 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Cheng
Towards Robust Recommendation: A Review and an Adversarial Robustness Evaluation Library
Apr 27, 2024
Recently, recommender system has achieved significant success. However, due to the openness of recommender systems, they remain vulnerable to malicious attacks. Additionally, natural noise in training data and issues such as data sparsity can also degrade the performance of recommender systems. Therefore, enhancing the robustness of recommender systems has become an increasingly important research topic. In this survey, we provide a comprehensive overview of the robustness of recommender systems. Based on our investigation, we categorize the robustness of recommender systems into adversarial robustness and non-adversarial robustness. In the adversarial robustness, we introduce the fundamental principles and classical methods of recommender system adversarial attacks and defenses. In the non-adversarial robustness, we analyze non-adversarial robustness from the perspectives of data sparsity, natural noise, and data imbalance. Additionally, we summarize commonly used datasets and evaluation metrics for evaluating the robustness of recommender systems. Finally, we also discuss the current challenges in the field of recommender system robustness and potential future research directions. Additionally, to facilitate fair and efficient evaluation of attack and defense methods in adversarial robustness, we propose an adversarial robustness evaluation library--ShillingREC, and we conduct evaluations of basic attack models and recommendation models. ShillingREC project is released at https://github.com/chengleileilei/ShillingREC.
Decomposition for Enhancing Attention: Improving LLM-based Text-to-SQL through Workflow Paradigm
Feb 16, 2024In-context learning of large-language models (LLMs) has achieved remarkable success in the field of natural language processing, while extensive case studies reveal that the single-step chain-of-thought prompting approach faces challenges such as attention diffusion and inadequate performance in complex tasks like text-to-SQL. To improve the contextual learning capabilities of LLMs in text-to-SQL, a workflow paradigm method is proposed, aiming to enhance the attention and problem-solving scope of LLMs through decomposition. Specifically, the information determination module for eliminating redundant information and the brand-new prompt structure based on problem classification greatly enhance the model's attention. Additionally, the inclusion of self-correcting and active learning modules greatly expands the problem-solving scope of LLMs, hence improving the upper limit of LLM-based approaches. Extensive experiments conducted on three datasets demonstrate that our approach outperforms other methods by a significant margin. About 2-3 percentage point improvements compared to the existing baseline on the Spider Dev and Spider-Realistic datasets and new SOTA results on the Spider Test dataset are achieved. Our code is available on GitHub: \url{https://github.com/FlyingFeather/DEA-SQL}.
Activity Detection for Massive Connectivity in Cell-free Networks with Unknown Large-scale Fading, Channel Statistics, Noise Variance, and Activity Probability: A Bayesian Approach
Feb 02, 2024Activity detection is an important task in the next generation grant-free multiple access. While there are a number of existing algorithms designed for this purpose, they mostly require precise information about the network, such as large-scale fading coefficients, small-scale fading channel statistics, noise variance at the access points, and user activity probability. Acquiring these information would take a significant overhead and their estimated values might not be accurate. This problem is even more severe in cell-free networks as there are many of these parameters to be acquired. Therefore, this paper sets out to investigate the activity detection problem without the above-mentioned information. In order to handle so many unknown parameters, this paper employs the Bayesian approach, where the unknown variables are endowed with prior distributions which effectively act as regularizations. Together with the likelihood function, a maximum a posteriori (MAP) estimator and a variational inference algorithm are derived. Extensive simulations demonstrate that the proposed methods, even without the knowledge of these system parameters, perform better than existing state-of-the-art methods, such as covariance-based and approximate message passing methods.
Integrated Sensing and Communication with Massive MIMO: A Unified Tensor Approach for Channel and Target Parameter Estimation
Jan 03, 2024Benefitting from the vast spatial degrees of freedom, the amalgamation of integrated sensing and communication (ISAC) and massive multiple-input multiple-output (MIMO) is expected to simultaneously improve spectral and energy efficiencies as well as the sensing capability. However, a large number of antennas deployed in massive MIMO-ISAC raises critical challenges in acquiring both accurate channel state information and target parameter information. To overcome these two challenges with a unified framework, we first analyze their underlying system models and then propose a novel tensor-based approach that addresses both the channel estimation and target sensing problems. Specifically, by parameterizing the high-dimensional communication channel exploiting a small number of physical parameters, we associate the channel state information with the sensing parameters of targets in terms of angular, delay, and Doppler dimensions. Then, we propose a shared training pattern adopting the same time-frequency resources such that both the channel estimation and target parameter estimation can be formulated as a canonical polyadic decomposition problem with a similar mathematical expression. On this basis, we first investigate the uniqueness condition of the tensor factorization and the maximum number of resolvable targets by utilizing the specific Vandermonde
Knowledgeable Preference Alignment for LLMs in Domain-specific Question Answering
Nov 11, 2023Recently, the development of large language models (LLMs) has attracted wide attention in academia and industry. Deploying LLMs to real scenarios is one of the key directions in the current Internet industry. In this paper, we present a novel pipeline to apply LLMs for domain-specific question answering (QA) that incorporates domain knowledge graphs (KGs), addressing an important direction of LLM application. As a real-world application, the content generated by LLMs should be user-friendly to serve the customers. Additionally, the model needs to utilize domain knowledge properly to generate reliable answers. These two issues are the two major difficulties in the LLM application as vanilla fine-tuning can not adequately address them. We think both requirements can be unified as the model preference problem that needs to align with humans to achieve practical application. Thus, we introduce Knowledgeable Preference AlignmenT (KnowPAT), which constructs two kinds of preference set called style preference set and knowledge preference set respectively to tackle the two issues. Besides, we design a new alignment objective to align the LLM preference with human preference, aiming to train a better LLM for real-scenario domain-specific QA to generate reliable and user-friendly answers. Adequate experiments and comprehensive with 15 baseline methods demonstrate that our KnowPAT is an outperforming pipeline for real-scenario domain-specific QA with LLMs. Our code is open-source at https://github.com/zjukg/KnowPAT.
Online Targetless Radar-Camera Extrinsic Calibration Based on the Common Features of Radar and Camera
Sep 02, 2023



Sensor fusion is essential for autonomous driving and autonomous robots, and radar-camera fusion systems have gained popularity due to their complementary sensing capabilities. However, accurate calibration between these two sensors is crucial to ensure effective fusion and improve overall system performance. Calibration involves intrinsic and extrinsic calibration, with the latter being particularly important for achieving accurate sensor fusion. Unfortunately, many target-based calibration methods require complex operating procedures and well-designed experimental conditions, posing challenges for researchers attempting to reproduce the results. To address this issue, we introduce a novel approach that leverages deep learning to extract a common feature from raw radar data (i.e., Range-Doppler-Angle data) and camera images. Instead of explicitly representing these common features, our method implicitly utilizes these common features to match identical objects from both data sources. Specifically, the extracted common feature serves as an example to demonstrate an online targetless calibration method between the radar and camera systems. The estimation of the extrinsic transformation matrix is achieved through this feature-based approach. To enhance the accuracy and robustness of the calibration, we apply the RANSAC and Levenberg-Marquardt (LM) nonlinear optimization algorithm for deriving the matrix. Our experiments in the real world demonstrate the effectiveness and accuracy of our proposed method.
Striking The Right Balance: Three-Dimensional Ocean Sound Speed Field Reconstruction Using Tensor Neural Networks
Aug 09, 2023
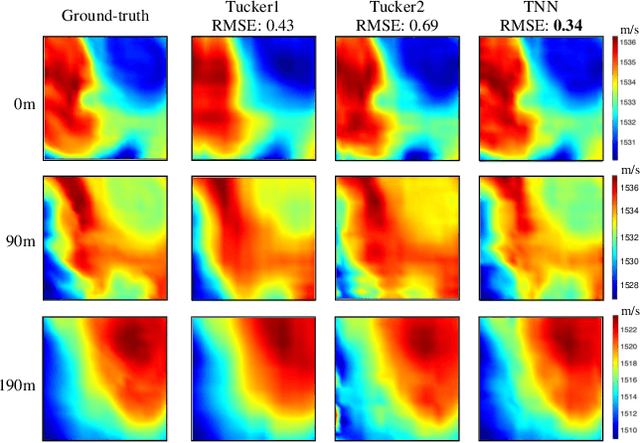
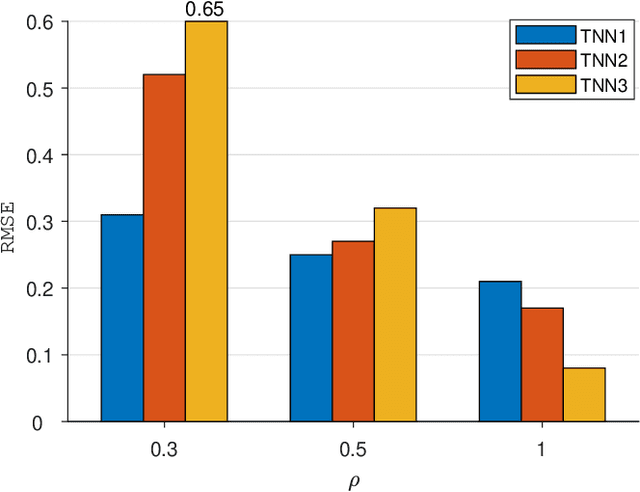
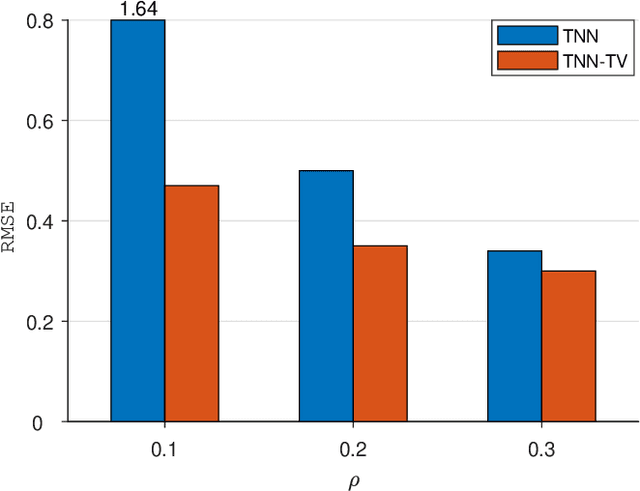
Accurately reconstructing a three-dimensional ocean sound speed field (3D SSF) is essential for various ocean acoustic applications, but the sparsity and uncertainty of sound speed samples across a vast ocean region make it a challenging task. To tackle this challenge, a large body of reconstruction methods has been developed, including spline interpolation, matrix/tensor-based completion, and deep neural networks-based reconstruction. However, a principled analysis of their effectiveness in 3D SSF reconstruction is still lacking. This paper performs a thorough analysis of the reconstruction error and highlights the need for a balanced representation model that integrates both expressiveness and conciseness. To meet this requirement, a 3D SSF-tailored tensor deep neural network is proposed, which utilizes tensor computations and deep neural network architectures to achieve remarkable 3D SSF reconstruction. The proposed model not only includes the previous tensor-based SSF representation model as a special case, but also has a natural ability to reject noise. The numerical results using the South China Sea 3D SSF data demonstrate that the proposed method outperforms state-of-the-art methods. The code is available at https://github.com/OceanSTARLab/Tensor-Neural-Network.
3D Radar and Camera Co-Calibration: A Flexible and Accurate Method for Target-based Extrinsic Calibration
Jul 28, 2023



Advances in autonomous driving are inseparable from sensor fusion. Heterogeneous sensors are widely used for sensor fusion due to their complementary properties, with radar and camera being the most equipped sensors. Intrinsic and extrinsic calibration are essential steps in sensor fusion. The extrinsic calibration, independent of the sensor's own parameters, and performed after the sensors are installed, greatly determines the accuracy of sensor fusion. Many target-based methods require cumbersome operating procedures and well-designed experimental conditions, making them extremely challenging. To this end, we propose a flexible, easy-to-reproduce and accurate method for extrinsic calibration of 3D radar and camera. The proposed method does not require a specially designed calibration environment, and instead places a single corner reflector (CR) on the ground to iteratively collect radar and camera data simultaneously using Robot Operating System (ROS), and obtain radar-camera point correspondences based on their timestamps, and then use these point correspondences as input to solve the perspective-n-point (PnP) problem, and finally get the extrinsic calibration matrix. Also, RANSAC is used for robustness and the Levenberg-Marquardt (LM) nonlinear optimization algorithm is used for accuracy. Multiple controlled environment experiments as well as real-world experiments demonstrate the efficiency and accuracy (AED error is 15.31 pixels and Acc up to 89\%) of the proposed method.
Multipath Time-delay Estimation with Impulsive Noise via Bayesian Compressive Sensing
Jul 05, 2023



Multipath time-delay estimation is commonly encountered in radar and sonar signal processing. In some real-life environments, impulse noise is ubiquitous and significantly degrades estimation performance. Here, we propose a Bayesian approach to tailor the Bayesian Compressive Sensing (BCS) to mitigate impulsive noises. In particular, a heavy-tail Laplacian distribution is used as a statistical model for impulse noise, while Laplacian prior is used for sparse multipath modeling. The Bayesian learning problem contains hyperparameters learning and parameter estimation, solved under the BCS inference framework. The performance of our proposed method is compared with benchmark methods, including compressive sensing (CS), BCS, and Laplacian-prior BCS (L-BCS). The simulation results show that our proposed method can estimate the multipath parameters more accurately and have a lower root mean squared estimation error (RMSE) in intensely impulsive noise.
To Fold or Not to Fold: Graph Regularized Tensor Train for Visual Data Completion
Jun 19, 2023
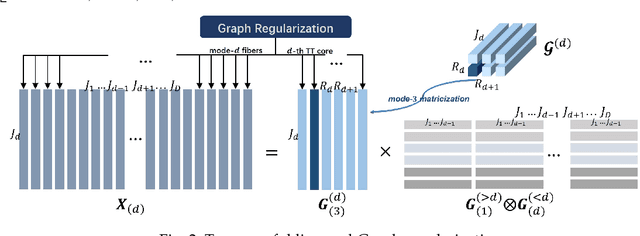
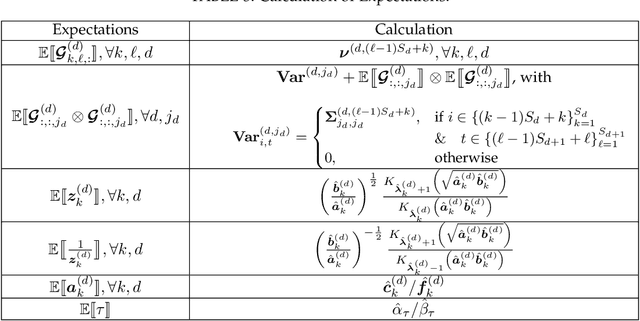
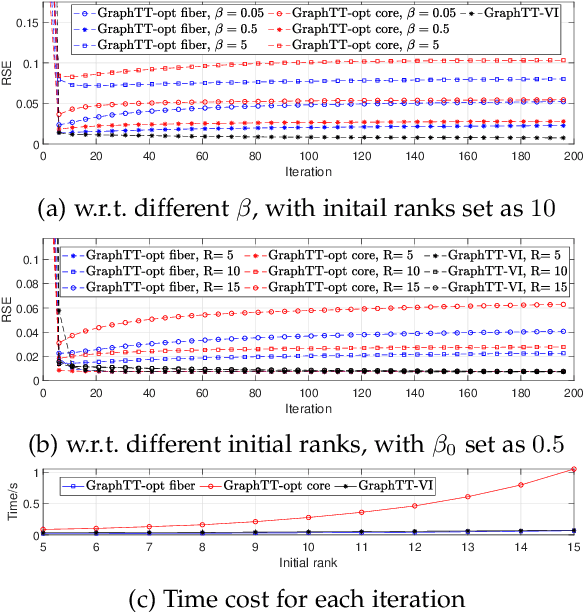
Tensor train (TT) representation has achieved tremendous success in visual data completion tasks, especially when it is combined with tensor folding. However, folding an image or video tensor breaks the original data structure, leading to local information loss as nearby pixels may be assigned into different dimensions and become far away from each other. In this paper, to fully preserve the local information of the original visual data, we explore not folding the data tensor, and at the same time adopt graph information to regularize local similarity between nearby entries. To overcome the high computational complexity introduced by the graph-based regularization in the TT completion problem, we propose to break the original problem into multiple sub-problems with respect to each TT core fiber, instead of each TT core as in traditional methods. Furthermore, to avoid heavy parameter tuning, a sparsity promoting probabilistic model is built based on the generalized inverse Gaussian (GIG) prior, and an inference algorithm is derived under the mean-field approximation. Experiments on both synthetic data and real-world visual data show the superiority of the proposed methods.