 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLi Xiao
SAMDA: Leveraging SAM on Few-Shot Domain Adaptation for Electronic Microscopy Segmentation
Mar 12, 2024
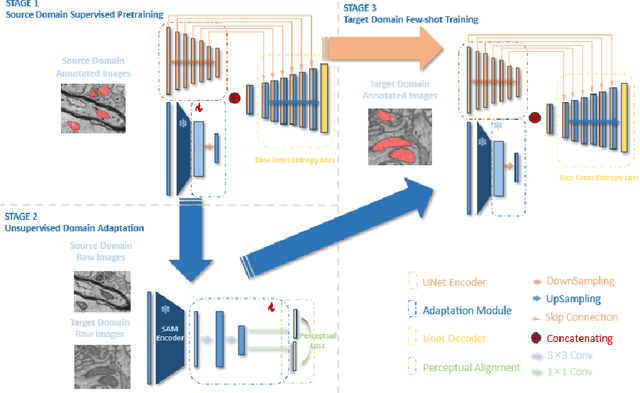
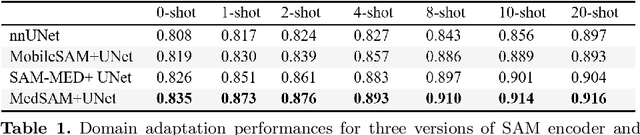
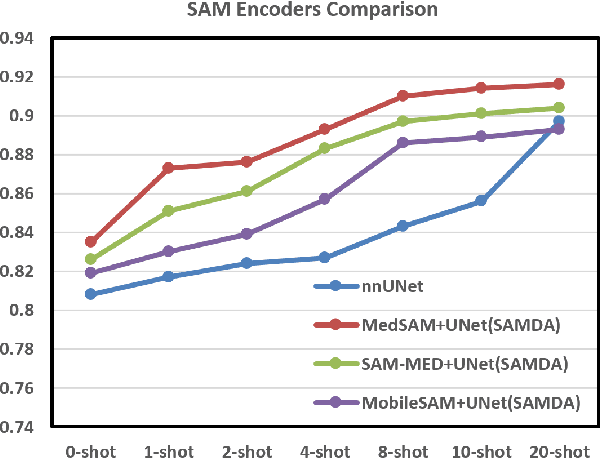
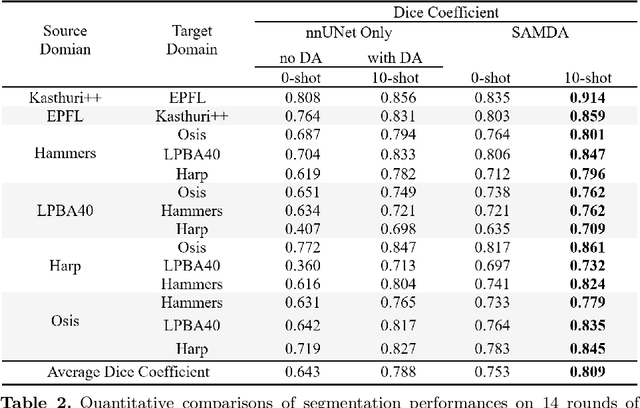
It has been shown that traditional deep learning methods for electronic microscopy segmentation usually suffer from low transferability when samples and annotations are limited, while large-scale vision foundation models are more robust when transferring between different domains but facing sub-optimal improvement under fine-tuning. In this work, we present a new few-shot domain adaptation framework SAMDA, which combines the Segment Anything Model(SAM) with nnUNet in the embedding space to achieve high transferability and accuracy. Specifically, we choose the Unet-based network as the "expert" component to learn segmentation features efficiently and design a SAM-based adaptation module as the "generic" component for domain transfer. By amalgamating the "generic" and "expert" components, we mitigate the modality imbalance in the complex pre-training knowledge inherent to large-scale Vision Foundation models and the challenge of transferability inherent to traditional neural networks. The effectiveness of our model is evaluated on two electron microscopic image datasets with different modalities for mitochondria segmentation, which improves the dice coefficient on the target domain by 6.7%. Also, the SAM-based adaptor performs significantly better with only a single annotated image than the 10-shot domain adaptation on nnUNet. We further verify our model on four MRI datasets from different sources to prove its generalization ability.
Exploring General Intelligence via Gated Graph Transformer in Functional Connectivity Studies
Jan 18, 2024Functional connectivity (FC) as derived from fMRI has emerged as a pivotal tool in elucidating the intricacies of various psychiatric disorders and delineating the neural pathways that underpin cognitive and behavioral dynamics inherent to the human brain. While Graph Neural Networks (GNNs) offer a structured approach to represent neuroimaging data, they are limited by their need for a predefined graph structure to depict associations between brain regions, a detail not solely provided by FCs. To bridge this gap, we introduce the Gated Graph Transformer (GGT) framework, designed to predict cognitive metrics based on FCs. Empirical validation on the Philadelphia Neurodevelopmental Cohort (PNC) underscores the superior predictive prowess of our model, further accentuating its potential in identifying pivotal neural connectivities that correlate with human cognitive processes.
Robust Multidimentional Chinese Remainder Theorem for Integer Vector Reconstruction
Nov 20, 2023The problem of robustly reconstructing an integer vector from its erroneous remainders appears in many applications in the field of multidimensional (MD) signal processing. To address this problem, a robust MD Chinese remainder theorem (CRT) was recently proposed for a special class of moduli, where the remaining integer matrices left-divided by a greatest common left divisor (gcld) of all the moduli are pairwise commutative and coprime. The strict constraint on the moduli limits the usefulness of the robust MD-CRT in practice. In this paper, we investigate the robust MD-CRT for a general set of moduli. We first introduce a necessary and sufficient condition on the difference between paired remainder errors, followed by a simple sufficient condition on the remainder error bound, for the robust MD-CRT for general moduli, where the conditions are associated with (the minimum distances of) these lattices generated by gcld's of paired moduli, and a closed-form reconstruction algorithm is presented. We then generalize the above results of the robust MD-CRT from integer vectors/matrices to real ones. Finally, we validate the robust MD-CRT for general moduli by employing numerical simulations, and apply it to MD sinusoidal frequency estimation based on multiple sub-Nyquist samplers.
CDR-Adapter: Learning Adapters to Dig Out More Transferring Ability for Cross-Domain Recommendation Models
Nov 04, 2023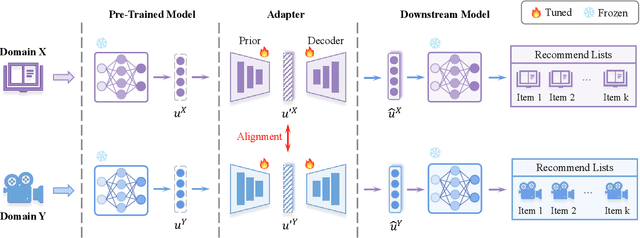

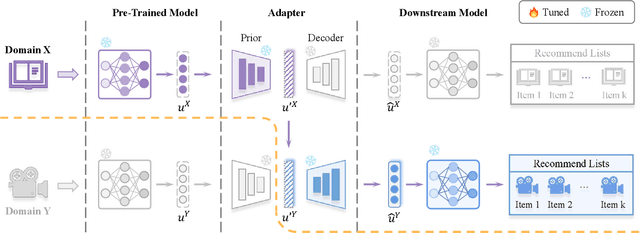
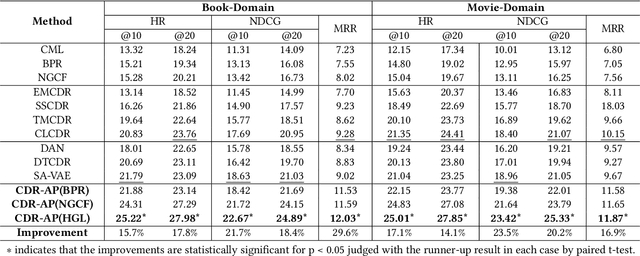
Data sparsity and cold-start problems are persistent challenges in recommendation systems. Cross-domain recommendation (CDR) is a promising solution that utilizes knowledge from the source domain to improve the recommendation performance in the target domain. Previous CDR approaches have mainly followed the Embedding and Mapping (EMCDR) framework, which involves learning a mapping function to facilitate knowledge transfer. However, these approaches necessitate re-engineering and re-training the network structure to incorporate transferrable knowledge, which can be computationally expensive and may result in catastrophic forgetting of the original knowledge. In this paper, we present a scalable and efficient paradigm to address data sparsity and cold-start issues in CDR, named CDR-Adapter, by decoupling the original recommendation model from the mapping function, without requiring re-engineering the network structure. Specifically, CDR-Adapter is a novel plug-and-play module that employs adapter modules to align feature representations, allowing for flexible knowledge transfer across different domains and efficient fine-tuning with minimal training costs. We conducted extensive experiments on the benchmark dataset, which demonstrated the effectiveness of our approach over several state-of-the-art CDR approaches.
MASTERKEY: Practical Backdoor Attack Against Speaker Verification Systems
Sep 13, 2023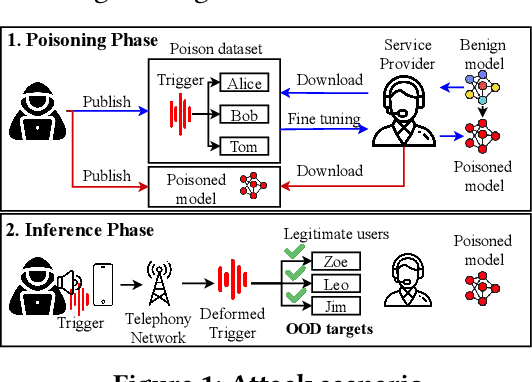
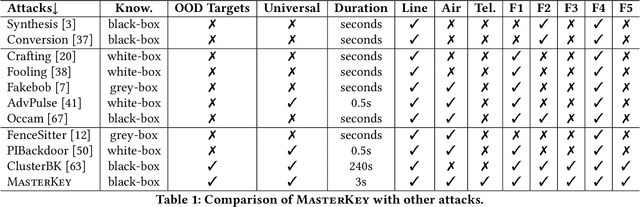
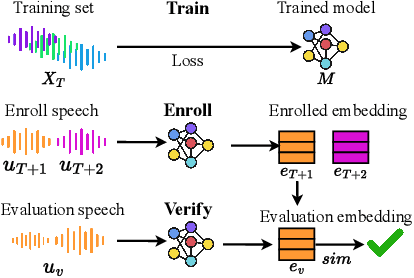
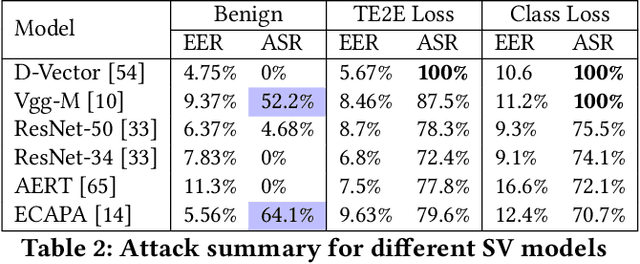
Speaker Verification (SV) is widely deployed in mobile systems to authenticate legitimate users by using their voice traits. In this work, we propose a backdoor attack MASTERKEY, to compromise the SV models. Different from previous attacks, we focus on a real-world practical setting where the attacker possesses no knowledge of the intended victim. To design MASTERKEY, we investigate the limitation of existing poisoning attacks against unseen targets. Then, we optimize a universal backdoor that is capable of attacking arbitrary targets. Next, we embed the speaker's characteristics and semantics information into the backdoor, making it imperceptible. Finally, we estimate the channel distortion and integrate it into the backdoor. We validate our attack on 6 popular SV models. Specifically, we poison a total of 53 models and use our trigger to attack 16,430 enrolled speakers, composed of 310 target speakers enrolled in 53 poisoned models. Our attack achieves 100% attack success rate with a 15% poison rate. By decreasing the poison rate to 3%, the attack success rate remains around 50%. We validate our attack in 3 real-world scenarios and successfully demonstrate the attack through both over-the-air and over-the-telephony-line scenarios.
PhantomSound: Black-Box, Query-Efficient Audio Adversarial Attack via Split-Second Phoneme Injection
Sep 13, 2023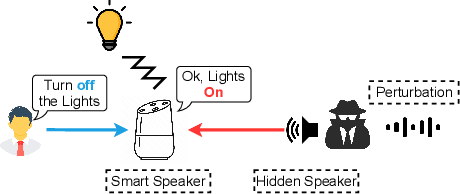
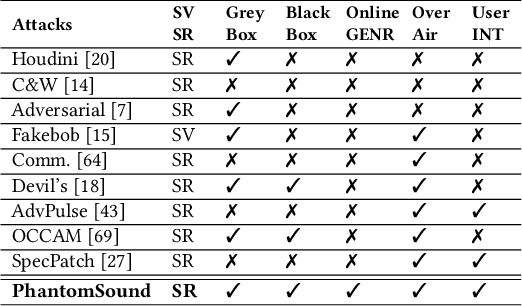
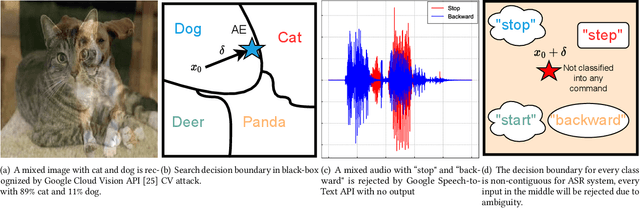

In this paper, we propose PhantomSound, a query-efficient black-box attack toward voice assistants. Existing black-box adversarial attacks on voice assistants either apply substitution models or leverage the intermediate model output to estimate the gradients for crafting adversarial audio samples. However, these attack approaches require a significant amount of queries with a lengthy training stage. PhantomSound leverages the decision-based attack to produce effective adversarial audios, and reduces the number of queries by optimizing the gradient estimation. In the experiments, we perform our attack against 4 different speech-to-text APIs under 3 real-world scenarios to demonstrate the real-time attack impact. The results show that PhantomSound is practical and robust in attacking 5 popular commercial voice controllable devices over the air, and is able to bypass 3 liveness detection mechanisms with >95% success rate. The benchmark result shows that PhantomSound can generate adversarial examples and launch the attack in a few minutes. We significantly enhance the query efficiency and reduce the cost of a successful untargeted and targeted adversarial attack by 93.1% and 65.5% compared with the state-of-the-art black-box attacks, using merely ~300 queries (~5 minutes) and ~1,500 queries (~25 minutes), respectively.
A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
Jul 25, 2023
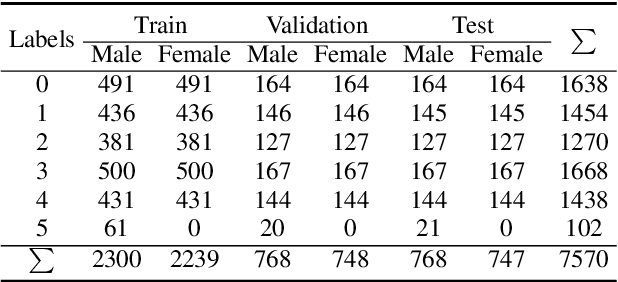
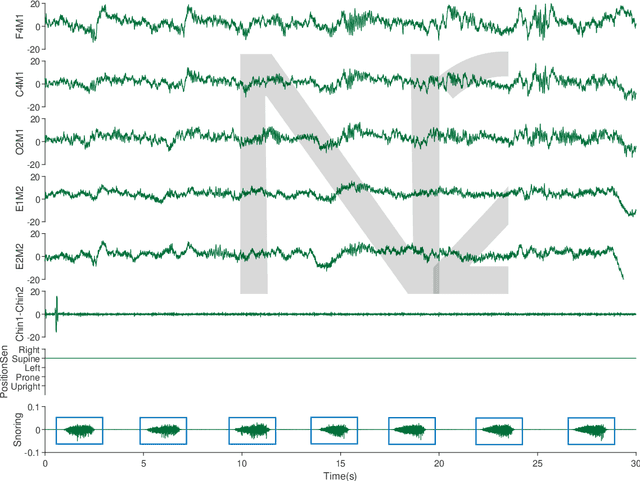
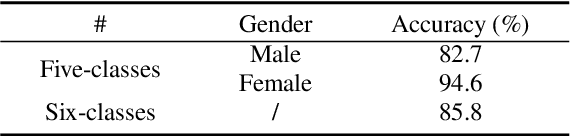
Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a chronic breathing disorder caused by a blockage in the upper airways. Snoring is a prominent symptom of OSAHS, and previous studies have attempted to identify the obstruction site of the upper airways by snoring sounds. Despite some progress, the classification of the obstruction site remains challenging in real-world clinical settings due to the influence of sleep body position on upper airways. To address this challenge, this paper proposes a snore-based sleep body position recognition dataset (SSBPR) consisting of 7570 snoring recordings, which comprises six distinct labels for sleep body position: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone. Experimental results show that snoring sounds exhibit certain acoustic features that enable their effective utilization for identifying body posture during sleep in real-world scenarios.
CQNV: A combination of coarsely quantized bitstream and neural vocoder for low rate speech coding
Jul 25, 2023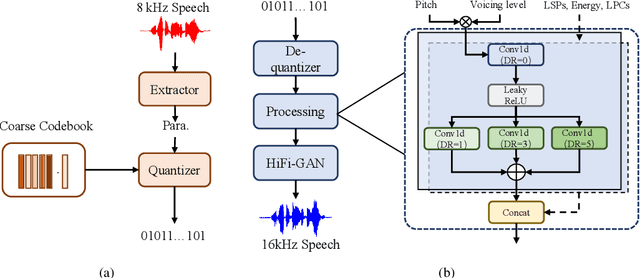

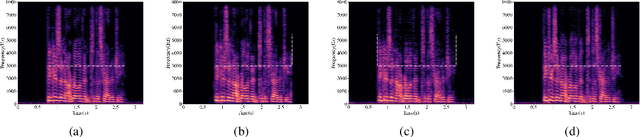

Recently, speech codecs based on neural networks have proven to perform better than traditional methods. However, redundancy in traditional parameter quantization is visible within the codec architecture of combining the traditional codec with the neural vocoder. In this paper, we propose a novel framework named CQNV, which combines the coarsely quantized parameters of a traditional parametric codec to reduce the bitrate with a neural vocoder to improve the quality of the decoded speech. Furthermore, we introduce a parameters processing module into the neural vocoder to enhance the application of the bitstream of traditional speech coding parameters to the neural vocoder, further improving the reconstructed speech's quality. In the experiments, both subjective and objective evaluations demonstrate the effectiveness of the proposed CQNV framework. Specifically, our proposed method can achieve higher quality reconstructed speech at 1.1 kbps than Lyra and Encodec at 3 kbps.
BEVStereo++: Accurate Depth Estimation in Multi-view 3D Object Detection via Dynamic Temporal Stereo
Apr 09, 2023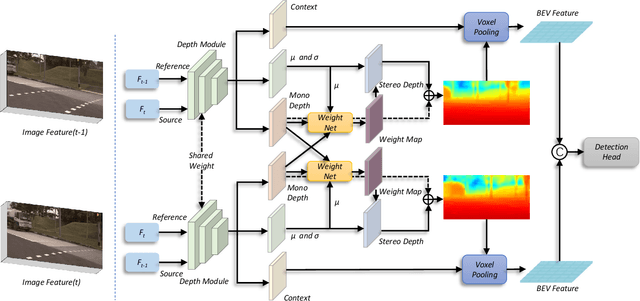

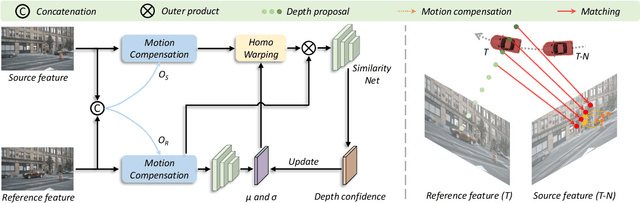
Bounded by the inherent ambiguity of depth perception, contemporary multi-view 3D object detection methods fall into the performance bottleneck. Intuitively, leveraging temporal multi-view stereo (MVS) technology is the natural knowledge for tackling this ambiguity. However, traditional attempts of MVS has two limitations when applying to 3D object detection scenes: 1) The affinity measurement among all views suffers expensive computational cost; 2) It is difficult to deal with outdoor scenarios where objects are often mobile. To this end, we propose BEVStereo++: by introducing a dynamic temporal stereo strategy, BEVStereo++ is able to cut down the harm that is brought by introducing temporal stereo when dealing with those two scenarios. Going one step further, we apply Motion Compensation Module and long sequence Frame Fusion to BEVStereo++, which shows further performance boosting and error reduction. Without bells and whistles, BEVStereo++ achieves state-of-the-art(SOTA) on both Waymo and nuScenes dataset.
NEC: Speaker Selective Cancellation via Neural Enhanced Ultrasound Shadowing
Jul 12, 2022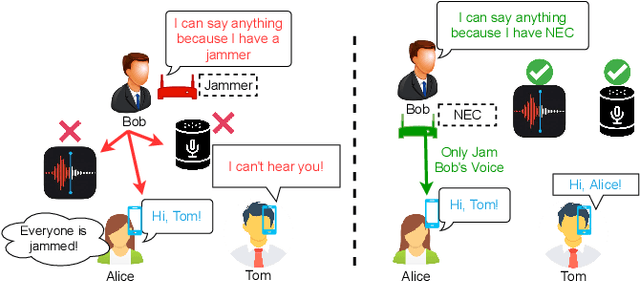


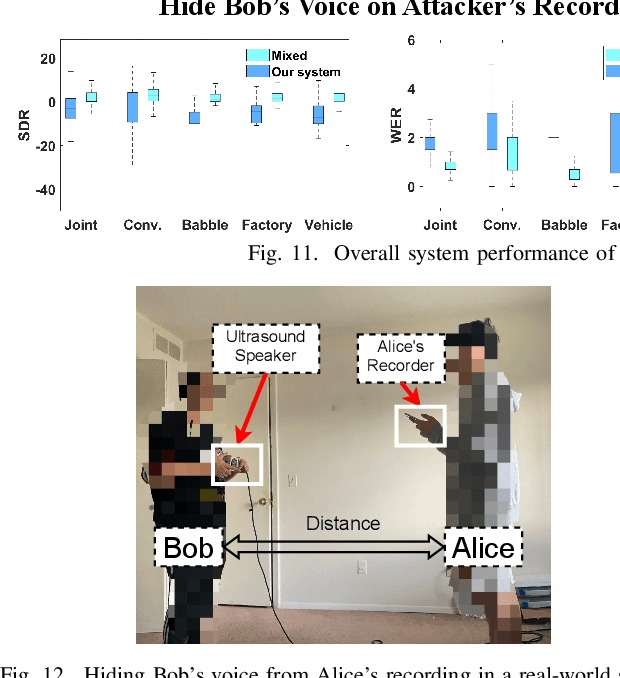
In this paper, we propose NEC (Neural Enhanced Cancellation), a defense mechanism, which prevents unauthorized microphones from capturing a target speaker's voice. Compared with the existing scrambling-based audio cancellation approaches, NEC can selectively remove a target speaker's voice from a mixed speech without causing interference to others. Specifically, for a target speaker, we design a Deep Neural Network (DNN) model to extract high-level speaker-specific but utterance-independent vocal features from his/her reference audios. When the microphone is recording, the DNN generates a shadow sound to cancel the target voice in real-time. Moreover, we modulate the audible shadow sound onto an ultrasound frequency, making it inaudible for humans. By leveraging the non-linearity of the microphone circuit, the microphone can accurately decode the shadow sound for target voice cancellation. We implement and evaluate NEC comprehensively with 8 smartphone microphones in different settings. The results show that NEC effectively mutes the target speaker at a microphone without interfering with other users' normal conversations.