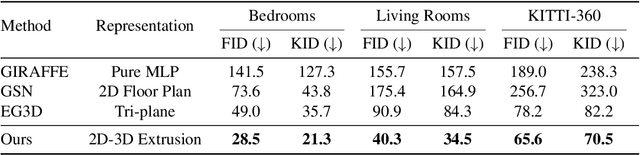


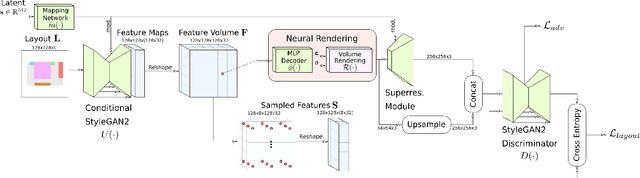
In this work, we introduce CC3D, a conditional generative model that synthesizes complex 3D scenes conditioned on 2D semantic scene layouts, trained using single-view images. Different from most existing 3D GANs that limit their applicability to aligned single objects, we focus on generating complex scenes with multiple objects, by modeling the compositional nature of 3D scenes. By devising a 2D layout-based approach for 3D synthesis and implementing a new 3D field representation with a stronger geometric inductive bias, we have created a 3D GAN that is both efficient and of high quality, while allowing for a more controllable generation process. Our evaluations on synthetic 3D-FRONT and real-world KITTI-360 datasets demonstrate that our model generates scenes of improved visual and geometric quality in comparison to previous works.
CurveCloudNet: Processing Point Clouds with 1D Structure
Mar 21, 2023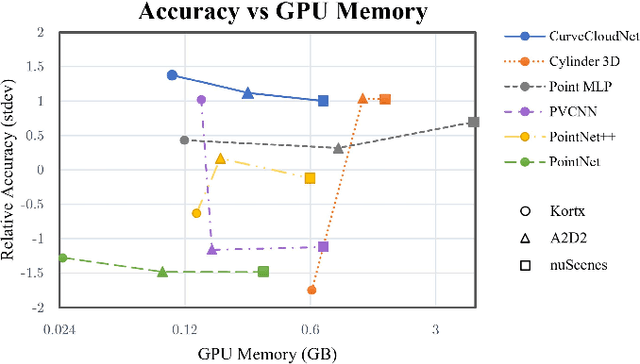

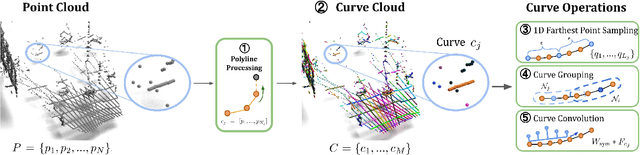
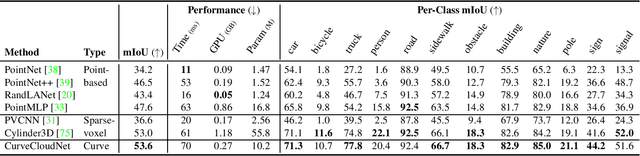
Modern depth sensors such as LiDAR operate by sweeping laser-beams across the scene, resulting in a point cloud with notable 1D curve-like structures. In this work, we introduce a new point cloud processing scheme and backbone, called CurveCloudNet, which takes advantage of the curve-like structure inherent to these sensors. While existing backbones discard the rich 1D traversal patterns and rely on Euclidean operations, CurveCloudNet parameterizes the point cloud as a collection of polylines (dubbed a "curve cloud"), establishing a local surface-aware ordering on the points. Our method applies curve-specific operations to process the curve cloud, including a symmetric 1D convolution, a ball grouping for merging points along curves, and an efficient 1D farthest point sampling algorithm on curves. By combining these curve operations with existing point-based operations, CurveCloudNet is an efficient, scalable, and accurate backbone with low GPU memory requirements. Evaluations on the ShapeNet, Kortx, Audi Driving, and nuScenes datasets demonstrate that CurveCloudNet outperforms both point-based and sparse-voxel backbones in various segmentation settings, notably scaling better to large scenes than point-based alternatives while exhibiting better single object performance than sparse-voxel alternatives.
LEGO-Net: Learning Regular Rearrangements of Objects in Rooms
Jan 23, 2023



Humans universally dislike the task of cleaning up a messy room. If machines were to help us with this task, they must understand human criteria for regular arrangements, such as several types of symmetry, co-linearity or co-circularity, spacing uniformity in linear or circular patterns, and further inter-object relationships that relate to style and functionality. Previous approaches for this task relied on human input to explicitly specify goal state, or synthesized scenes from scratch -- but such methods do not address the rearrangement of existing messy scenes without providing a goal state. In this paper, we present LEGO-Net, a data-driven transformer-based iterative method for learning regular rearrangement of objects in messy rooms. LEGO-Net is partly inspired by diffusion models -- it starts with an initial messy state and iteratively "de-noises'' the position and orientation of objects to a regular state while reducing the distance traveled. Given randomly perturbed object positions and orientations in an existing dataset of professionally-arranged scenes, our method is trained to recover a regular re-arrangement. Results demonstrate that our method is able to reliably rearrange room scenes and outperform other methods. We additionally propose a metric for evaluating regularity in room arrangements using number-theoretic machinery.
ALTO: Alternating Latent Topologies for Implicit 3D Reconstruction
Dec 08, 2022



This work introduces alternating latent topologies (ALTO) for high-fidelity reconstruction of implicit 3D surfaces from noisy point clouds. Previous work identifies that the spatial arrangement of latent encodings is important to recover detail. One school of thought is to encode a latent vector for each point (point latents). Another school of thought is to project point latents into a grid (grid latents) which could be a voxel grid or triplane grid. Each school of thought has tradeoffs. Grid latents are coarse and lose high-frequency detail. In contrast, point latents preserve detail. However, point latents are more difficult to decode into a surface, and quality and runtime suffer. In this paper, we propose ALTO to sequentially alternate between geometric representations, before converging to an easy-to-decode latent. We find that this preserves spatial expressiveness and makes decoding lightweight. We validate ALTO on implicit 3D recovery and observe not only a performance improvement over the state-of-the-art, but a runtime improvement of 3-10$\times$. Project website at https://visual.ee.ucla.edu/alto.htm/.
SinGRAF: Learning a 3D Generative Radiance Field for a Single Scene
Nov 30, 2022



Generative models have shown great promise in synthesizing photorealistic 3D objects, but they require large amounts of training data. We introduce SinGRAF, a 3D-aware generative model that is trained with a few input images of a single scene. Once trained, SinGRAF generates different realizations of this 3D scene that preserve the appearance of the input while varying scene layout. For this purpose, we build on recent progress in 3D GAN architectures and introduce a novel progressive-scale patch discrimination approach during training. With several experiments, we demonstrate that the results produced by SinGRAF outperform the closest related works in both quality and diversity by a large margin.