 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingyao Wang
Explicitly Modeling Generality into Self-Supervised Learning
May 02, 2024
The goal of generality in machine learning is to achieve excellent performance on various unseen tasks and domains. Recently, self-supervised learning (SSL) has been regarded as an effective method to achieve this goal. It can learn high-quality representations from unlabeled data and achieve promising empirical performance on multiple downstream tasks. Existing SSL methods mainly constrain generality from two aspects: (i) large-scale training data, and (ii) learning task-level shared knowledge. However, these methods lack explicit modeling of the SSL generality in the learning objective, and the theoretical understanding of SSL's generality remains limited. This may cause SSL models to overfit in data-scarce situations and generalize poorly in the real world, making it difficult to achieve true generality. To address these issues, we provide a theoretical definition of generality in SSL and define a $\sigma$-measurement to help quantify it. Based on this insight, we explicitly model generality into self-supervised learning and further propose a novel SSL framework, called GeSSL. It introduces a self-motivated target based on $\sigma$-measurement, which enables the model to find the optimal update direction towards generality. Extensive theoretical and empirical evaluations demonstrate the superior performance of the proposed GeSSL.
Meta-Auxiliary Learning for Micro-Expression Recognition
Apr 18, 2024Micro-expressions (MEs) are involuntary movements revealing people's hidden feelings, which has attracted numerous interests for its objectivity in emotion detection. However, despite its wide applications in various scenarios, micro-expression recognition (MER) remains a challenging problem in real life due to three reasons, including (i) data-level: lack of data and imbalanced classes, (ii) feature-level: subtle, rapid changing, and complex features of MEs, and (iii) decision-making-level: impact of individual differences. To address these issues, we propose a dual-branch meta-auxiliary learning method, called LightmanNet, for fast and robust micro-expression recognition. Specifically, LightmanNet learns general MER knowledge from limited data through a dual-branch bi-level optimization process: (i) In the first level, it obtains task-specific MER knowledge by learning in two branches, where the first branch is for learning MER features via primary MER tasks, while the other branch is for guiding the model obtain discriminative features via auxiliary tasks, i.e., image alignment between micro-expressions and macro-expressions since their resemblance in both spatial and temporal behavioral patterns. The two branches of learning jointly constrain the model of learning meaningful task-specific MER knowledge while avoiding learning noise or superficial connections between MEs and emotions that may damage its generalization ability. (ii) In the second level, LightmanNet further refines the learned task-specific knowledge, improving model generalization and efficiency. Extensive experiments on various benchmark datasets demonstrate the superior robustness and efficiency of LightmanNet.
Intriguing Properties of Positional Encoding in Time Series Forecasting
Apr 16, 2024Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: \href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
Hacking Task Confounder in Meta-Learning
Dec 10, 2023Meta-learning enables rapid generalization to new tasks by learning meta-knowledge from a variety of tasks. It is intuitively assumed that the more tasks a model learns in one training batch, the richer knowledge it acquires, leading to better generalization performance. However, contrary to this intuition, our experiments reveal an unexpected result: adding more tasks within a single batch actually degrades the generalization performance. To explain this unexpected phenomenon, we conduct a Structural Causal Model (SCM) for causal analysis. Our investigation uncovers the presence of spurious correlations between task-specific causal factors and labels in meta-learning. Furthermore, the confounding factors differ across different batches. We refer to these confounding factors as ``Task Confounders". Based on this insight, we propose a plug-and-play Meta-learning Causal Representation Learner (MetaCRL) to eliminate task confounders. It encodes decoupled causal factors from multiple tasks and utilizes an invariant-based bi-level optimization mechanism to ensure their causality for meta-learning. Extensive experiments on various benchmark datasets demonstrate that our work achieves state-of-the-art (SOTA) performance.
Unleash Model Potential: Bootstrapped Meta Self-supervised Learning
Aug 28, 2023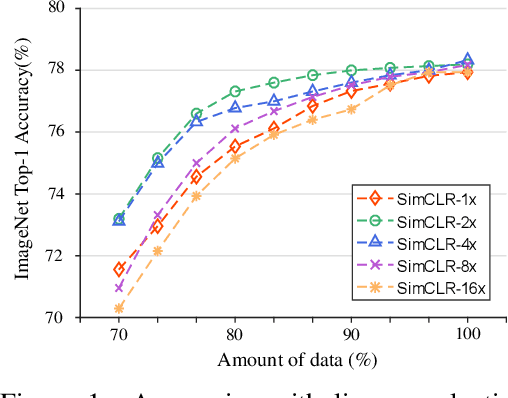
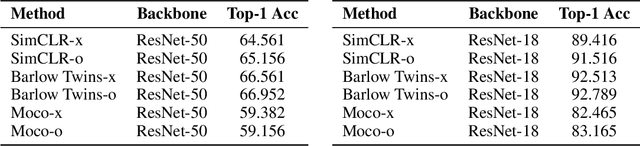
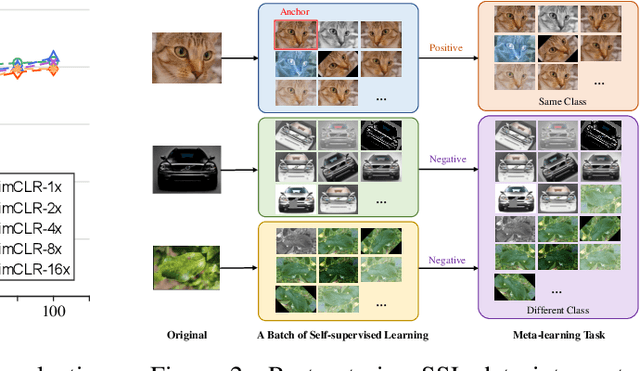
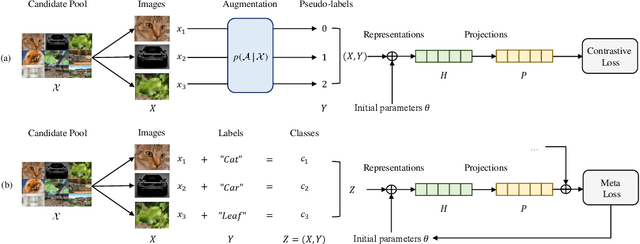
The long-term goal of machine learning is to learn general visual representations from a small amount of data without supervision, mimicking three advantages of human cognition: i) no need for labels, ii) robustness to data scarcity, and iii) learning from experience. Self-supervised learning and meta-learning are two promising techniques to achieve this goal, but they both only partially capture the advantages and fail to address all the problems. Self-supervised learning struggles to overcome the drawbacks of data scarcity, while ignoring prior knowledge that can facilitate learning and generalization. Meta-learning relies on supervised information and suffers from a bottleneck of insufficient learning. To address these issues, we propose a novel Bootstrapped Meta Self-Supervised Learning (BMSSL) framework that aims to simulate the human learning process. We first analyze the close relationship between meta-learning and self-supervised learning. Based on this insight, we reconstruct tasks to leverage the strengths of both paradigms, achieving advantages i and ii. Moreover, we employ a bi-level optimization framework that alternates between solving specific tasks with a learned ability (first level) and improving this ability (second level), attaining advantage iii. To fully harness its power, we introduce a bootstrapped target based on meta-gradient to make the model its own teacher. We validate the effectiveness of our approach with comprehensive theoretical and empirical study.
Towards the Sparseness of Projection Head in Self-Supervised Learning
Jul 19, 2023



In recent years, self-supervised learning (SSL) has emerged as a promising approach for extracting valuable representations from unlabeled data. One successful SSL method is contrastive learning, which aims to bring positive examples closer while pushing negative examples apart. Many current contrastive learning approaches utilize a parameterized projection head. Through a combination of empirical analysis and theoretical investigation, we provide insights into the internal mechanisms of the projection head and its relationship with the phenomenon of dimensional collapse. Our findings demonstrate that the projection head enhances the quality of representations by performing contrastive loss in a projected subspace. Therefore, we propose an assumption that only a subset of features is necessary when minimizing the contrastive loss of a mini-batch of data. Theoretical analysis further suggests that a sparse projection head can enhance generalization, leading us to introduce SparseHead - a regularization term that effectively constrains the sparsity of the projection head, and can be seamlessly integrated with any self-supervised learning (SSL) approaches. Our experimental results validate the effectiveness of SparseHead, demonstrating its ability to improve the performance of existing contrastive methods.
CSSL-RHA: Contrastive Self-Supervised Learning for Robust Handwriting Authentication
Jul 18, 2023Handwriting authentication is a valuable tool used in various fields, such as fraud prevention and cultural heritage protection. However, it remains a challenging task due to the complex features, severe damage, and lack of supervision. In this paper, we propose a novel Contrastive Self-Supervised Learning framework for Robust Handwriting Authentication (CSSL-RHA) to address these issues. It can dynamically learn complex yet important features and accurately predict writer identities. Specifically, to remove the negative effects of imperfections and redundancy, we design an information-theoretic filter for pre-processing and propose a novel adaptive matching scheme to represent images as patches of local regions dominated by more important features. Through online optimization at inference time, the most informative patch embeddings are identified as the "most important" elements. Furthermore, we employ contrastive self-supervised training with a momentum-based paradigm to learn more general statistical structures of handwritten data without supervision. We conduct extensive experiments on five benchmark datasets and our manually annotated dataset EN-HA, which demonstrate the superiority of our CSSL-RHA compared to baselines. Additionally, we show that our proposed model can still effectively achieve authentication even under abnormal circumstances, such as data falsification and corruption.
Learning to Sample Tasks for Meta Learning
Jul 18, 2023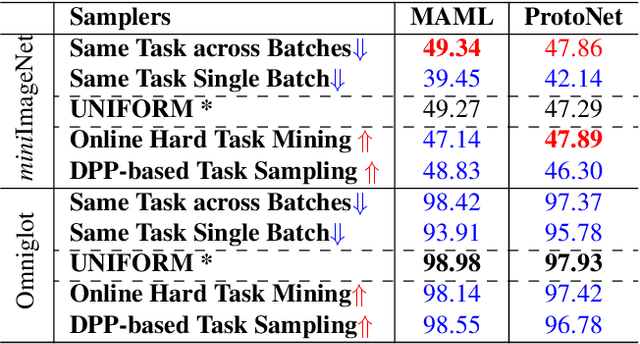
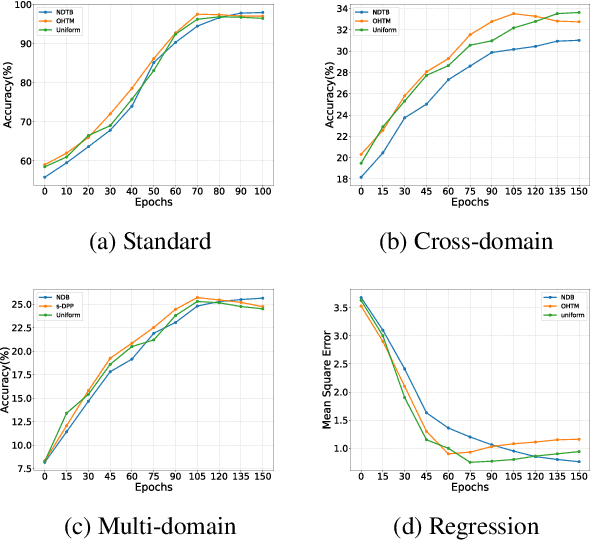
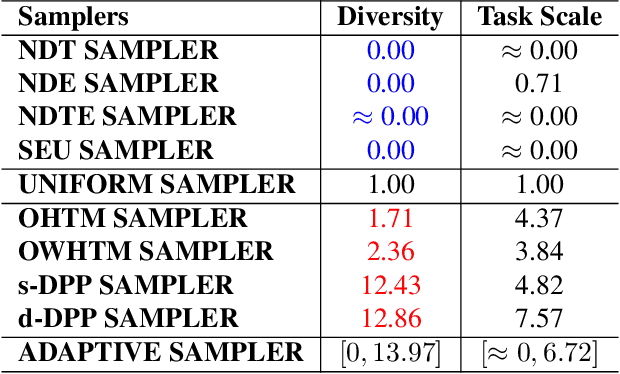
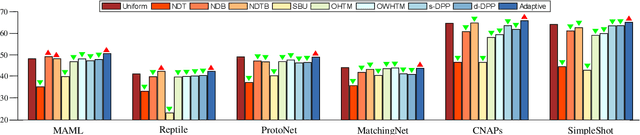
Through experiments on various meta-learning methods, task samplers, and few-shot learning tasks, this paper arrives at three conclusions. Firstly, there are no universal task sampling strategies to guarantee the performance of meta-learning models. Secondly, task diversity can cause the models to either underfit or overfit during training. Lastly, the generalization performance of the models are influenced by task divergence, task entropy, and task difficulty. In response to these findings, we propose a novel task sampler called Adaptive Sampler (ASr). ASr is a plug-and-play task sampler that takes task divergence, task entropy, and task difficulty to sample tasks. To optimize ASr, we rethink and propose a simple and general meta-learning algorithm. Finally, a large number of empirical experiments demonstrate the effectiveness of the proposed ASr.
Text-based Person Search without Parallel Image-Text Data
May 22, 2023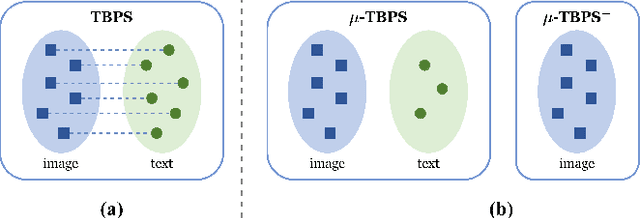
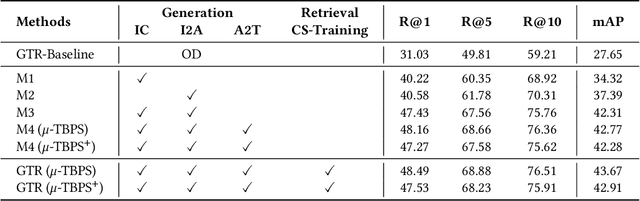
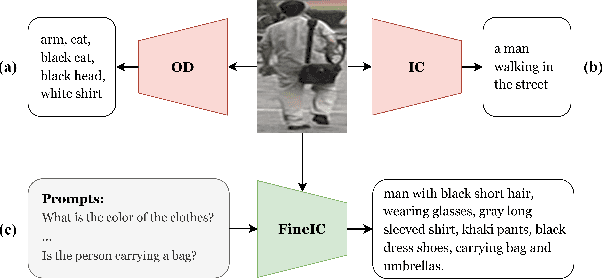
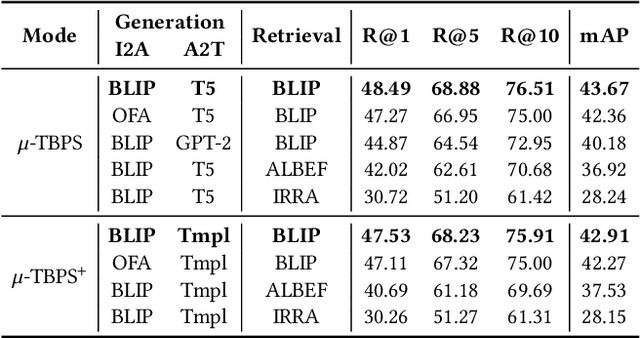
Text-based person search (TBPS) aims to retrieve the images of the target person from a large image gallery based on a given natural language description. Existing methods are dominated by training models with parallel image-text pairs, which are very costly to collect. In this paper, we make the first attempt to explore TBPS without parallel image-text data ($\mu$-TBPS), in which only non-parallel images and texts, or even image-only data, can be adopted. Towards this end, we propose a two-stage framework, generation-then-retrieval (GTR), to first generate the corresponding pseudo text for each image and then perform the retrieval in a supervised manner. In the generation stage, we propose a fine-grained image captioning strategy to obtain an enriched description of the person image, which firstly utilizes a set of instruction prompts to activate the off-the-shelf pretrained vision-language model to capture and generate fine-grained person attributes, and then converts the extracted attributes into a textual description via the finetuned large language model or the hand-crafted template. In the retrieval stage, considering the noise interference of the generated texts for training model, we develop a confidence score-based training scheme by enabling more reliable texts to contribute more during the training. Experimental results on multiple TBPS benchmarks (i.e., CUHK-PEDES, ICFG-PEDES and RSTPReid) show that the proposed GTR can achieve a promising performance without relying on parallel image-text data.
Awesome-META+: Meta-Learning Research and Learning Platform
Apr 24, 2023
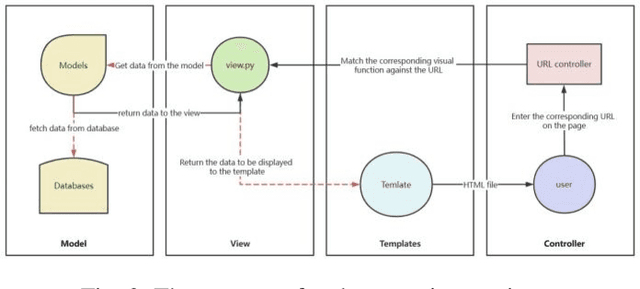
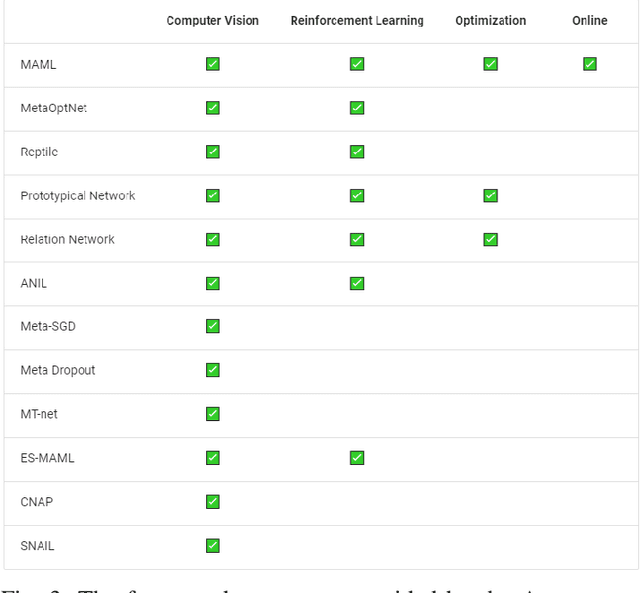
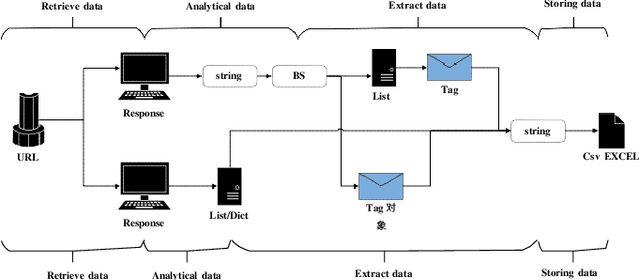
Artificial intelligence technology has already had a profound impact in various fields such as economy, industry, and education, but still limited. Meta-learning, also known as "learning to learn", provides an opportunity for general artificial intelligence, which can break through the current AI bottleneck. However, meta learning started late and there are fewer projects compare with CV, NLP etc. Each deployment requires a lot of experience to configure the environment, debug code or even rewrite, and the frameworks are isolated. Moreover, there are currently few platforms that focus exclusively on meta-learning, or provide learning materials for novices, for which the threshold is relatively high. Based on this, Awesome-META+, a meta-learning framework integration and learning platform is proposed to solve the above problems and provide a complete and reliable meta-learning framework application and learning platform. The project aims to promote the development of meta-learning and the expansion of the community, including but not limited to the following functions: 1) Complete and reliable meta-learning framework, which can adapt to multi-field tasks such as target detection, image classification, and reinforcement learning. 2) Convenient and simple model deployment scheme which provide convenient meta-learning transfer methods and usage methods to lower the threshold of meta-learning and improve efficiency. 3) Comprehensive researches for learning. 4) Objective and credible performance analysis and thinking.