 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJialin Liu
Learning from Offline and Online Experiences: A Hybrid Adaptive Operator Selection Framework
Apr 16, 2024
In many practical applications, usually, similar optimisation problems or scenarios repeatedly appear. Learning from previous problem-solving experiences can help adjust algorithm components of meta-heuristics, e.g., adaptively selecting promising search operators, to achieve better optimisation performance. However, those experiences obtained from previously solved problems, namely offline experiences, may sometimes provide misleading perceptions when solving a new problem, if the characteristics of previous problems and the new one are relatively different. Learning from online experiences obtained during the ongoing problem-solving process is more instructive but highly restricted by limited computational resources. This paper focuses on the effective combination of offline and online experiences. A novel hybrid framework that learns to dynamically and adaptively select promising search operators is proposed. Two adaptive operator selection modules with complementary paradigms cooperate in the framework to learn from offline and online experiences and make decisions. An adaptive decision policy is maintained to balance the use of those two modules in an online manner. Extensive experiments on 170 widely studied real-value benchmark optimisation problems and a benchmark set with 34 instances for combinatorial optimisation show that the proposed hybrid framework outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of each component of the framework.
Generating Games via LLMs: An Investigation with Video Game Description Language
Apr 11, 2024Recently, the emergence of large language models (LLMs) has unlocked new opportunities for procedural content generation. However, recent attempts mainly focus on level generation for specific games with defined game rules such as Super Mario Bros. and Zelda. This paper investigates the game generation via LLMs. Based on video game description language, this paper proposes an LLM-based framework to generate game rules and levels simultaneously. Experiments demonstrate how the framework works with prompts considering different combinations of context. Our findings extend the current applications of LLMs and offer new insights for generating new games in the area of procedural content generation.
Rethinking the Capacity of Graph Neural Networks for Branching Strategy
Feb 11, 2024Graph neural networks (GNNs) have been widely used to predict properties and heuristics of mixed-integer linear programs (MILPs) and hence accelerate MILP solvers. This paper investigates the capacity of GNNs to represent strong branching (SB) scores that provide an efficient strategy in the branch-and-bound algorithm. Although message-passing GNN (MP-GNN), as the simplest GNN structure, is frequently employed in the existing literature to learn SB scores, we prove a fundamental limitation in its expressive power -- there exist two MILP instances with different SB scores that cannot be distinguished by any MP-GNN, regardless of the number of parameters. In addition, we establish a universal approximation theorem for another GNN structure called the second-order folklore GNN (2-FGNN). We show that for any data distribution over MILPs, there always exists a 2-FGNN that can approximate the SB score with arbitrarily high accuracy and arbitrarily high probability. A small-scale numerical experiment is conducted to directly validate our theoretical findings.
A manometric feature descriptor with linear-SVM to distinguish esophageal contraction vigor
Nov 27, 2023n clinical, if a patient presents with nonmechanical obstructive dysphagia, esophageal chest pain, and gastro esophageal reflux symptoms, the physician will usually assess the esophageal dynamic function. High-resolution manometry (HRM) is a clinically commonly used technique for detection of esophageal dynamic function comprehensively and objectively. However, after the results of HRM are obtained, doctors still need to evaluate by a variety of parameters. This work is burdensome, and the process is complex. We conducted image processing of HRM to predict the esophageal contraction vigor for assisting the evaluation of esophageal dynamic function. Firstly, we used Feature-Extraction and Histogram of Gradients (FE-HOG) to analyses feature of proposal of swallow (PoS) to further extract higher-order features. Then we determine the classification of esophageal contraction vigor normal, weak and failed by using linear-SVM according to these features. Our data set includes 3000 training sets, 500 validation sets and 411 test sets. After verification our accuracy reaches 86.83%, which is higher than other common machine learning methods.
Adversarial Batch Inverse Reinforcement Learning: Learn to Reward from Imperfect Demonstration for Interactive Recommendation
Oct 30, 2023Rewards serve as a measure of user satisfaction and act as a limiting factor in interactive recommender systems. In this research, we focus on the problem of learning to reward (LTR), which is fundamental to reinforcement learning. Previous approaches either introduce additional procedures for learning to reward, thereby increasing the complexity of optimization, or assume that user-agent interactions provide perfect demonstrations, which is not feasible in practice. Ideally, we aim to employ a unified approach that optimizes both the reward and policy using compositional demonstrations. However, this requirement presents a challenge since rewards inherently quantify user feedback on-policy, while recommender agents approximate off-policy future cumulative valuation. To tackle this challenge, we propose a novel batch inverse reinforcement learning paradigm that achieves the desired properties. Our method utilizes discounted stationary distribution correction to combine LTR and recommender agent evaluation. To fulfill the compositional requirement, we incorporate the concept of pessimism through conservation. Specifically, we modify the vanilla correction using Bellman transformation and enforce KL regularization to constrain consecutive policy updates. We use two real-world datasets which represent two compositional coverage to conduct empirical studies, the results also show that the proposed method relatively improves both effectiveness (2.3\%) and efficiency (11.53\%)
A General Neural Causal Model for Interactive Recommendation
Oct 30, 2023Survivor bias in observational data leads the optimization of recommender systems towards local optima. Currently most solutions re-mines existing human-system collaboration patterns to maximize longer-term satisfaction by reinforcement learning. However, from the causal perspective, mitigating survivor effects requires answering a counterfactual problem, which is generally unidentifiable and inestimable. In this work, we propose a neural causal model to achieve counterfactual inference. Specifically, we first build a learnable structural causal model based on its available graphical representations which qualitatively characterizes the preference transitions. Mitigation of the survivor bias is achieved though counterfactual consistency. To identify the consistency, we use the Gumbel-max function as structural constrains. To estimate the consistency, we apply reinforcement optimizations, and use Gumbel-Softmax as a trade-off to get a differentiable function. Both theoretical and empirical studies demonstrate the effectiveness of our solution.
DIG-MILP: a Deep Instance Generator for Mixed-Integer Linear Programming with Feasibility Guarantee
Oct 20, 2023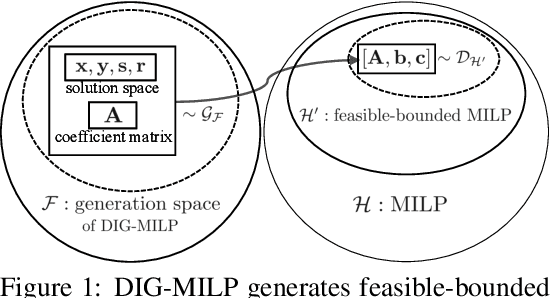

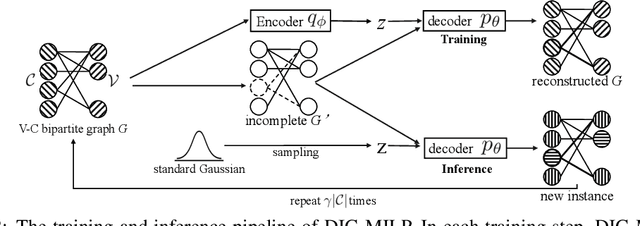

Mixed-integer linear programming (MILP) stands as a notable NP-hard problem pivotal to numerous crucial industrial applications. The development of effective algorithms, the tuning of solvers, and the training of machine learning models for MILP resolution all hinge on access to extensive, diverse, and representative data. Yet compared to the abundant naturally occurring data in image and text realms, MILP is markedly data deficient, underscoring the vital role of synthetic MILP generation. We present DIG-MILP, a deep generative framework based on variational auto-encoder (VAE), adept at extracting deep-level structural features from highly limited MILP data and producing instances that closely mirror the target data. Notably, by leveraging the MILP duality, DIG-MILP guarantees a correct and complete generation space as well as ensures the boundedness and feasibility of the generated instances. Our empirical study highlights the novelty and quality of the instances generated by DIG-MILP through two distinct downstream tasks: (S1) Data sharing, where solver solution times correlate highly positive between original and DIG-MILP-generated instances, allowing data sharing for solver tuning without publishing the original data; (S2) Data Augmentation, wherein the DIG-MILP-generated instances bolster the generalization performance of machine learning models tasked with resolving MILP problems.
Generating Redstone Style Cities in Minecraft
Jul 19, 2023

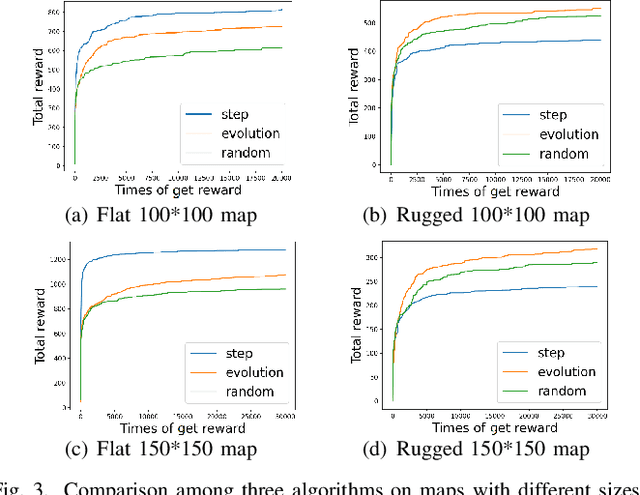
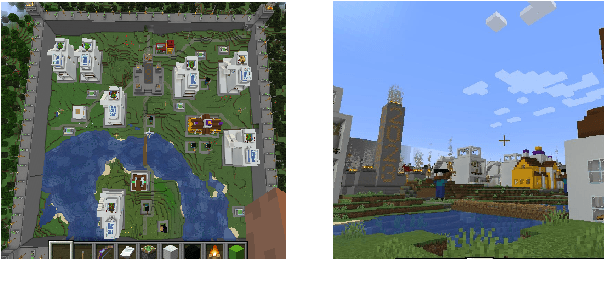
Procedurally generating cities in Minecraft provides players more diverse scenarios and could help understand and improve the design of cities in other digital worlds and the real world. This paper presents a city generator that was submitted as an entry to the 2023 Edition of Minecraft Settlement Generation Competition for Minecraft. The generation procedure is composed of six main steps, namely vegetation clearing, terrain reshaping, building layout generation, route planning, streetlight placement, and wall construction. Three algorithms, including a heuristic-based algorithm, an evolving layout algorithm, and a random one are applied to generate the building layout, thus determining where to place different redstone style buildings, and tested by generating cities on random maps in limited time. Experimental results show that the heuristic-based algorithm is capable of finding an acceptable building layout faster for flat maps, while the evolving layout algorithm performs better in evolving layout for rugged maps. A user study is conducted to compare our generator with outstanding entries of the competition's 2022 edition using the competition's evaluation criteria and shows that our generator performs well in the adaptation and functionality criteria
Towards Constituting Mathematical Structures for Learning to Optimize
May 29, 2023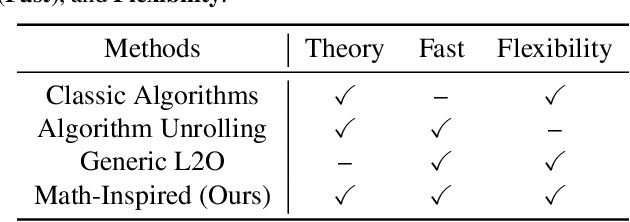
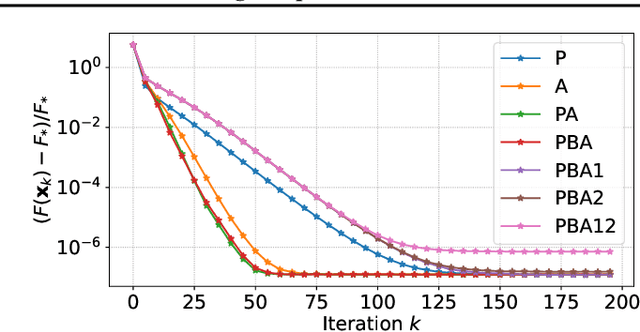
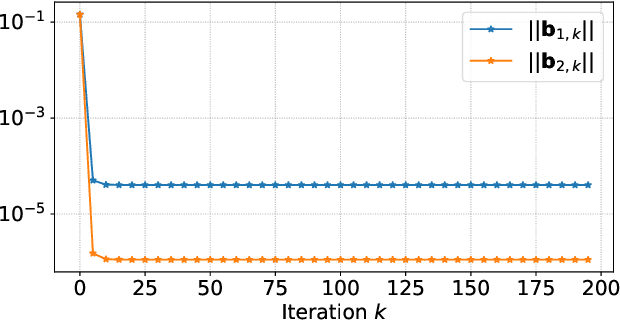
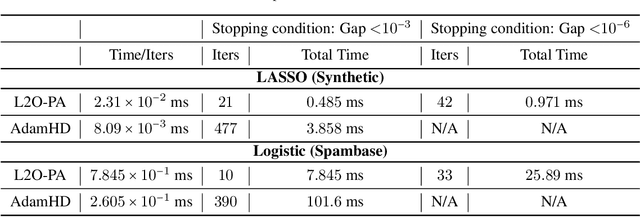
Learning to Optimize (L2O), a technique that utilizes machine learning to learn an optimization algorithm automatically from data, has gained arising attention in recent years. A generic L2O approach parameterizes the iterative update rule and learns the update direction as a black-box network. While the generic approach is widely applicable, the learned model can overfit and may not generalize well to out-of-distribution test sets. In this paper, we derive the basic mathematical conditions that successful update rules commonly satisfy. Consequently, we propose a novel L2O model with a mathematics-inspired structure that is broadly applicable and generalized well to out-of-distribution problems. Numerical simulations validate our theoretical findings and demonstrate the superior empirical performance of the proposed L2O model.
Constrained Reinforcement Learning for Dynamic Material Handling
May 23, 2023
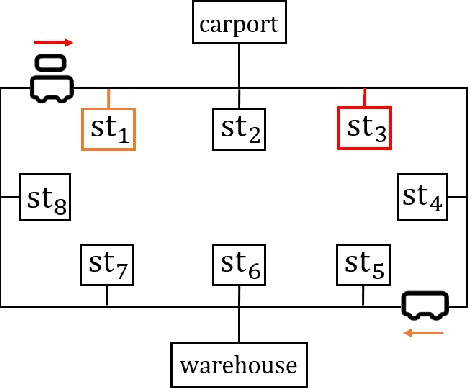
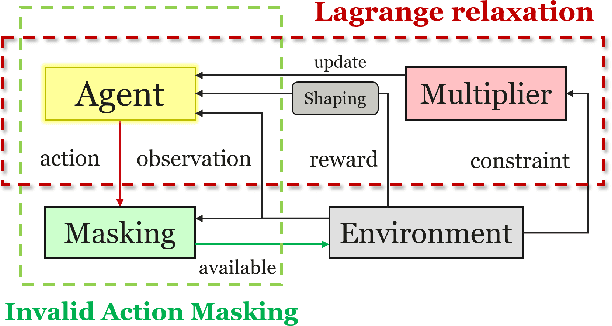
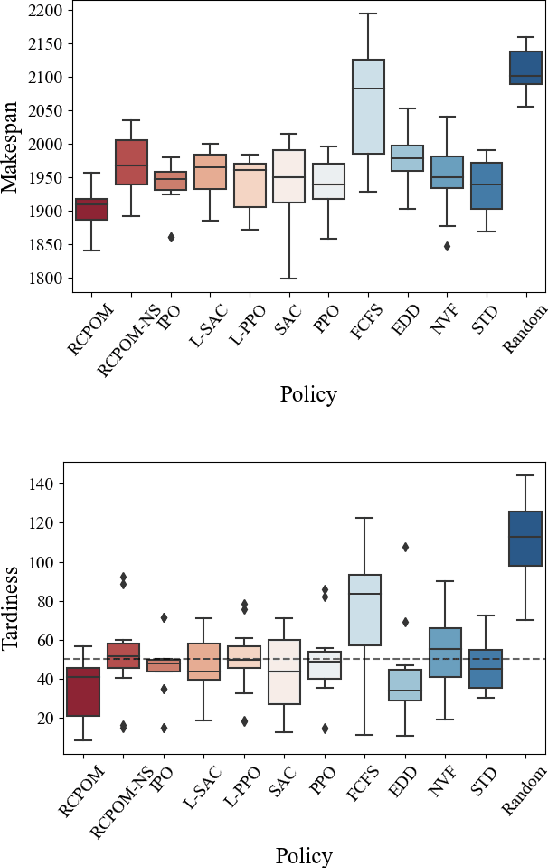
As one of the core parts of flexible manufacturing systems, material handling involves storage and transportation of materials between workstations with automated vehicles. The improvement in material handling can impulse the overall efficiency of the manufacturing system. However, the occurrence of dynamic events during the optimisation of task arrangements poses a challenge that requires adaptability and effectiveness. In this paper, we aim at the scheduling of automated guided vehicles for dynamic material handling. Motivated by some real-world scenarios, unknown new tasks and unexpected vehicle breakdowns are regarded as dynamic events in our problem. We formulate the problem as a constrained Markov decision process which takes into account tardiness and available vehicles as cumulative and instantaneous constraints, respectively. An adaptive constrained reinforcement learning algorithm that combines Lagrangian relaxation and invalid action masking, named RCPOM, is proposed to address the problem with two hybrid constraints. Moreover, a gym-like dynamic material handling simulator, named DMH-GYM, is developed and equipped with diverse problem instances, which can be used as benchmarks for dynamic material handling. Experimental results on the problem instances demonstrate the outstanding performance of our proposed approach compared with eight state-of-the-art constrained and non-constrained reinforcement learning algorithms, and widely used dispatching rules for material handling.