 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLetian Fu
Lifelong LERF: Local 3D Semantic Inventory Monitoring Using FogROS2
Mar 15, 2024
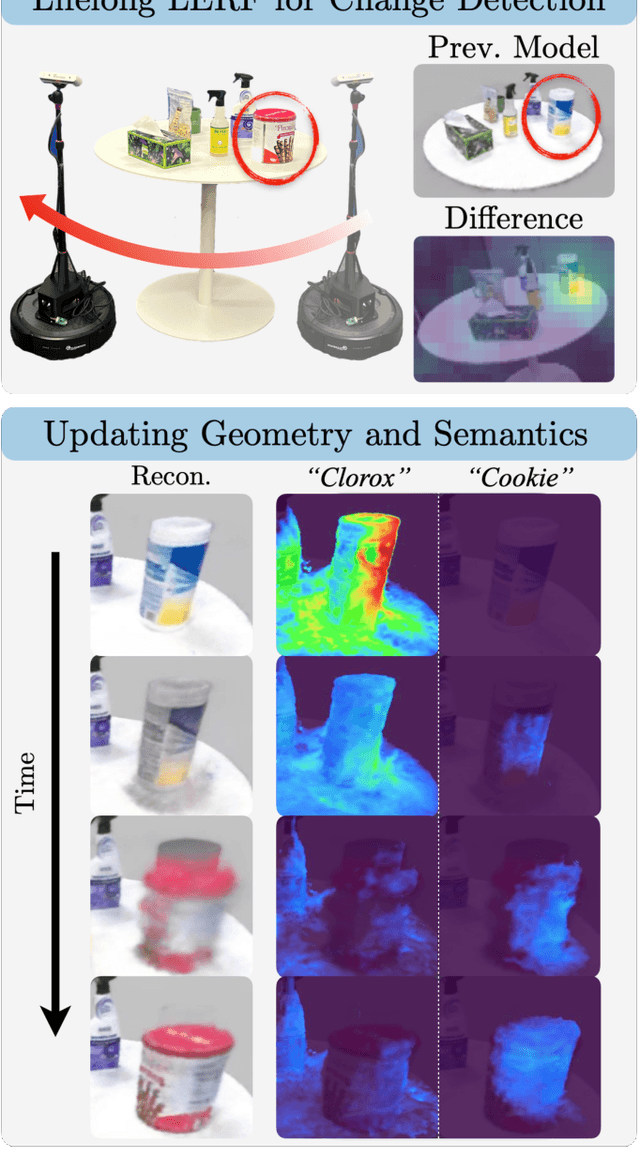
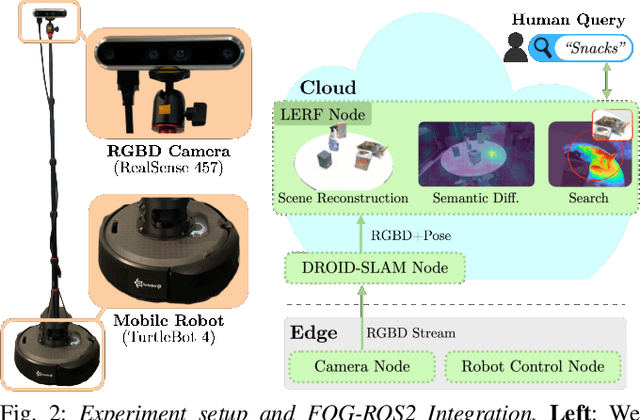
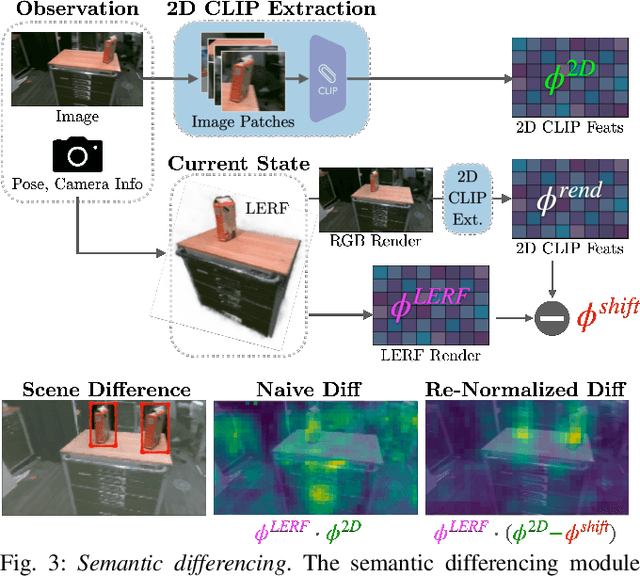

Inventory monitoring in homes, factories, and retail stores relies on maintaining data despite objects being swapped, added, removed, or moved. We introduce Lifelong LERF, a method that allows a mobile robot with minimal compute to jointly optimize a dense language and geometric representation of its surroundings. Lifelong LERF maintains this representation over time by detecting semantic changes and selectively updating these regions of the environment, avoiding the need to exhaustively remap. Human users can query inventory by providing natural language queries and receiving a 3D heatmap of potential object locations. To manage the computational load, we use Fog-ROS2, a cloud robotics platform, to offload resource-intensive tasks. Lifelong LERF obtains poses from a monocular RGBD SLAM backend, and uses these poses to progressively optimize a Language Embedded Radiance Field (LERF) for semantic monitoring. Experiments with 3-5 objects arranged on a tabletop and a Turtlebot with a RealSense camera suggest that Lifelong LERF can persistently adapt to changes in objects with up to 91% accuracy.
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
Rethinking Patch Dependence for Masked Autoencoders
Jan 25, 2024In this work, we re-examine inter-patch dependencies in the decoding mechanism of masked autoencoders (MAE). We decompose this decoding mechanism for masked patch reconstruction in MAE into self-attention and cross-attention. Our investigations suggest that self-attention between mask patches is not essential for learning good representations. To this end, we propose a novel pretraining framework: Cross-Attention Masked Autoencoders (CrossMAE). CrossMAE's decoder leverages only cross-attention between masked and visible tokens, with no degradation in downstream performance. This design also enables decoding only a small subset of mask tokens, boosting efficiency. Furthermore, each decoder block can now leverage different encoder features, resulting in improved representation learning. CrossMAE matches MAE in performance with 2.5 to 3.7$\times$ less decoding compute. It also surpasses MAE on ImageNet classification and COCO instance segmentation under the same compute. Code and models: https://crossmae.github.io
Robot Learning with Sensorimotor Pre-training
Jun 16, 2023
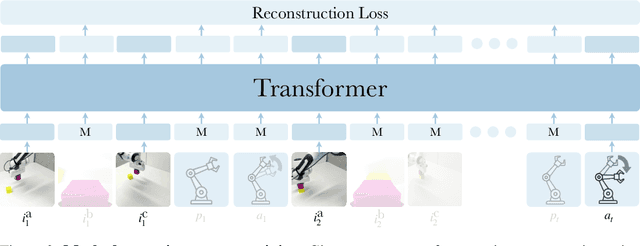
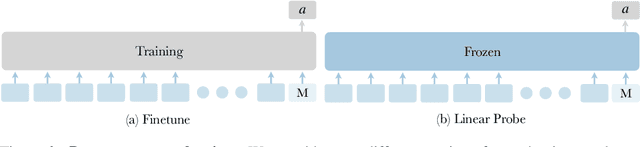
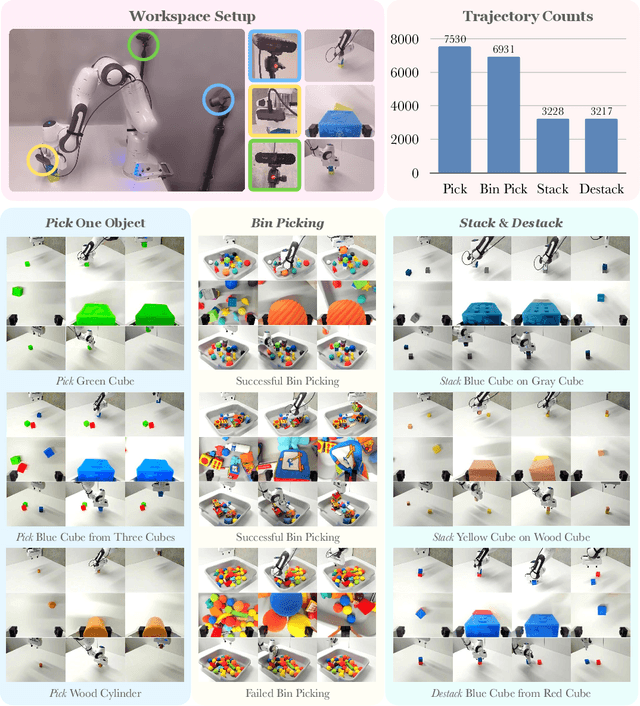
We present a self-supervised sensorimotor pre-training approach for robotics. Our model, called RPT, is a Transformer that operates on sequences of sensorimotor tokens. Given a sequence of camera images, proprioceptive robot states, and past actions, we encode the interleaved sequence into tokens, mask out a random subset, and train a model to predict the masked-out content. We hypothesize that if the robot can predict the missing content it has acquired a good model of the physical world that can enable it to act. RPT is designed to operate on latent visual representations which makes prediction tractable, enables scaling to 10x larger models, and 10 Hz inference on a real robot. To evaluate our approach, we collect a dataset of 20,000 real-world trajectories over 9 months using a combination of motion planning and model-based grasping algorithms. We find that pre-training on this data consistently outperforms training from scratch, leads to 2x improvements in the block stacking task, and has favorable scaling properties.
Safely Learning Visuo-Tactile Feedback Policies in Real For Industrial Insertion
Oct 04, 2022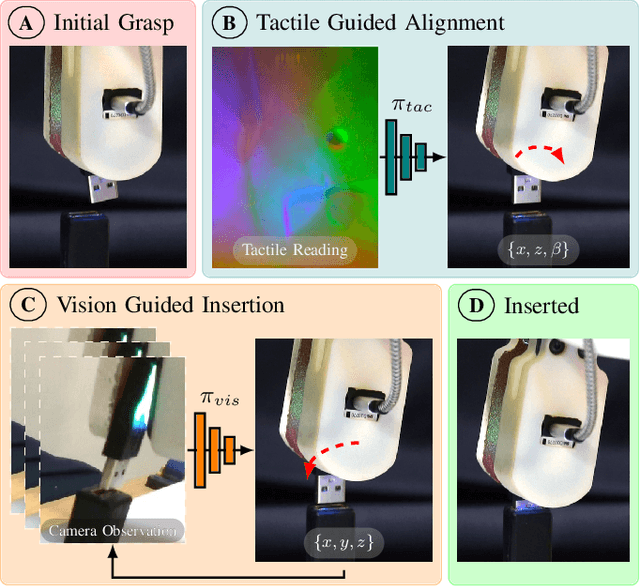
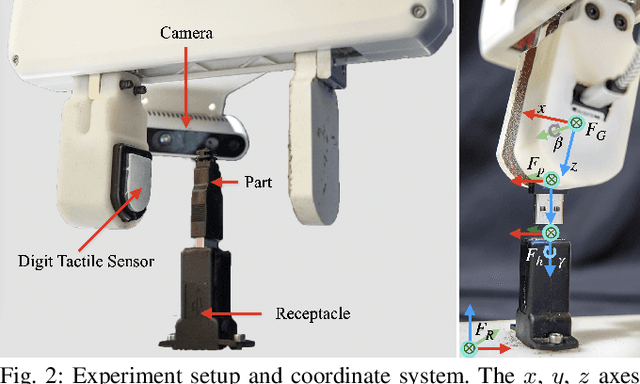


Industrial insertion tasks are often performed repetitively with parts that are subject to tight tolerances and prone to breakage. In this paper, we present a safe method to learn a visuo-tactile insertion policy that is robust against grasp pose variations while minimizing human inputs and collision between the robot and the environment. We achieve this by dividing the insertion task into two phases. In the first align phase, we learn a tactile-based grasp pose estimation model to align the insertion part with the receptacle. In the second insert phase, we learn a vision-based policy to guide the part into the receptacle. Using force-torque sensing, we also develop a safe self-supervised data collection pipeline that limits collision between the part and the surrounding environment. Physical experiments on the USB insertion task from the NIST Assembly Taskboard suggest that our approach can achieve 45/45 insertion successes on 45 different initial grasp poses, improving on two baselines: (1) a behavior cloning agent trained on 50 human insertion demonstrations (1/45) and (2) an online RL policy (TD3) trained in real (0/45).
Mechanical Search on Shelves with Efficient Stacking and Destacking of Objects
Jul 05, 2022
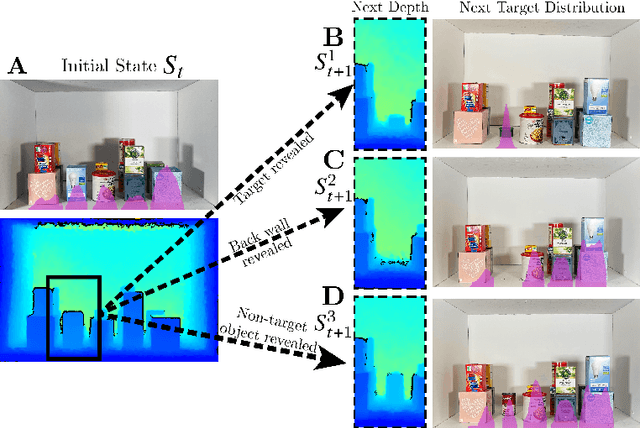

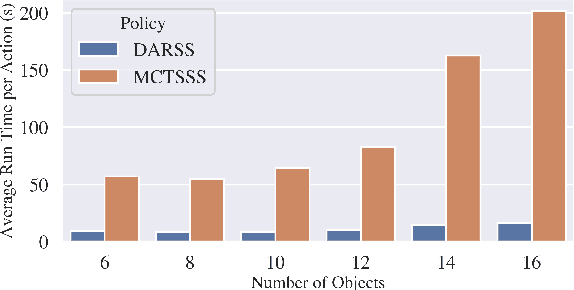
Stacking increases storage efficiency in shelves, but the lack of visibility and accessibility makes the mechanical search problem of revealing and extracting target objects difficult for robots. In this paper, we extend the lateral-access mechanical search problem to shelves with stacked items and introduce two novel policies -- Distribution Area Reduction for Stacked Scenes (DARSS) and Monte Carlo Tree Search for Stacked Scenes (MCTSSS) -- that use destacking and restacking actions. MCTSSS improves on prior lookahead policies by considering future states after each potential action. Experiments in 1200 simulated and 18 physical trials with a Fetch robot equipped with a blade and suction cup suggest that destacking and restacking actions can reveal the target object with 82--100% success in simulation and 66--100% in physical experiments, and are critical for searching densely packed shelves. In the simulation experiments, both policies outperform a baseline and achieve similar success rates but take more steps compared with an oracle policy that has full state information. In simulation and physical experiments, DARSS outperforms MCTSSS in median number of steps to reveal the target, but MCTSSS has a higher success rate in physical experiments, suggesting robustness to perception noise. See https://sites.google.com/berkeley.edu/stax-ray for supplementary material.
Mechanical Search on Shelves using a Novel "Bluction" Tool
Jan 22, 2022



Shelves are common in homes, warehouses, and commercial settings due to their storage efficiency. However, this efficiency comes at the cost of reduced visibility and accessibility. When looking from a side (lateral) view of a shelf, most objects will be fully occluded, resulting in a constrained lateral-access mechanical search problem. To address this problem, we introduce: (1) a novel bluction tool, which combines a thin pushing blade and suction cup gripper, (2) an improved LAX-RAY simulation pipeline and perception model that combines ray-casting with 2D Minkowski sums to efficiently generate target occupancy distributions, and (3) a novel SLAX-RAY search policy, which optimally reduces target object distribution support area using the bluction tool. Experimental data from 2000 simulated shelf trials and 18 trials with a physical Fetch robot equipped with the bluction tool suggest that using suction grasping actions improves the success rate over the highest performing push-only policy by 26% in simulation and 67% in physical environments.
LEGS: Learning Efficient Grasp Sets for Exploratory Grasping
Nov 29, 2021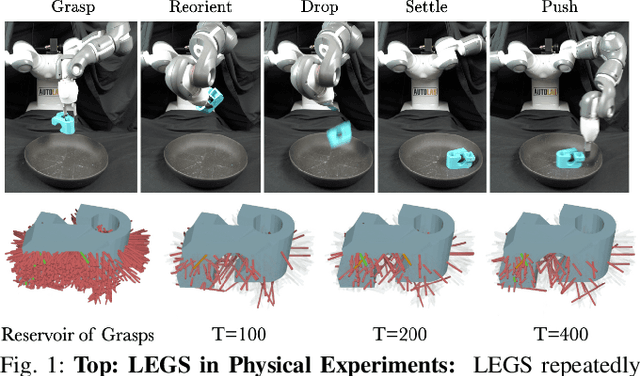

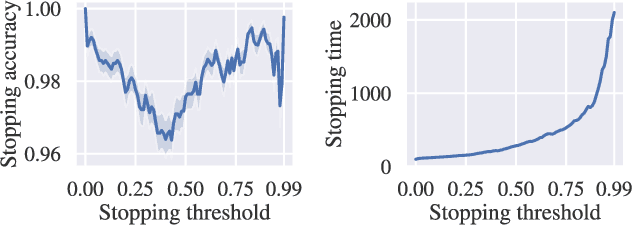

Previous work defined Exploratory Grasping, where a robot iteratively grasps and drops an unknown complex polyhedral object to discover a set of robust grasps for each recognizably distinct stable pose of the object. Recent work used a multi-armed bandit model with a small set of candidate grasps per pose; however, for objects with few successful grasps, this set may not include the most robust grasp. We present Learned Efficient Grasp Sets (LEGS), an algorithm that can efficiently explore thousands of possible grasps by constructing small active sets of promising grasps and uses learned confidence bounds to determine when, with high confidence, it can stop exploring the object. Experiments suggest that LEGS can identify a high-quality grasp more efficiently than prior algorithms which do not learn active sets. In simulation experiments, we measure the optimality gap between the success probability of the best grasp identified by LEGS and baselines and that of the true most robust grasp. After 3000 steps of exploration, LEGS outperforms baseline algorithms on 10 of the 14 Dex-Net Adversarial objects and 25 of the 39 EGAD! objects. We then develop a self-supervised grasping system, where the robot explores grasps with minimal human intervention. Physical experiments across 3 objects suggest that LEGS converges to high-performing grasps significantly faster than baselines. See \url{https://sites.google.com/view/legs-exp-grasping} for supplemental material and videos.