 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTing Zhang
VolumeDiffusion: Flexible Text-to-3D Generation with Efficient Volumetric Encoder
Dec 18, 2023
This paper introduces a pioneering 3D volumetric encoder designed for text-to-3D generation. To scale up the training data for the diffusion model, a lightweight network is developed to efficiently acquire feature volumes from multi-view images. The 3D volumes are then trained on a diffusion model for text-to-3D generation using a 3D U-Net. This research further addresses the challenges of inaccurate object captions and high-dimensional feature volumes. The proposed model, trained on the public Objaverse dataset, demonstrates promising outcomes in producing diverse and recognizable samples from text prompts. Notably, it empowers finer control over object part characteristics through textual cues, fostering model creativity by seamlessly combining multiple concepts within a single object. This research significantly contributes to the progress of 3D generation by introducing an efficient, flexible, and scalable representation methodology. Code is available at https://github.com/tzco/VolumeDiffusion.
Customize-It-3D: High-Quality 3D Creation from A Single Image Using Subject-Specific Knowledge Prior
Dec 15, 2023In this paper, we present a novel two-stage approach that fully utilizes the information provided by the reference image to establish a customized knowledge prior for image-to-3D generation. While previous approaches primarily rely on a general diffusion prior, which struggles to yield consistent results with the reference image, we propose a subject-specific and multi-modal diffusion model. This model not only aids NeRF optimization by considering the shading mode for improved geometry but also enhances texture from the coarse results to achieve superior refinement. Both aspects contribute to faithfully aligning the 3D content with the subject. Extensive experiments showcase the superiority of our method, Customize-It-3D, outperforming previous works by a substantial margin. It produces faithful 360-degree reconstructions with impressive visual quality, making it well-suited for various applications, including text-to-3D creation.
Model-enhanced Vector Index
Sep 23, 2023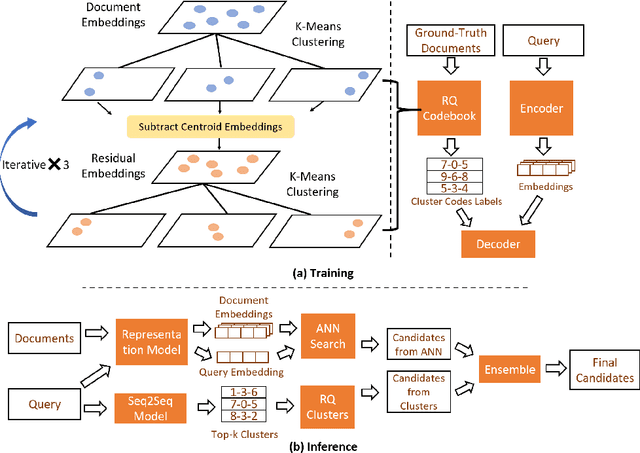

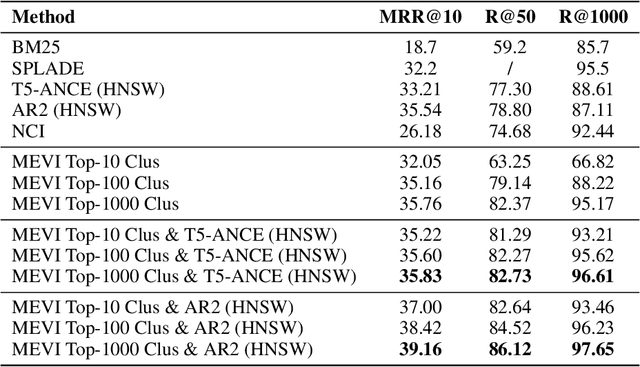
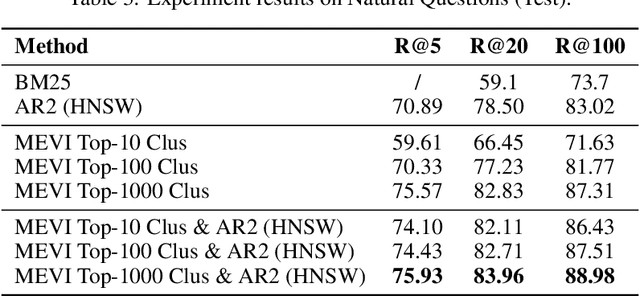
Embedding-based retrieval methods construct vector indices to search for document representations that are most similar to the query representations. They are widely used in document retrieval due to low latency and decent recall performance. Recent research indicates that deep retrieval solutions offer better model quality, but are hindered by unacceptable serving latency and the inability to support document updates. In this paper, we aim to enhance the vector index with end-to-end deep generative models, leveraging the differentiable advantages of deep retrieval models while maintaining desirable serving efficiency. We propose Model-enhanced Vector Index (MEVI), a differentiable model-enhanced index empowered by a twin-tower representation model. MEVI leverages a Residual Quantization (RQ) codebook to bridge the sequence-to-sequence deep retrieval and embedding-based models. To substantially reduce the inference time, instead of decoding the unique document ids in long sequential steps, we first generate some semantic virtual cluster ids of candidate documents in a small number of steps, and then leverage the well-adapted embedding vectors to further perform a fine-grained search for the relevant documents in the candidate virtual clusters. We empirically show that our model achieves better performance on the commonly used academic benchmarks MSMARCO Passage and Natural Questions, with comparable serving latency to dense retrieval solutions.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023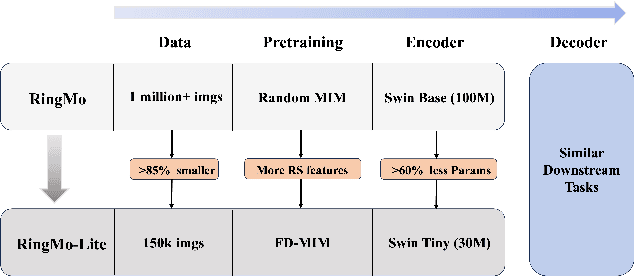
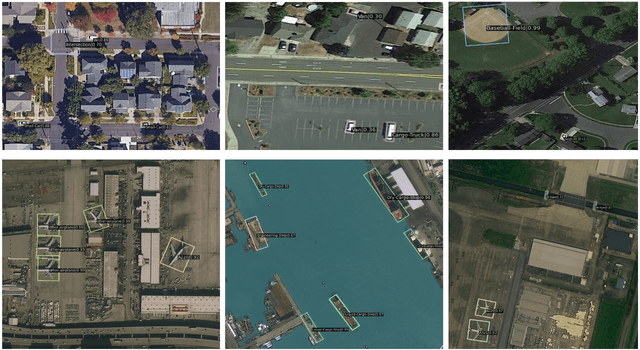
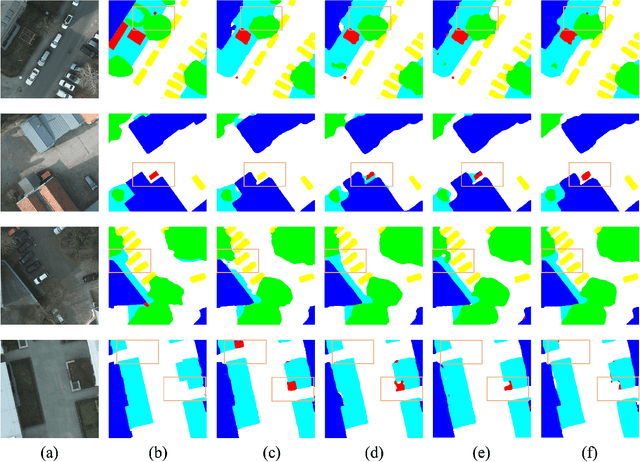
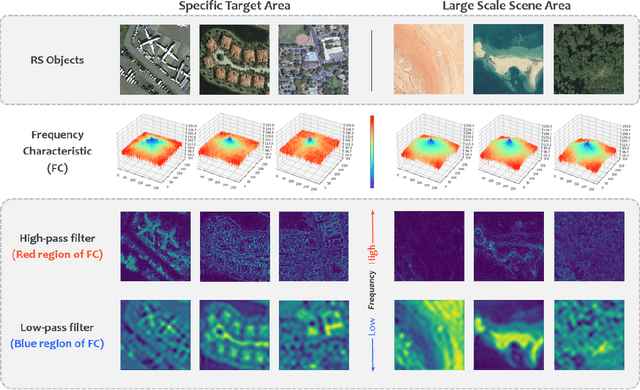
In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.
InstructDiffusion: A Generalist Modeling Interface for Vision Tasks
Sep 07, 2023
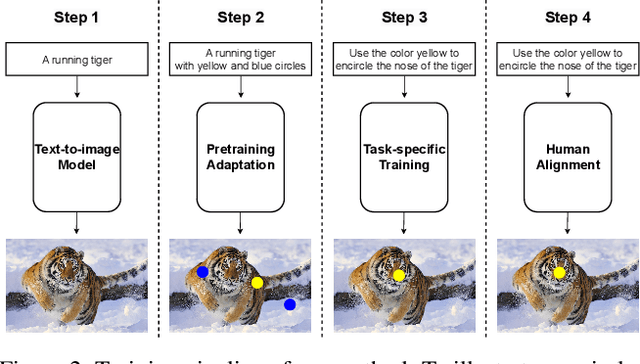

We present InstructDiffusion, a unifying and generic framework for aligning computer vision tasks with human instructions. Unlike existing approaches that integrate prior knowledge and pre-define the output space (e.g., categories and coordinates) for each vision task, we cast diverse vision tasks into a human-intuitive image-manipulating process whose output space is a flexible and interactive pixel space. Concretely, the model is built upon the diffusion process and is trained to predict pixels according to user instructions, such as encircling the man's left shoulder in red or applying a blue mask to the left car. InstructDiffusion could handle a variety of vision tasks, including understanding tasks (such as segmentation and keypoint detection) and generative tasks (such as editing and enhancement). It even exhibits the ability to handle unseen tasks and outperforms prior methods on novel datasets. This represents a significant step towards a generalist modeling interface for vision tasks, advancing artificial general intelligence in the field of computer vision.
Striking The Right Balance: Three-Dimensional Ocean Sound Speed Field Reconstruction Using Tensor Neural Networks
Aug 09, 2023
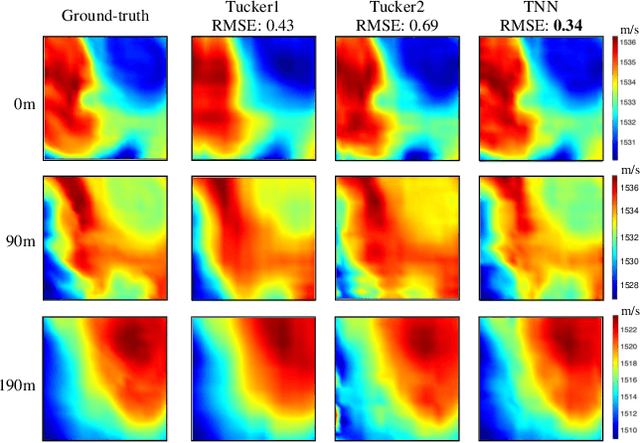
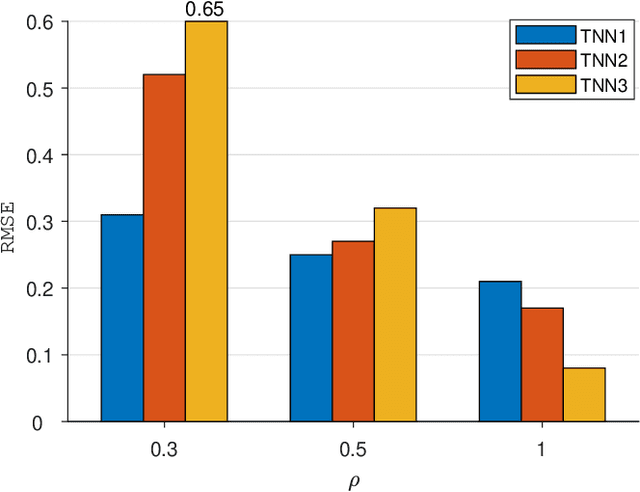
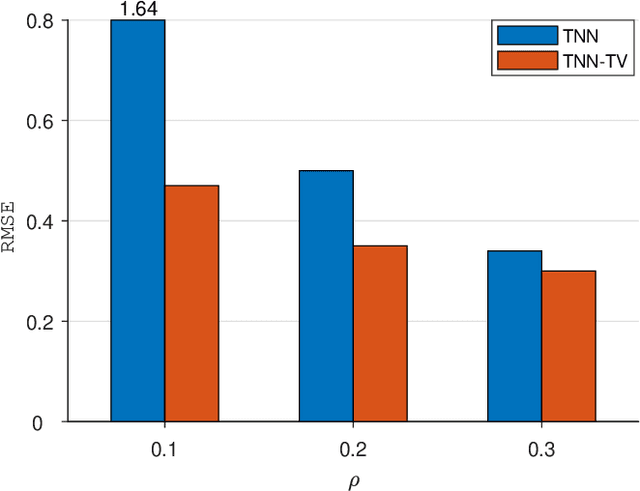
Accurately reconstructing a three-dimensional ocean sound speed field (3D SSF) is essential for various ocean acoustic applications, but the sparsity and uncertainty of sound speed samples across a vast ocean region make it a challenging task. To tackle this challenge, a large body of reconstruction methods has been developed, including spline interpolation, matrix/tensor-based completion, and deep neural networks-based reconstruction. However, a principled analysis of their effectiveness in 3D SSF reconstruction is still lacking. This paper performs a thorough analysis of the reconstruction error and highlights the need for a balanced representation model that integrates both expressiveness and conciseness. To meet this requirement, a 3D SSF-tailored tensor deep neural network is proposed, which utilizes tensor computations and deep neural network architectures to achieve remarkable 3D SSF reconstruction. The proposed model not only includes the previous tensor-based SSF representation model as a special case, but also has a natural ability to reject noise. The numerical results using the South China Sea 3D SSF data demonstrate that the proposed method outperforms state-of-the-art methods. The code is available at https://github.com/OceanSTARLab/Tensor-Neural-Network.
Mimicking the Thinking Process for Emotion Recognition in Conversation with Prompts and Paraphrasing
Jun 11, 2023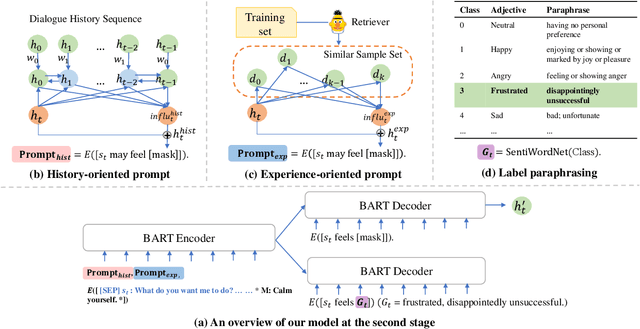
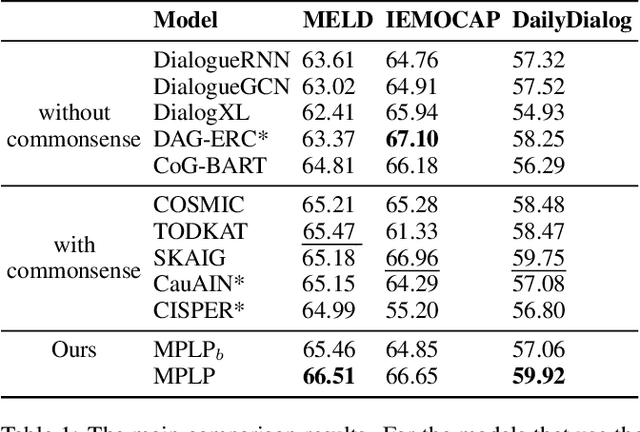
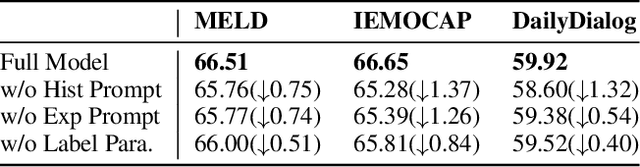
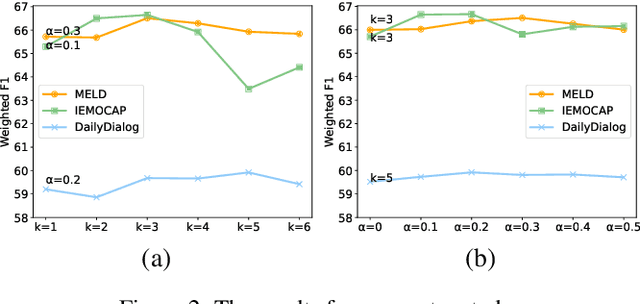
Emotion recognition in conversation, which aims to predict the emotion for all utterances, has attracted considerable research attention in recent years. It is a challenging task since the recognition of the emotion in one utterance involves many complex factors, such as the conversational context, the speaker's background, and the subtle difference between emotion labels. In this paper, we propose a novel framework which mimics the thinking process when modeling these factors. Specifically, we first comprehend the conversational context with a history-oriented prompt to selectively gather information from predecessors of the target utterance. We then model the speaker's background with an experience-oriented prompt to retrieve the similar utterances from all conversations. We finally differentiate the subtle label semantics with a paraphrasing mechanism to elicit the intrinsic label related knowledge. We conducted extensive experiments on three benchmarks. The empirical results demonstrate the superiority of our proposed framework over the state-of-the-art baselines.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023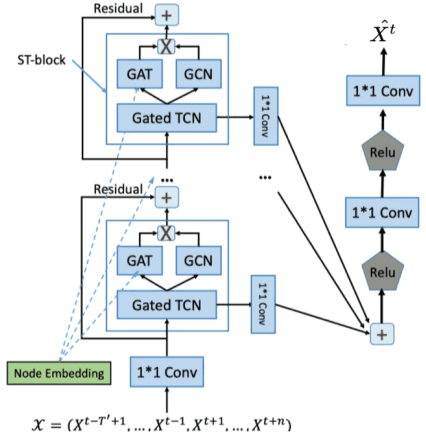
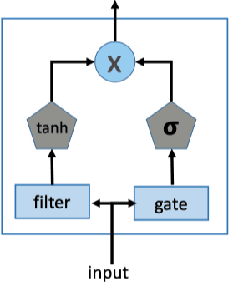
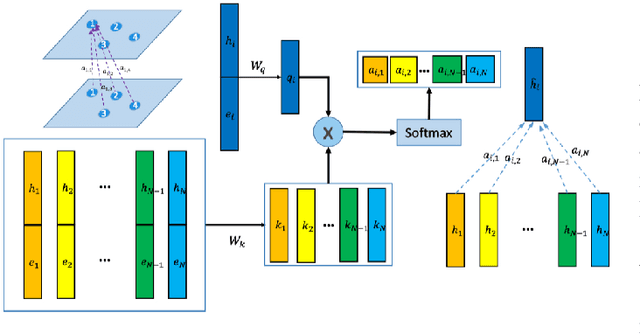
Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
Apr 03, 2023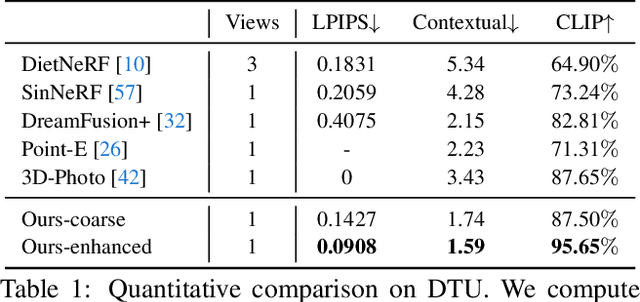
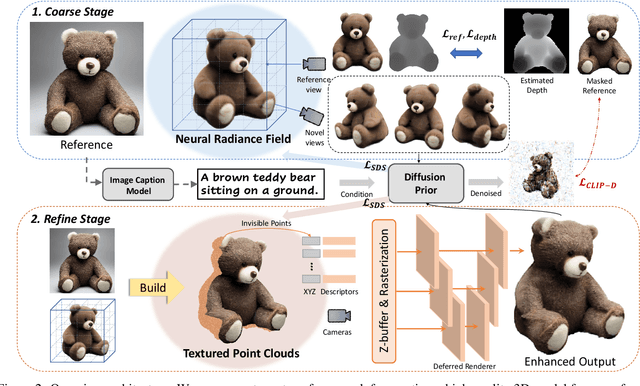
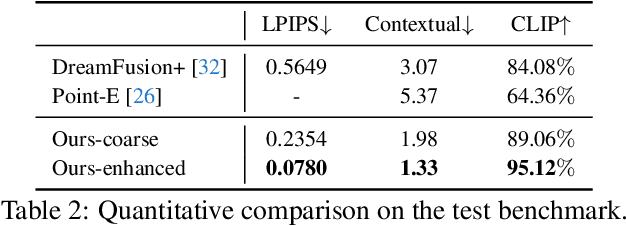

In this work, we investigate the problem of creating high-fidelity 3D content from only a single image. This is inherently challenging: it essentially involves estimating the underlying 3D geometry while simultaneously hallucinating unseen textures. To address this challenge, we leverage prior knowledge from a well-trained 2D diffusion model to act as 3D-aware supervision for 3D creation. Our approach, Make-It-3D, employs a two-stage optimization pipeline: the first stage optimizes a neural radiance field by incorporating constraints from the reference image at the frontal view and diffusion prior at novel views; the second stage transforms the coarse model into textured point clouds and further elevates the realism with diffusion prior while leveraging the high-quality textures from the reference image. Extensive experiments demonstrate that our method outperforms prior works by a large margin, resulting in faithful reconstructions and impressive visual quality. Our method presents the first attempt to achieve high-quality 3D creation from a single image for general objects and enables various applications such as text-to-3D creation and texture editing.
XAIR: A Framework of Explainable AI in Augmented Reality
Mar 28, 2023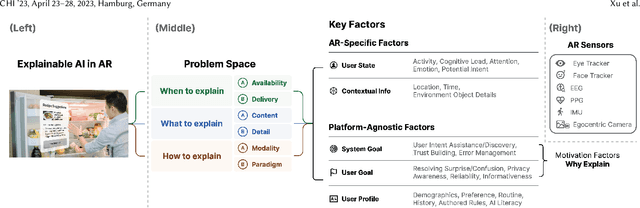
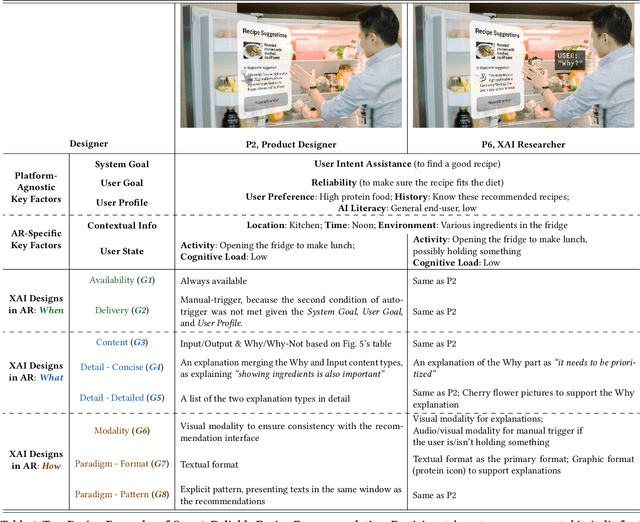

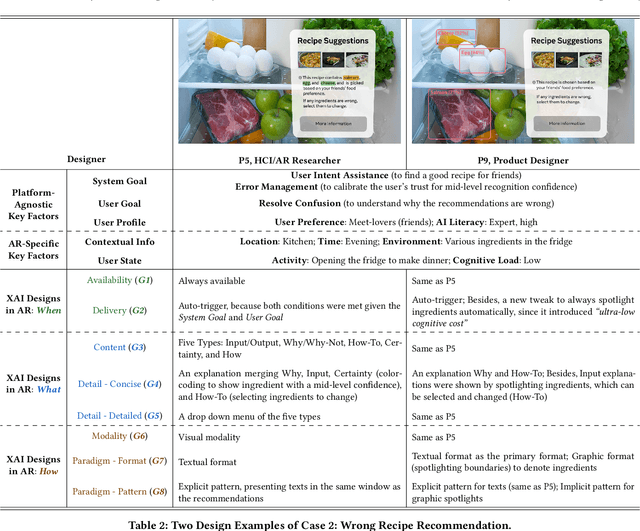
Explainable AI (XAI) has established itself as an important component of AI-driven interactive systems. With Augmented Reality (AR) becoming more integrated in daily lives, the role of XAI also becomes essential in AR because end-users will frequently interact with intelligent services. However, it is unclear how to design effective XAI experiences for AR. We propose XAIR, a design framework that addresses "when", "what", and "how" to provide explanations of AI output in AR. The framework was based on a multi-disciplinary literature review of XAI and HCI research, a large-scale survey probing 500+ end-users' preferences for AR-based explanations, and three workshops with 12 experts collecting their insights about XAI design in AR. XAIR's utility and effectiveness was verified via a study with 10 designers and another study with 12 end-users. XAIR can provide guidelines for designers, inspiring them to identify new design opportunities and achieve effective XAI designs in AR.