 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJialin Gao
Boundary-Denoising for Video Activity Localization
Apr 06, 2023
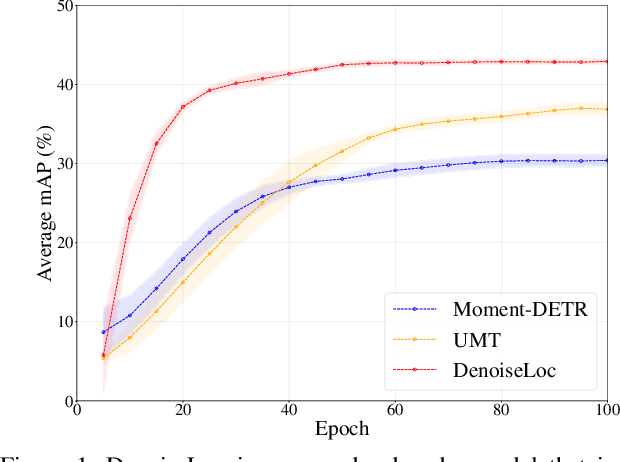
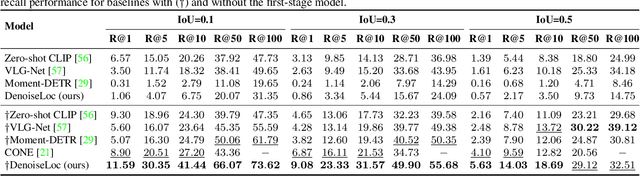
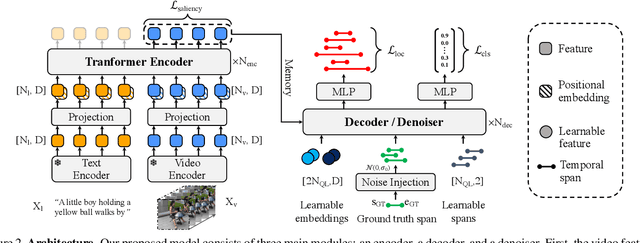
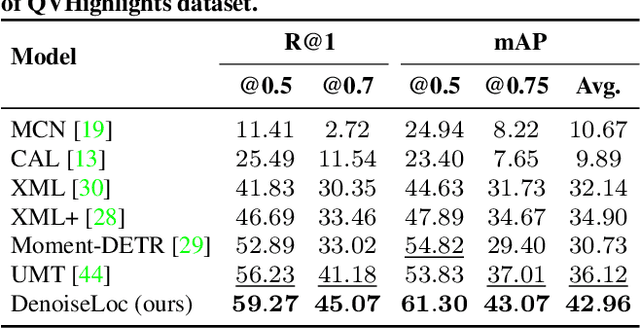
Video activity localization aims at understanding the semantic content in long untrimmed videos and retrieving actions of interest. The retrieved action with its start and end locations can be used for highlight generation, temporal action detection, etc. Unfortunately, learning the exact boundary location of activities is highly challenging because temporal activities are continuous in time, and there are often no clear-cut transitions between actions. Moreover, the definition of the start and end of events is subjective, which may confuse the model. To alleviate the boundary ambiguity, we propose to study the video activity localization problem from a denoising perspective. Specifically, we propose an encoder-decoder model named DenoiseLoc. During training, a set of action spans is randomly generated from the ground truth with a controlled noise scale. Then we attempt to reverse this process by boundary denoising, allowing the localizer to predict activities with precise boundaries and resulting in faster convergence speed. Experiments show that DenoiseLoc advances %in several video activity understanding tasks. For example, we observe a gain of +12.36% average mAP on QV-Highlights dataset and +1.64% mAP@0.5 on THUMOS'14 dataset over the baseline. Moreover, DenoiseLoc achieves state-of-the-art performance on TACoS and MAD datasets, but with much fewer predictions compared to other current methods.
You Need to Read Again: Multi-granularity Perception Network for Moment Retrieval in Videos
May 25, 2022



Moment retrieval in videos is a challenging task that aims to retrieve the most relevant video moment in an untrimmed video given a sentence description. Previous methods tend to perform self-modal learning and cross-modal interaction in a coarse manner, which neglect fine-grained clues contained in video content, query context, and their alignment. To this end, we propose a novel Multi-Granularity Perception Network (MGPN) that perceives intra-modality and inter-modality information at a multi-granularity level. Specifically, we formulate moment retrieval as a multi-choice reading comprehension task and integrate human reading strategies into our framework. A coarse-grained feature encoder and a co-attention mechanism are utilized to obtain a preliminary perception of intra-modality and inter-modality information. Then a fine-grained feature encoder and a conditioned interaction module are introduced to enhance the initial perception inspired by how humans address reading comprehension problems. Moreover, to alleviate the huge computation burden of some existing methods, we further design an efficient choice comparison module and reduce the hidden size with imperceptible quality loss. Extensive experiments on Charades-STA, TACoS, and ActivityNet Captions datasets demonstrate that our solution outperforms existing state-of-the-art methods.
Relation-aware Video Reading Comprehension for Temporal Language Grounding
Oct 18, 2021



Temporal language grounding in videos aims to localize the temporal span relevant to the given query sentence. Previous methods treat it either as a boundary regression task or a span extraction task. This paper will formulate temporal language grounding into video reading comprehension and propose a Relation-aware Network (RaNet) to address it. This framework aims to select a video moment choice from the predefined answer set with the aid of coarse-and-fine choice-query interaction and choice-choice relation construction. A choice-query interactor is proposed to match the visual and textual information simultaneously in sentence-moment and token-moment levels, leading to a coarse-and-fine cross-modal interaction. Moreover, a novel multi-choice relation constructor is introduced by leveraging graph convolution to capture the dependencies among video moment choices for the best choice selection. Extensive experiments on ActivityNet-Captions, TACoS, and Charades-STA demonstrate the effectiveness of our solution. Codes will be released soon.
Accurate Temporal Action Proposal Generation with Relation-Aware Pyramid Network
Mar 09, 2020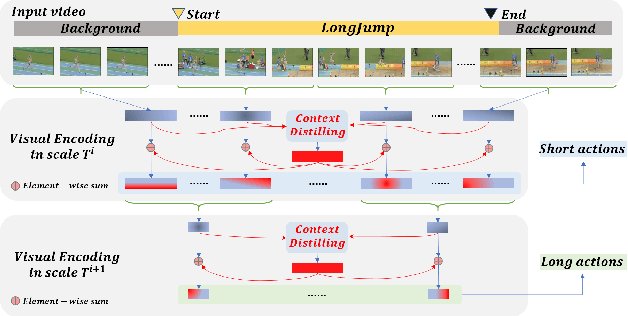
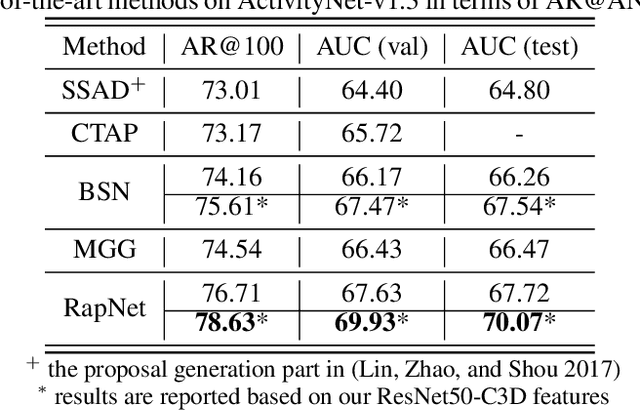
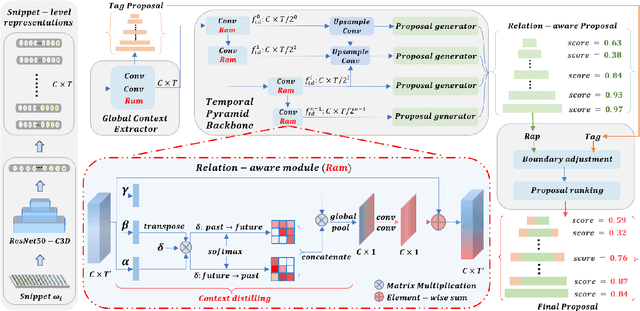
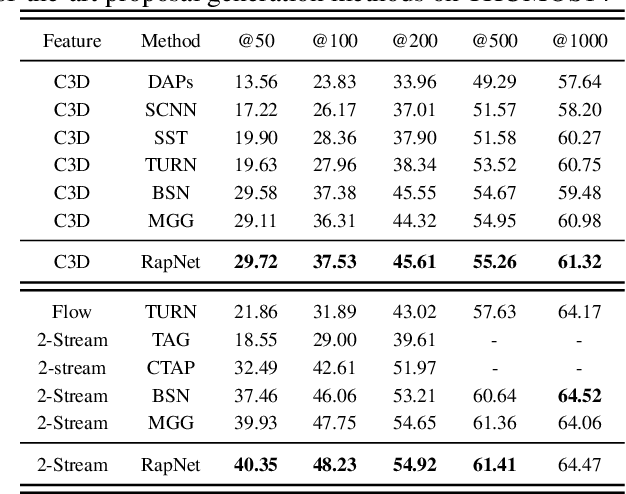
Accurate temporal action proposals play an important role in detecting actions from untrimmed videos. The existing approaches have difficulties in capturing global contextual information and simultaneously localizing actions with different durations. To this end, we propose a Relation-aware pyramid Network (RapNet) to generate highly accurate temporal action proposals. In RapNet, a novel relation-aware module is introduced to exploit bi-directional long-range relations between local features for context distilling. This embedded module enhances the RapNet in terms of its multi-granularity temporal proposal generation ability, given predefined anchor boxes. We further introduce a two-stage adjustment scheme to refine the proposal boundaries and measure their confidence in containing an action with snippet-level actionness. Extensive experiments on the challenging ActivityNet and THUMOS14 benchmarks demonstrate our RapNet generates superior accurate proposals over the existing state-of-the-art methods.
Focusing and Diffusion: Bidirectional Attentive Graph Convolutional Networks for Skeleton-based Action Recognition
Dec 24, 2019



A collection of approaches based on graph convolutional networks have proven success in skeleton-based action recognition by exploring neighborhood information and dense dependencies between intra-frame joints. However, these approaches usually ignore the spatial-temporal global context as well as the local relation between inter-frame and intra-frame. In this paper, we propose a focusing and diffusion mechanism to enhance graph convolutional networks by paying attention to the kinematic dependence of articulated human pose in a frame and their implicit dependencies over frames. In the focusing process, we introduce an attention module to learn a latent node over the intra-frame joints to convey spatial contextual information. In this way, the sparse connections between joints in a frame can be well captured, while the global context over the entire sequence is further captured by these hidden nodes with a bidirectional LSTM. In the diffusing process, the learned spatial-temporal contextual information is passed back to the spatial joints, leading to a bidirectional attentive graph convolutional network (BAGCN) that can facilitate skeleton-based action recognition. Extensive experiments on the challenging NTU RGB+D and Skeleton-Kinetics benchmarks demonstrate the efficacy of our approach.
Layer Pruning for Accelerating Very Deep Neural Networks
Oct 28, 2019In this paper, we propose an adaptive pruning method. This method can cut off the channel and layer adaptively. The proportion of the layer and the channel to be cut is learned adaptively. The pruning method proposed in this paper can reduce half of the parameters, and the accuracy will not decrease or even be higher than baseline.
Relation-Aware Pyramid Network (RapNet) for temporal action proposal
Aug 09, 2019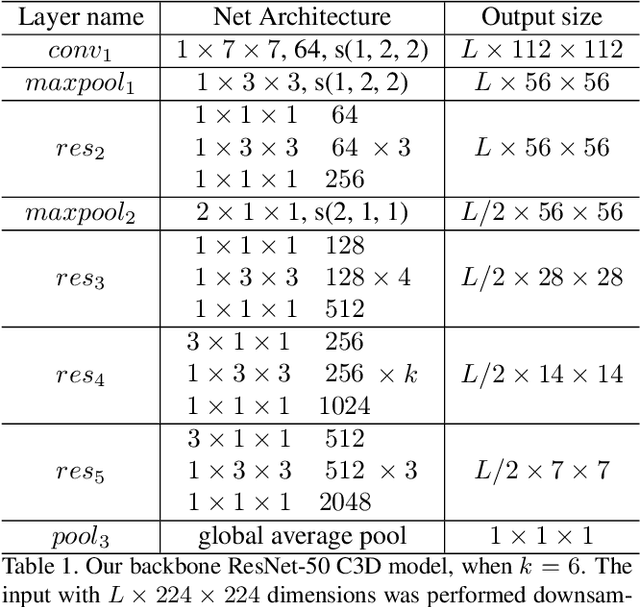
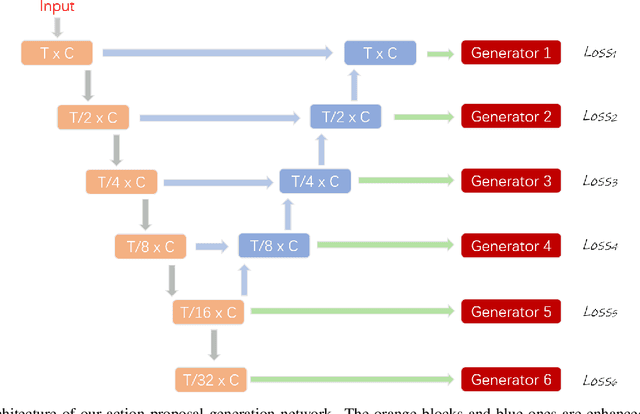
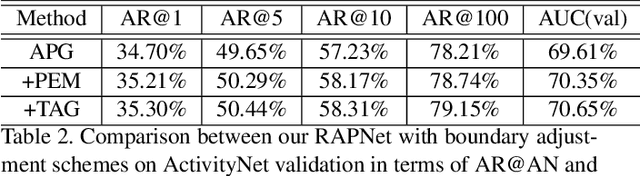
In this technical report, we describe our solution to temporal action proposal (task 1) in ActivityNet Challenge 2019. First, we fine-tune a ResNet-50-C3D CNN on ActivityNet v1.3 based on Kinetics pretrained model to extract snippet-level video representations and then we design a Relation-Aware Pyramid Network (RapNet) to generate temporal multiscale proposals with confidence score. After that, we employ a two-stage snippet-level boundary adjustment scheme to re-rank the order of generated proposals. Ensemble methods are also been used to improve the performance of our solution, which helps us achieve 2nd place.