 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingwen He
Towards Real-world Video Face Restoration: A New Benchmark
Apr 30, 2024
Blind face restoration (BFR) on images has significantly progressed over the last several years, while real-world video face restoration (VFR), which is more challenging for more complex face motions such as moving gaze directions and facial orientations involved, remains unsolved. Typical BFR methods are evaluated on privately synthesized datasets or self-collected real-world low-quality face images, which are limited in their coverage of real-world video frames. In this work, we introduced new real-world datasets named FOS with a taxonomy of "Full, Occluded, and Side" faces from mainly video frames to study the applicability of current methods on videos. Compared with existing test datasets, FOS datasets cover more diverse degradations and involve face samples from more complex scenarios, which helps to revisit current face restoration approaches more comprehensively. Given the established datasets, we benchmarked both the state-of-the-art BFR methods and the video super resolution (VSR) methods to comprehensively study current approaches, identifying their potential and limitations in VFR tasks. In addition, we studied the effectiveness of the commonly used image quality assessment (IQA) metrics and face IQA (FIQA) metrics by leveraging a subjective user study. With extensive experimental results and detailed analysis provided, we gained insights from the successes and failures of both current BFR and VSR methods. These results also pose challenges to current face restoration approaches, which we hope stimulate future advances in VFR research.
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild
Jan 24, 2024We introduce SUPIR (Scaling-UP Image Restoration), a groundbreaking image restoration method that harnesses generative prior and the power of model scaling up. Leveraging multi-modal techniques and advanced generative prior, SUPIR marks a significant advance in intelligent and realistic image restoration. As a pivotal catalyst within SUPIR, model scaling dramatically enhances its capabilities and demonstrates new potential for image restoration. We collect a dataset comprising 20 million high-resolution, high-quality images for model training, each enriched with descriptive text annotations. SUPIR provides the capability to restore images guided by textual prompts, broadening its application scope and potential. Moreover, we introduce negative-quality prompts to further improve perceptual quality. We also develop a restoration-guided sampling method to suppress the fidelity issue encountered in generative-based restoration. Experiments demonstrate SUPIR's exceptional restoration effects and its novel capacity to manipulate restoration through textual prompts.
Towards Efficient SDRTV-to-HDRTV by Learning from Image Formation
Sep 08, 2023
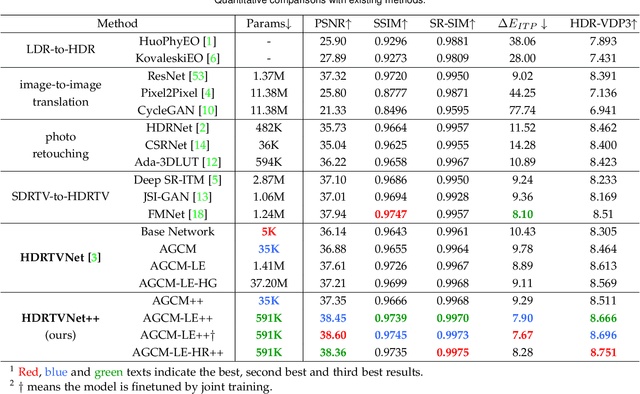
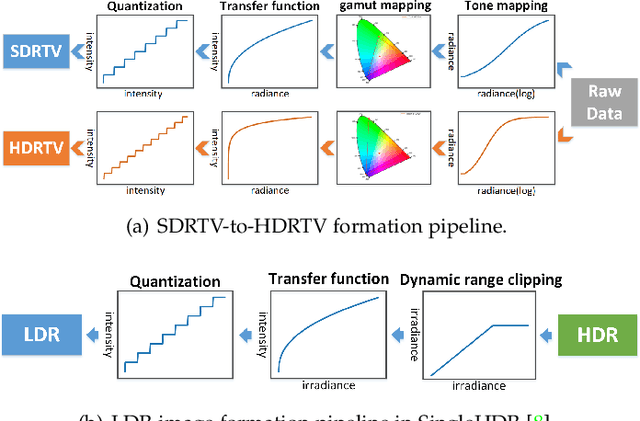

Modern displays are capable of rendering video content with high dynamic range (HDR) and wide color gamut (WCG). However, the majority of available resources are still in standard dynamic range (SDR). As a result, there is significant value in transforming existing SDR content into the HDRTV standard. In this paper, we define and analyze the SDRTV-to-HDRTV task by modeling the formation of SDRTV/HDRTV content. Our analysis and observations indicate that a naive end-to-end supervised training pipeline suffers from severe gamut transition errors. To address this issue, we propose a novel three-step solution pipeline called HDRTVNet++, which includes adaptive global color mapping, local enhancement, and highlight refinement. The adaptive global color mapping step uses global statistics as guidance to perform image-adaptive color mapping. A local enhancement network is then deployed to enhance local details. Finally, we combine the two sub-networks above as a generator and achieve highlight consistency through GAN-based joint training. Our method is primarily designed for ultra-high-definition TV content and is therefore effective and lightweight for processing 4K resolution images. We also construct a dataset using HDR videos in the HDR10 standard, named HDRTV1K that contains 1235 and 117 training images and 117 testing images, all in 4K resolution. Besides, we select five metrics to evaluate the results of SDRTV-to-HDRTV algorithms. Our final results demonstrate state-of-the-art performance both quantitatively and visually. The code, model and dataset are available at https://github.com/xiaom233/HDRTVNet-plus.
DiffBIR: Towards Blind Image Restoration with Generative Diffusion Prior
Aug 29, 2023

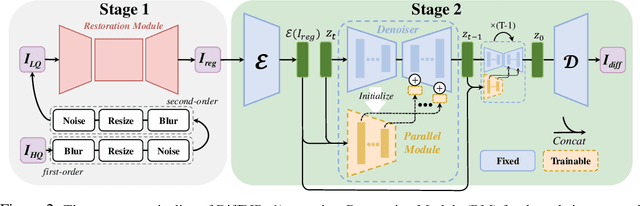
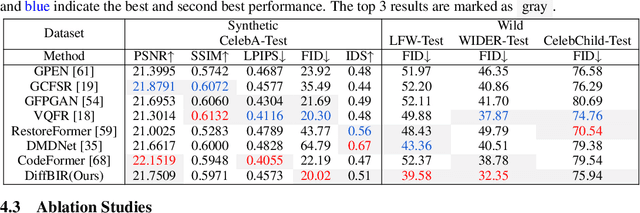
We present DiffBIR, which leverages pretrained text-to-image diffusion models for blind image restoration problem. Our framework adopts a two-stage pipeline. In the first stage, we pretrain a restoration module across diversified degradations to improve generalization capability in real-world scenarios. The second stage leverages the generative ability of latent diffusion models, to achieve realistic image restoration. Specifically, we introduce an injective modulation sub-network -- LAControlNet for finetuning, while the pre-trained Stable Diffusion is to maintain its generative ability. Finally, we introduce a controllable module that allows users to balance quality and fidelity by introducing the latent image guidance in the denoising process during inference. Extensive experiments have demonstrated its superiority over state-of-the-art approaches for both blind image super-resolution and blind face restoration tasks on synthetic and real-world datasets. The code is available at https://github.com/XPixelGroup/DiffBIR.
Residual Sparsity Connection Learning for Efficient Video Super-Resolution
Jun 15, 2022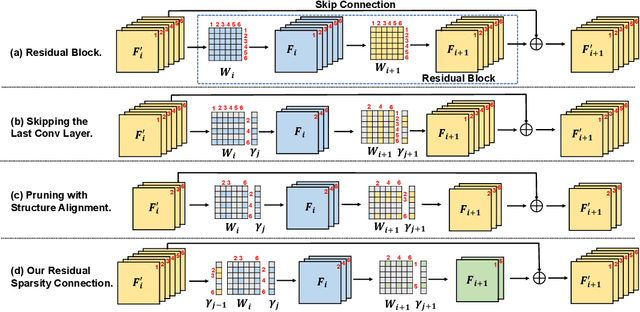
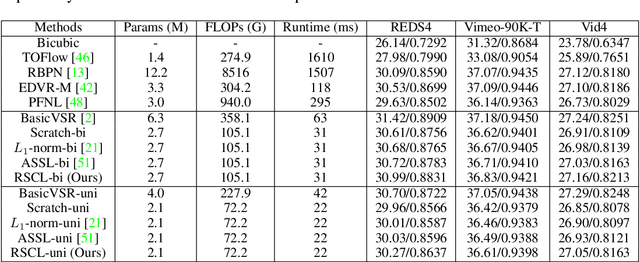
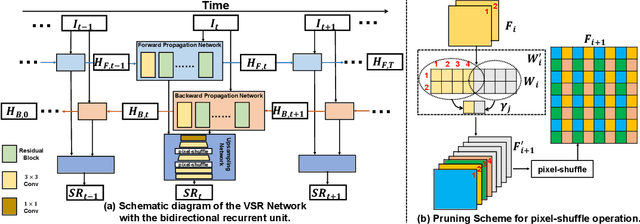
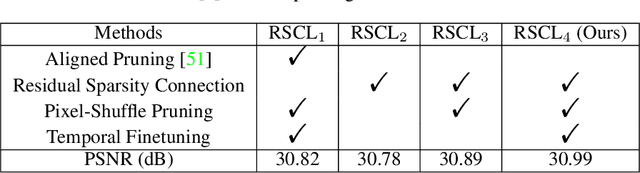
Lighter and faster models are crucial for the deployment of video super-resolution (VSR) on resource-limited devices, e.g., smartphones and wearable devices. In this paper, we develop Residual Sparsity Connection Learning (RSCL), a structured pruning scheme, to reduce the redundancy of convolution kernels and obtain a compact VSR network with a minor performance drop. However, residual blocks require the pruned filter indices of skip and residual connections to be the same, which is tricky for pruning. Thus, to mitigate the pruning restrictions of residual blocks, we design a Residual Sparsity Connection (RSC) scheme by preserving the feature channels and only operating on the important channels. Moreover, for the pixel-shuffle operation, we design a special pruning scheme by grouping several filters as pruning units to guarantee the accuracy of feature channel-space conversion after pruning. In addition, we introduce Temporal Finetuning (TF) to reduce the pruning error amplification of hidden states with temporal propagation. Extensive experiments show that the proposed RSCL significantly outperforms recent methods quantitatively and qualitatively. Codes and models will be released.
Residual Local Feature Network for Efficient Super-Resolution
May 16, 2022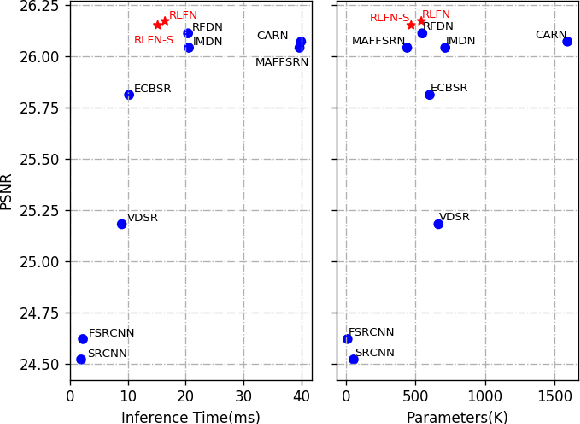
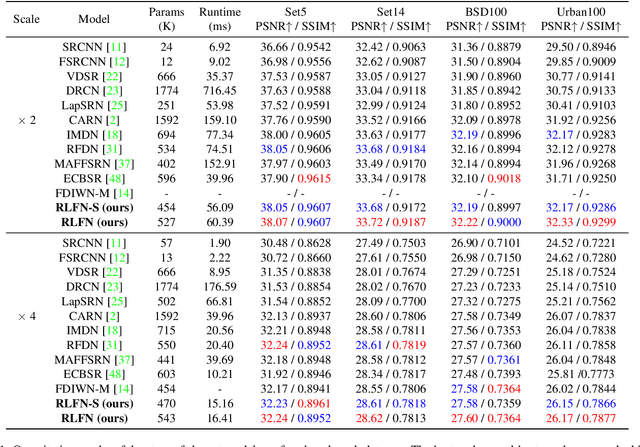
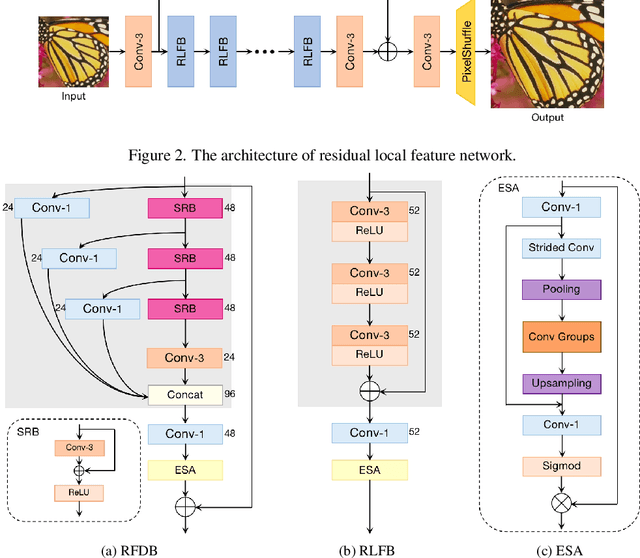
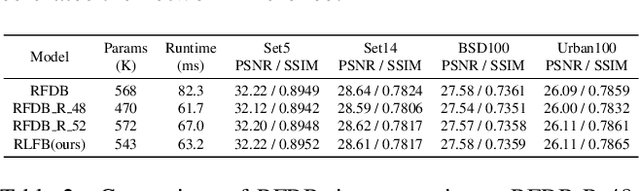
Deep learning based approaches has achieved great performance in single image super-resolution (SISR). However, recent advances in efficient super-resolution focus on reducing the number of parameters and FLOPs, and they aggregate more powerful features by improving feature utilization through complex layer connection strategies. These structures may not be necessary to achieve higher running speed, which makes them difficult to be deployed to resource-constrained devices. In this work, we propose a novel Residual Local Feature Network (RLFN). The main idea is using three convolutional layers for residual local feature learning to simplify feature aggregation, which achieves a good trade-off between model performance and inference time. Moreover, we revisit the popular contrastive loss and observe that the selection of intermediate features of its feature extractor has great influence on the performance. Besides, we propose a novel multi-stage warm-start training strategy. In each stage, the pre-trained weights from previous stages are utilized to improve the model performance. Combined with the improved contrastive loss and training strategy, the proposed RLFN outperforms all the state-of-the-art efficient image SR models in terms of runtime while maintaining both PSNR and SSIM for SR. In addition, we won the first place in the runtime track of the NTIRE 2022 efficient super-resolution challenge. Code will be available at https://github.com/fyan111/RLFN.
GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors
Mar 14, 2022
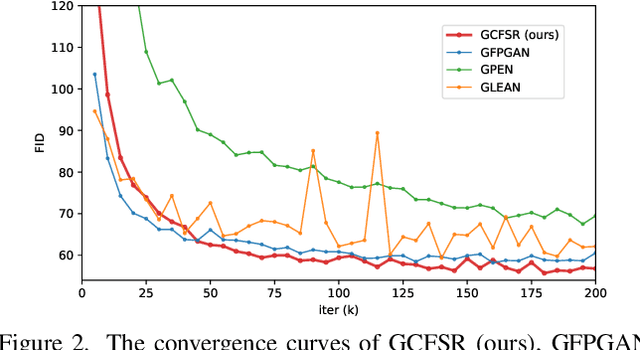


Face image super resolution (face hallucination) usually relies on facial priors to restore realistic details and preserve identity information. Recent advances can achieve impressive results with the help of GAN prior. They either design complicated modules to modify the fixed GAN prior or adopt complex training strategies to finetune the generator. In this work, we propose a generative and controllable face SR framework, called GCFSR, which can reconstruct images with faithful identity information without any additional priors. Generally, GCFSR has an encoder-generator architecture. Two modules called style modulation and feature modulation are designed for the multi-factor SR task. The style modulation aims to generate realistic face details and the feature modulation dynamically fuses the multi-level encoded features and the generated ones conditioned on the upscaling factor. The simple and elegant architecture can be trained from scratch in an end-to-end manner. For small upscaling factors (<=8), GCFSR can produce surprisingly good results with only adversarial loss. After adding L1 and perceptual losses, GCFSR can outperform state-of-the-art methods for large upscaling factors (16, 32, 64). During the test phase, we can modulate the generative strength via feature modulation by changing the conditional upscaling factor continuously to achieve various generative effects.
Toward Interactive Modulation for Photo-Realistic Image Restoration
May 07, 2021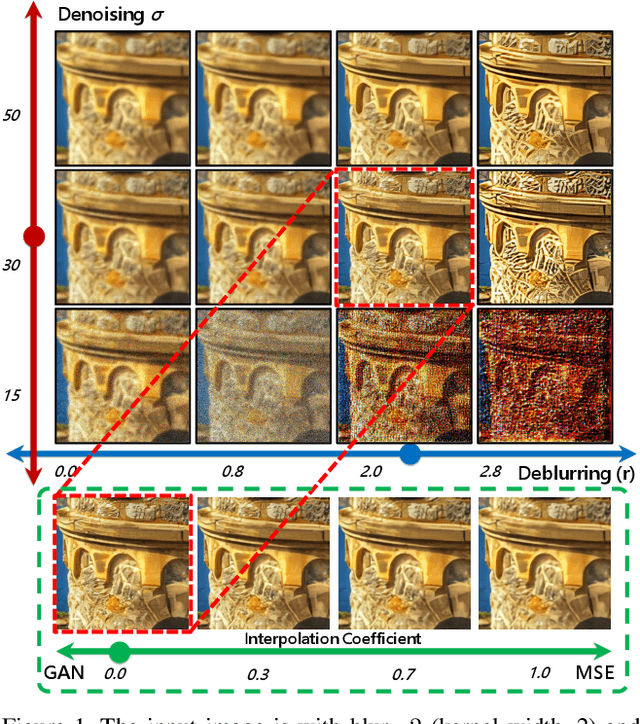
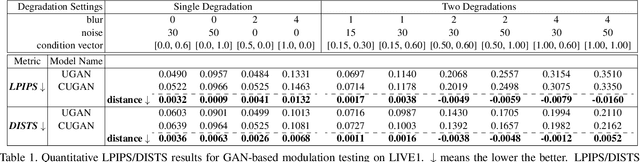

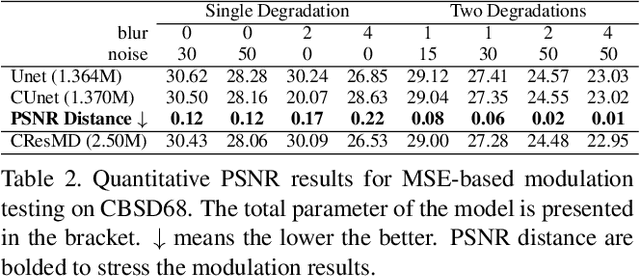
Modulating image restoration level aims to generate a restored image by altering a factor that represents the restoration strength. Previous works mainly focused on optimizing the mean squared reconstruction error, which brings high reconstruction accuracy but lacks finer texture details. This paper presents a Controllable Unet Generative Adversarial Network (CUGAN) to generate high-frequency textures in the modulation tasks. CUGAN consists of two modules -- base networks and condition networks. The base networks comprise a generator and a discriminator. In the generator, we realize the interactive control of restoration levels by tuning the weights of different features from different scales in the Unet architecture. Moreover, we adaptively modulate the intermediate features in the discriminator according to the severity of degradations. The condition networks accept the condition vector (encoded degradation information) as input, then generate modulation parameters for both the generator and the discriminator. During testing, users can control the output effects by tweaking the condition vector. We also provide a smooth transition between GAN and MSE effects by a simple transition method. Extensive experiments demonstrate that the proposed CUGAN achieves excellent performance on image restoration modulation tasks.
Very Lightweight Photo Retouching Network with Conditional Sequential Modulation
Apr 13, 2021
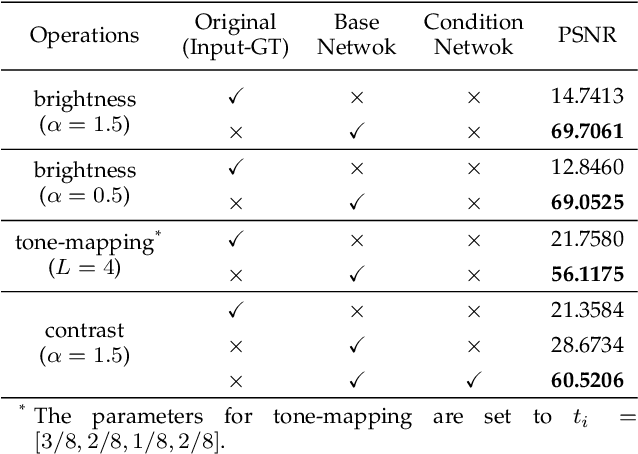
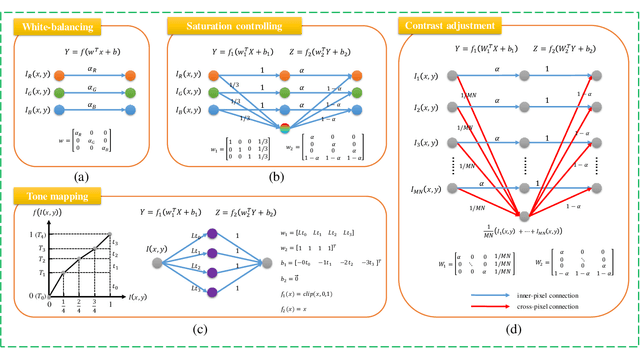
Photo retouching aims at improving the aesthetic visual quality of images that suffer from photographic defects such as poor contrast, over/under exposure, and inharmonious saturation. In practice, photo retouching can be accomplished by a series of image processing operations. As most commonly-used retouching operations are pixel-independent, i.e., the manipulation on one pixel is uncorrelated with its neighboring pixels, we can take advantage of this property and design a specialized algorithm for efficient global photo retouching. We analyze these global operations and find that they can be mathematically formulated by a Multi-Layer Perceptron (MLP). Based on this observation, we propose an extremely lightweight framework -- Conditional Sequential Retouching Network (CSRNet). Benefiting from the utilization of $1\times1$ convolution, CSRNet only contains less than 37K trainable parameters, which are orders of magnitude smaller than existing learning-based methods. Experiments show that our method achieves state-of-the-art performance on the benchmark MIT-Adobe FiveK dataset quantitively and qualitatively. In addition to achieve global photo retouching, the proposed framework can be easily extended to learn local enhancement effects. The extended model, namly CSRNet-L, also achieves competitive results in various local enhancement tasks. Codes will be available.
Efficient Image Super-Resolution Using Pixel Attention
Oct 02, 2020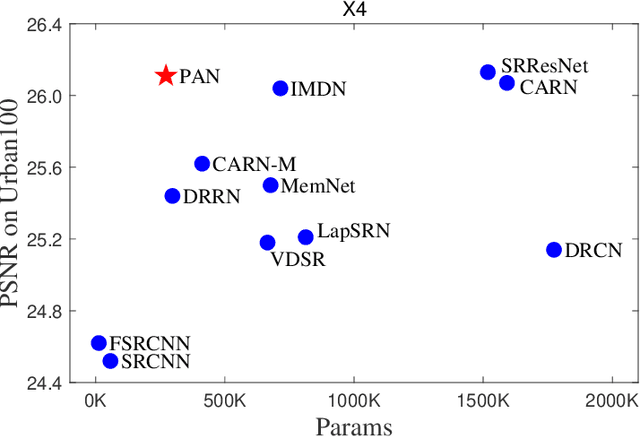
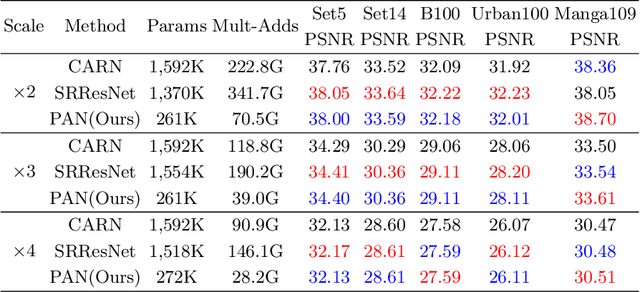

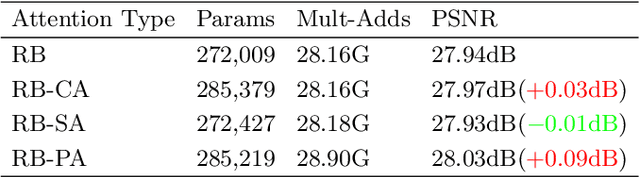
This work aims at designing a lightweight convolutional neural network for image super resolution (SR). With simplicity bare in mind, we construct a pretty concise and effective network with a newly proposed pixel attention scheme. Pixel attention (PA) is similar as channel attention and spatial attention in formulation. The difference is that PA produces 3D attention maps instead of a 1D attention vector or a 2D map. This attention scheme introduces fewer additional parameters but generates better SR results. On the basis of PA, we propose two building blocks for the main branch and the reconstruction branch, respectively. The first one - SC-PA block has the same structure as the Self-Calibrated convolution but with our PA layer. This block is much more efficient than conventional residual/dense blocks, for its twobranch architecture and attention scheme. While the second one - UPA block combines the nearest-neighbor upsampling, convolution and PA layers. It improves the final reconstruction quality with little parameter cost. Our final model- PAN could achieve similar performance as the lightweight networks - SRResNet and CARN, but with only 272K parameters (17.92% of SRResNet and 17.09% of CARN). The effectiveness of each proposed component is also validated by ablation study. The code is available at https://github.com/zhaohengyuan1/PAN.