 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKenneth Church
Since the Scientific Literature Is Multilingual, Our Models Should Be Too
Mar 27, 2024

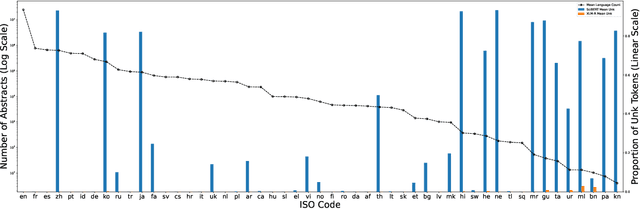

English has long been assumed the $\textit{lingua franca}$ of scientific research, and this notion is reflected in the natural language processing (NLP) research involving scientific document representation. In this position piece, we quantitatively show that the literature is largely multilingual and argue that current models and benchmarks should reflect this linguistic diversity. We provide evidence that text-based models fail to create meaningful representations for non-English papers and highlight the negative user-facing impacts of using English-only models non-discriminately across a multilingual domain. We end with suggestions for the NLP community on how to improve performance on non-English documents.
Data-Driven Adaptive Simultaneous Machine Translation
Apr 27, 2022
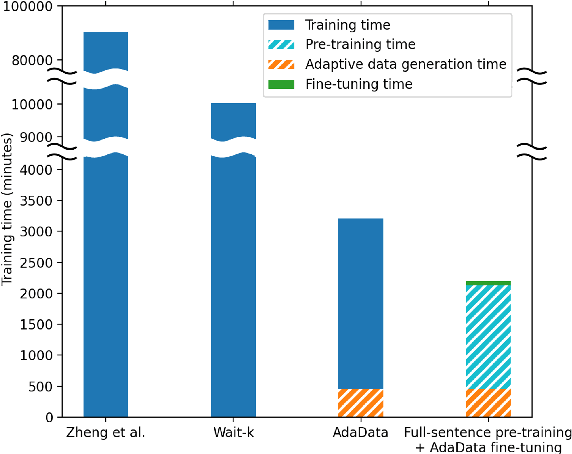
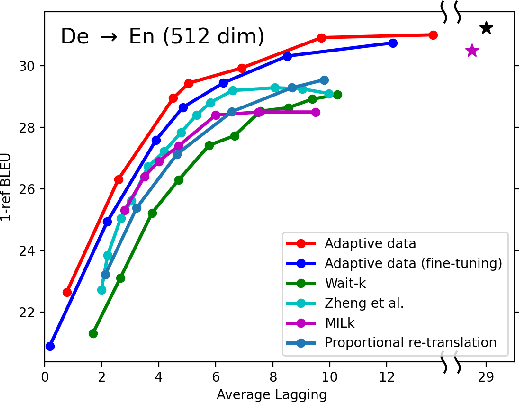
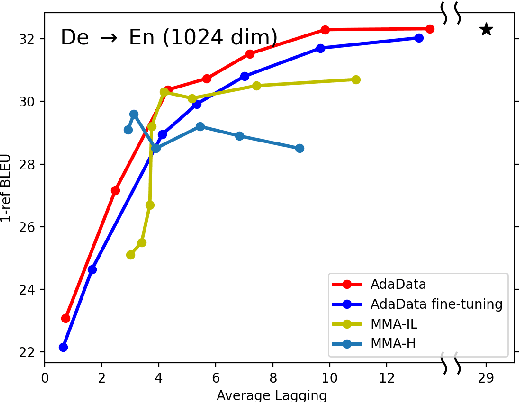
In simultaneous translation (SimulMT), the most widely used strategy is the wait-k policy thanks to its simplicity and effectiveness in balancing translation quality and latency. However, wait-k suffers from two major limitations: (a) it is a fixed policy that can not adaptively adjust latency given context, and (b) its training is much slower than full-sentence translation. To alleviate these issues, we propose a novel and efficient training scheme for adaptive SimulMT by augmenting the training corpus with adaptive prefix-to-prefix pairs, while the training complexity remains the same as that of training full-sentence translation models. Experiments on two language pairs show that our method outperforms all strong baselines in terms of translation quality and latency.
Efficiently Disentangle Causal Representations
Jan 06, 2022
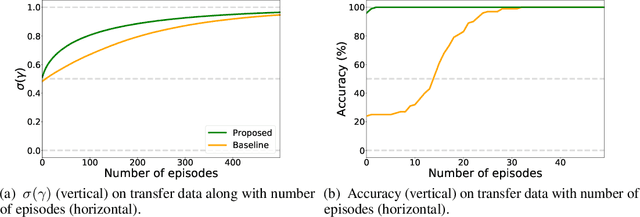
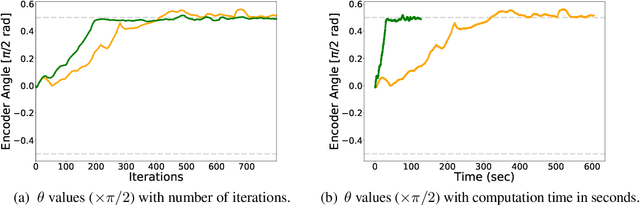
This paper proposes an efficient approach to learning disentangled representations with causal mechanisms based on the difference of conditional probabilities in original and new distributions. We approximate the difference with models' generalization abilities so that it fits in the standard machine learning framework and can be efficiently computed. In contrast to the state-of-the-art approach, which relies on the learner's adaptation speed to new distribution, the proposed approach only requires evaluating the model's generalization ability. We provide a theoretical explanation for the advantage of the proposed method, and our experiments show that the proposed technique is 1.9--11.0$\times$ more sample efficient and 9.4--32.4 times quicker than the previous method on various tasks. The source code is available at \url{https://github.com/yuanpeng16/EDCR}.
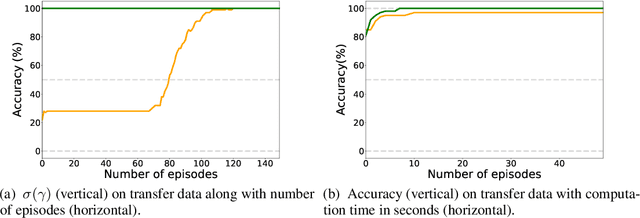
Exploiting a Zoo of Checkpoints for Unseen Tasks
Nov 05, 2021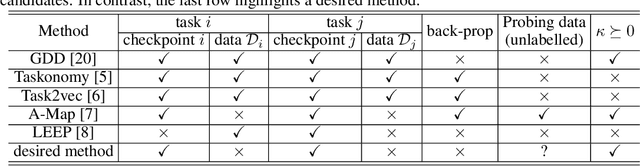
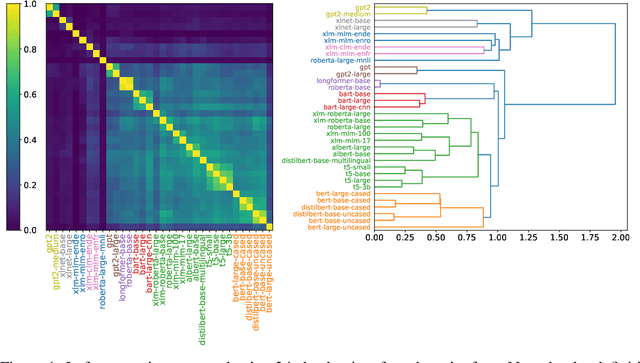
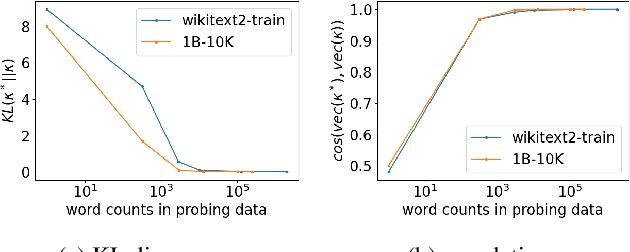

There are so many models in the literature that it is difficult for practitioners to decide which combinations are likely to be effective for a new task. This paper attempts to address this question by capturing relationships among checkpoints published on the web. We model the space of tasks as a Gaussian process. The covariance can be estimated from checkpoints and unlabeled probing data. With the Gaussian process, we can identify representative checkpoints by a maximum mutual information criterion. This objective is submodular. A greedy method identifies representatives that are likely to "cover" the task space. These representatives generalize to new tasks with superior performance. Empirical evidence is provided for applications from both computational linguistics as well as computer vision.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021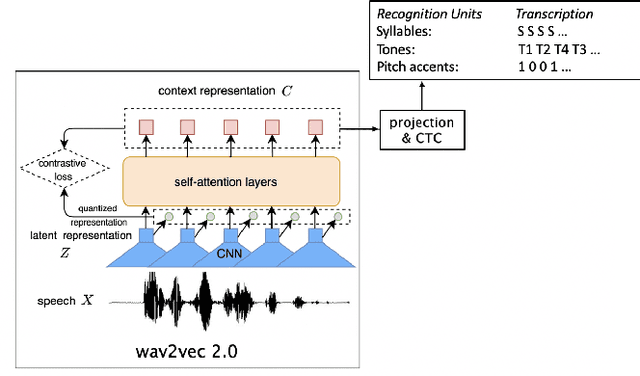
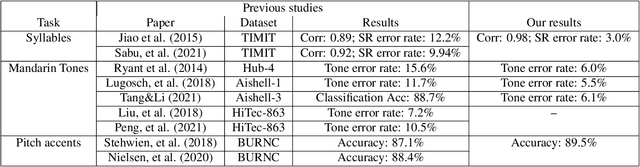

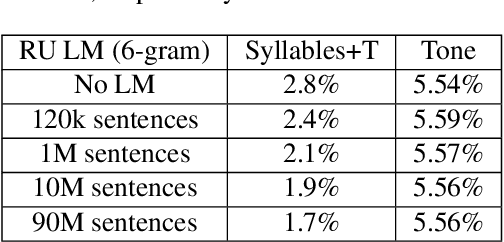
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
The Role of Phonetic Units in Speech Emotion Recognition
Aug 02, 2021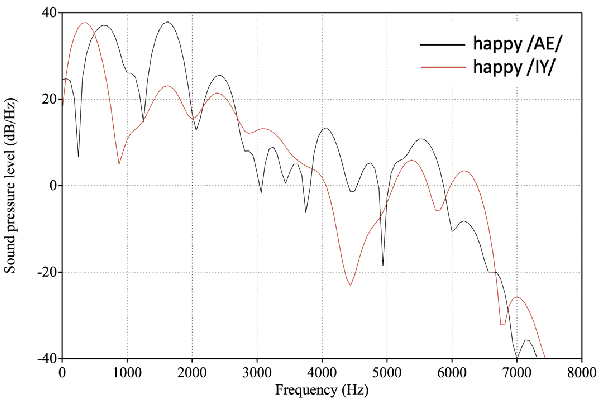
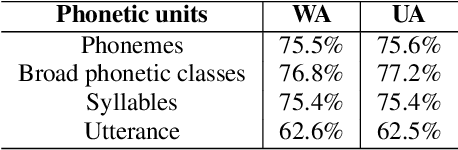
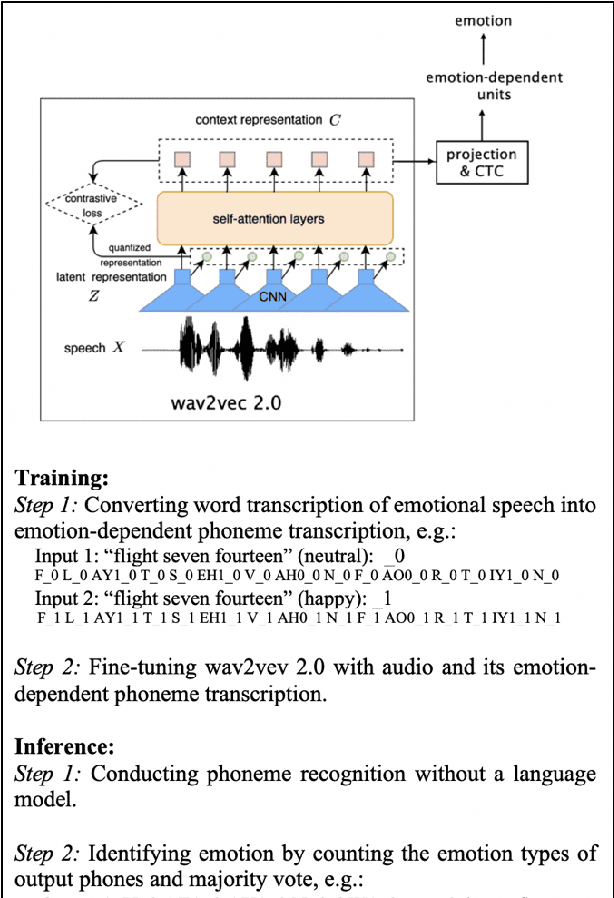
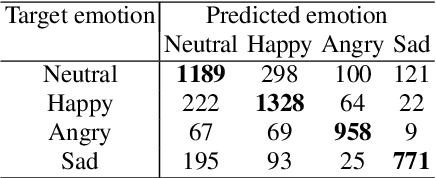
We propose a method for emotion recognition through emotiondependent speech recognition using Wav2vec 2.0. Our method achieved a significant improvement over most previously reported results on IEMOCAP, a benchmark emotion dataset. Different types of phonetic units are employed and compared in terms of accuracy and robustness of emotion recognition within and across datasets and languages. Models of phonemes, broad phonetic classes, and syllables all significantly outperform the utterance model, demonstrating that phonetic units are helpful and should be incorporated in speech emotion recognition. The best performance is from using broad phonetic classes. Further research is needed to investigate the optimal set of broad phonetic classes for the task of emotion recognition. Finally, we found that Wav2vec 2.0 can be fine-tuned to recognize coarser-grained or larger phonetic units than phonemes, such as broad phonetic classes and syllables.
Decoupling recognition and transcription in Mandarin ASR
Aug 02, 2021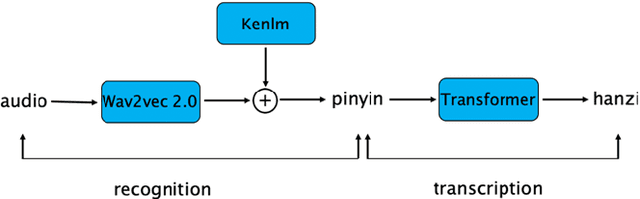
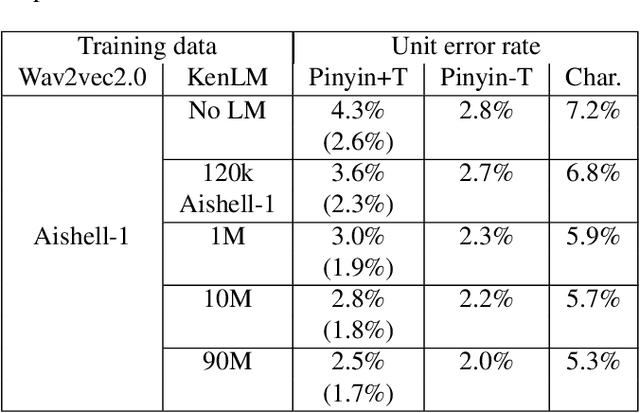
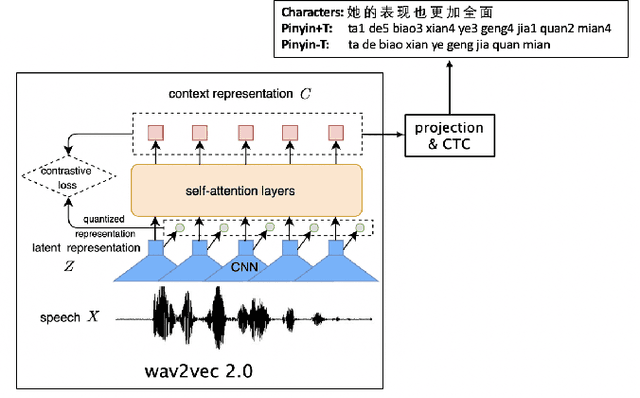
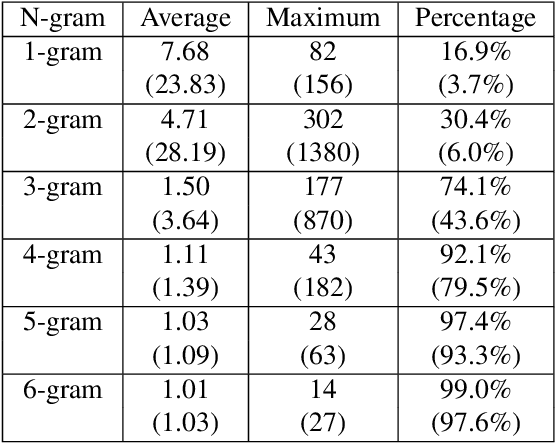
Much of the recent literature on automatic speech recognition (ASR) is taking an end-to-end approach. Unlike English where the writing system is closely related to sound, Chinese characters (Hanzi) represent meaning, not sound. We propose factoring audio -> Hanzi into two sub-tasks: (1) audio -> Pinyin and (2) Pinyin -> Hanzi, where Pinyin is a system of phonetic transcription of standard Chinese. Factoring the audio -> Hanzi task in this way achieves 3.9% CER (character error rate) on the Aishell-1 corpus, the best result reported on this dataset so far.
Better than BERT but Worse than Baseline
May 12, 2021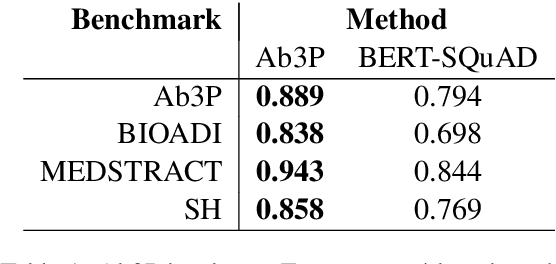
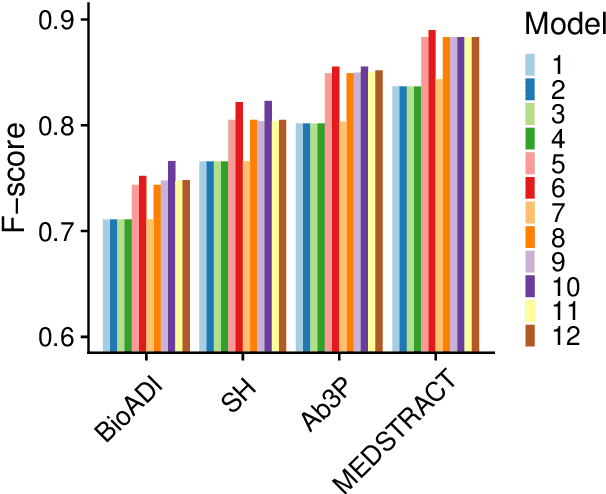
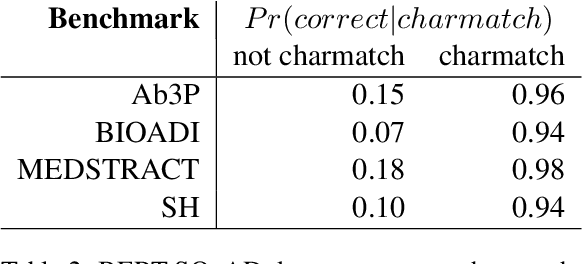
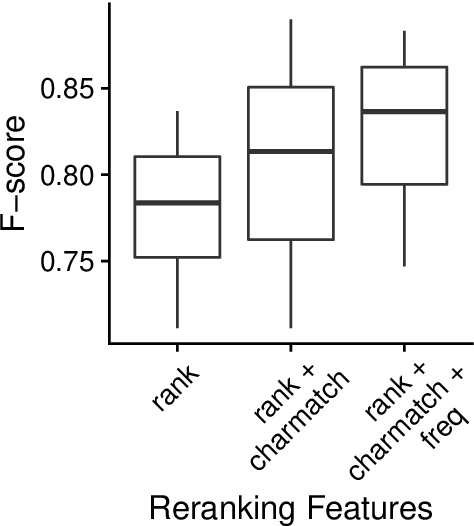
This paper compares BERT-SQuAD and Ab3P on the Abbreviation Definition Identification (ADI) task. ADI inputs a text and outputs short forms (abbreviations/acronyms) and long forms (expansions). BERT with reranking improves over BERT without reranking but fails to reach the Ab3P rule-based baseline. What is BERT missing? Reranking introduces two new features: charmatch and freq. The first feature identifies opportunities to take advantage of character constraints in acronyms and the second feature identifies opportunities to take advantage of frequency constraints across documents.
Fluent and Low-latency Simultaneous Speech-to-Speech Translation with Self-adaptive Training
Oct 21, 2020

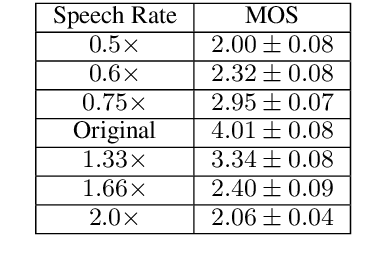
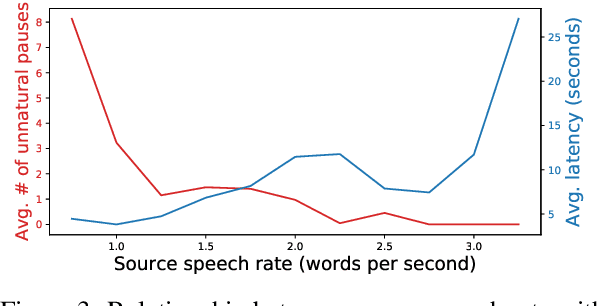
Simultaneous speech-to-speech translation is widely useful but extremely challenging, since it needs to generate target-language speech concurrently with the source-language speech, with only a few seconds delay. In addition, it needs to continuously translate a stream of sentences, but all recent solutions merely focus on the single-sentence scenario. As a result, current approaches accumulate latencies progressively when the speaker talks faster, and introduce unnatural pauses when the speaker talks slower. To overcome these issues, we propose Self-Adaptive Translation (SAT) which flexibly adjusts the length of translations to accommodate different source speech rates. At similar levels of translation quality (as measured by BLEU), our method generates more fluent target speech (as measured by the naturalness metric MOS) with substantially lower latency than the baseline, in both Zh <-> En directions.
* 10 pages, accepted by Findings of EMNLP 2020
Long-tail Visual Relationship Recognition with a Visiolinguistic Hubless Loss
Apr 20, 2020
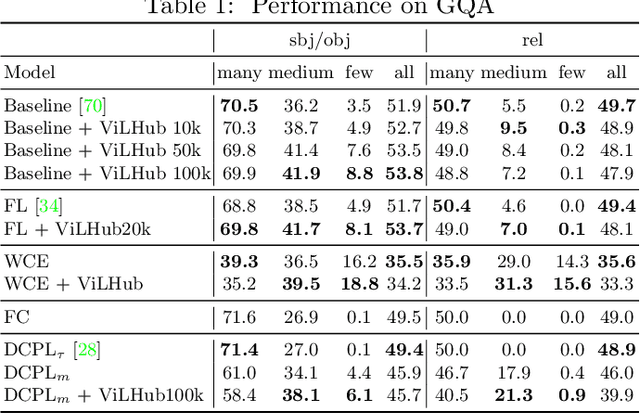
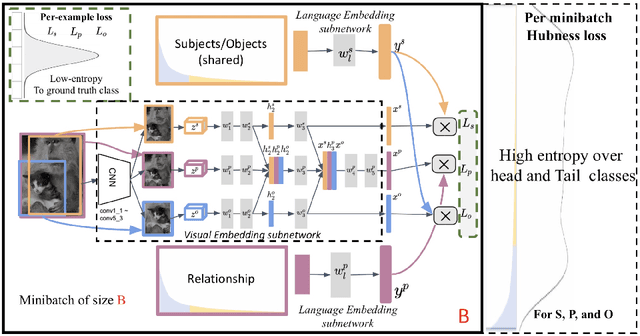
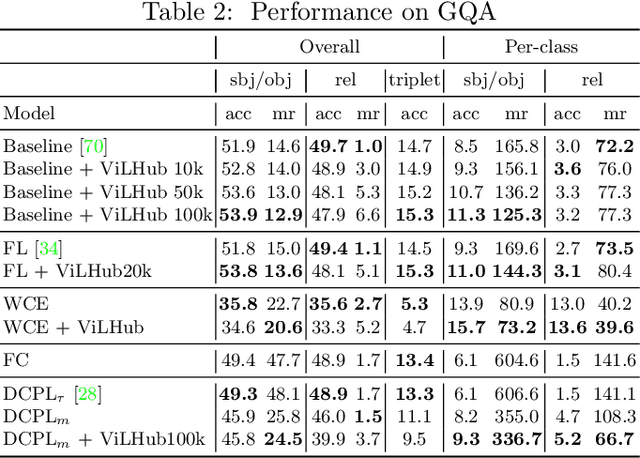
Scaling up the vocabulary and complexity of current visual understanding systems is necessary in order to bridge the gap between human and machine visual intelligence. However, a crucial impediment to this end lies in the difficulty of generalizing to data distributions that come from real-world scenarios. Typically such distributions follow Zipf's law which states that only a small portion of the collected object classes will have abundant examples (head); while most classes will contain just a few (tail). In this paper, we propose to study a novel task concerning the generalization of visual relationships that are on the distribution's tail, i.e. we investigate how to help AI systems to better recognize rare relationships like <S:dog, P:riding, O:horse>, where the subject S, predicate P, and/or the object O come from the tail of the corresponding distributions. To achieve this goal, we first introduce two large-scale visual-relationship detection benchmarks built upon the widely used Visual Genome and GQA datasets. We also propose an intuitive evaluation protocol that gives credit to classifiers who prefer concepts that are semantically close to the ground truth class according to wordNet- or word2vec-induced metrics. Finally, we introduce a visiolinguistic version of a Hubless loss which we show experimentally that it consistently encourages classifiers to be more predictive of the tail classes while still being accurate on head classes. Our code and models are available on http://bit.ly/LTVRR.