 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeiping Tu
SE Territory: Monaural Speech Enhancement Meets the Fixed Virtual Perceptual Space Mapping
Nov 03, 2023
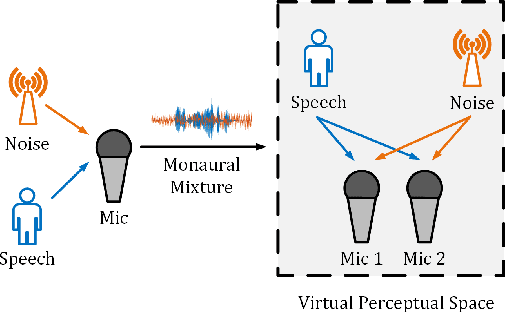
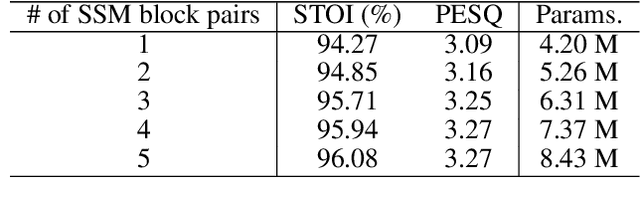

Monaural speech enhancement has achieved remarkable progress recently. However, its performance has been constrained by the limited spatial cues available at a single microphone. To overcome this limitation, we introduce a strategy to map monaural speech into a fixed simulation space for better differentiation between target speech and noise. Concretely, we propose SE-TerrNet, a novel monaural speech enhancement model featuring a virtual binaural speech mapping network via a two-stage multi-task learning framework. In the first stage, monaural noisy input is projected into a virtual space using supervised speech mapping blocks, creating binaural representations. These blocks synthesize binaural noisy speech from monaural input via an ideal binaural room impulse response. The synthesized output assigns speech and noise sources to fixed directions within the perceptual space. In the second stage, the obtained binaural features from the first stage are aggregated. This aggregation aims to decrease pattern discrepancies between the mapped binaural and original monaural features, achieved by implementing an intermediate fusion module. Furthermore, this stage incorporates the utilization of cross-attention to capture the injected virtual spatial information to improve the extraction of the target speech. Empirical studies highlight the effectiveness of virtual spatial cues in enhancing monaural speech enhancement. As a result, the proposed SE-TerrNet significantly surpasses the recent monaural speech enhancement methods in terms of both speech quality and intelligibility.
A comparative study of Grid and Natural sentences effects on Normal-to-Lombard conversion
Sep 19, 2023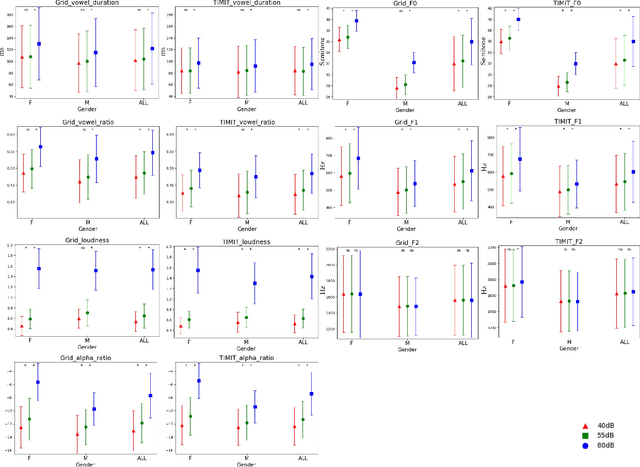

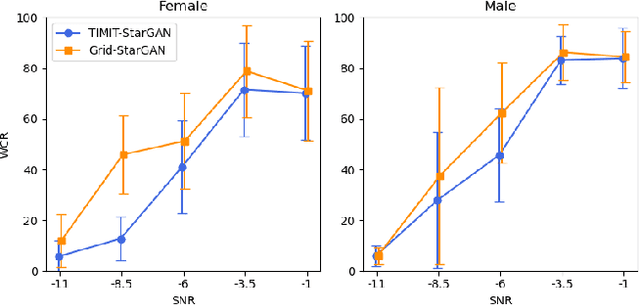
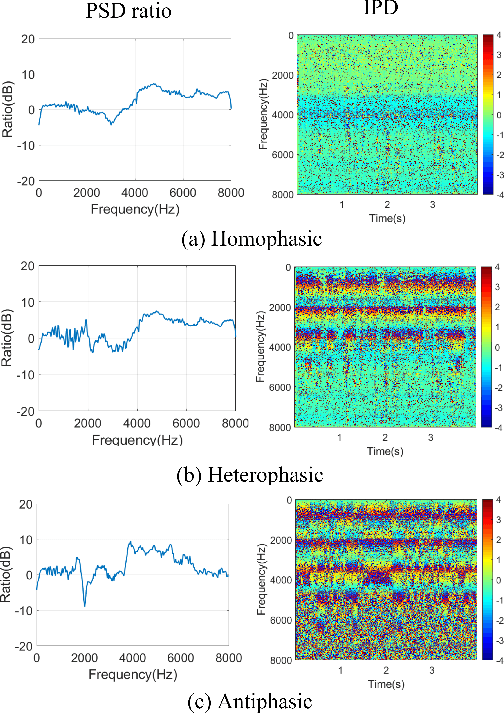
Grid sentence is commonly used for studying the Lombard effect and Normal-to-Lombard conversion. However, it's unclear if Normal-to-Lombard models trained on grid sentences are sufficient for improving natural speech intelligibility in real-world applications. This paper presents the recording of a parallel Lombard corpus (called Lombard Chinese TIMIT, LCT) extracting natural sentences from Chinese TIMIT. Then We compare natural and grid sentences in terms of Lombard effect and Normal-to-Lombard conversion using LCT and Enhanced MAndarin Lombard Grid corpus (EMALG). Through a parametric analysis of the Lombard effect, We find that as the noise level increases, both natural sentences and grid sentences exhibit similar changes in parameters, but in terms of the increase of the alpha ratio, grid sentences show a greater increase. Following a subjective intelligibility assessment across genders and Signal-to-Noise Ratios, the StarGAN model trained on EMALG consistently outperforms the model trained on LCT in terms of improving intelligibility. This superior performance may be attributed to EMALG's larger alpha ratio increase from normal to Lombard speech.
Mandarin Lombard Flavor Classification
Sep 14, 2023The Lombard effect refers to individuals' unconscious modulation of vocal effort in response to variations in the ambient noise levels, intending to enhance speech intelligibility. The impact of different decibel levels and types of background noise on Lombard effects remains unclear. Building upon the characteristic of Lombard speech that individuals adjust their speech to improve intelligibility dynamically based on the self-feedback speech, we propose a flavor classification approach for the Lombard effect. We first collected Mandarin Lombard speech under different noise conditions, then simulated self-feedback speech, and ultimately conducted the statistical test on the word correct rate. We found that both SSN and babble noise types result in four distinct categories of Mandarin Lombard speech in the range of 30 to 80 dBA with different transition points.
EMALG: An Enhanced Mandarin Lombard Grid Corpus with Meaningful Sentences
Sep 13, 2023This study investigates the Lombard effect, where individuals adapt their speech in noisy environments. We introduce an enhanced Mandarin Lombard grid (EMALG) corpus with meaningful sentences , enhancing the Mandarin Lombard grid (MALG) corpus. EMALG features 34 speakers and improves recording setups, addressing challenges faced by MALG with nonsense sentences. Our findings reveal that in Mandarin, female exhibit a more pronounced Lombard effect than male, particularly when uttering meaningful sentences. Additionally, we uncover that nonsense sentences negatively impact Lombard effect analysis. Moreover, our results reaffirm the consistency in the Lombard effect comparison between English and Mandarin found in previous research.
PCNN: A Lightweight Parallel Conformer Neural Network for Efficient Monaural Speech Enhancement
Jul 28, 2023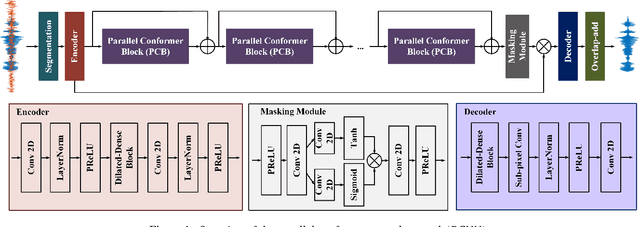

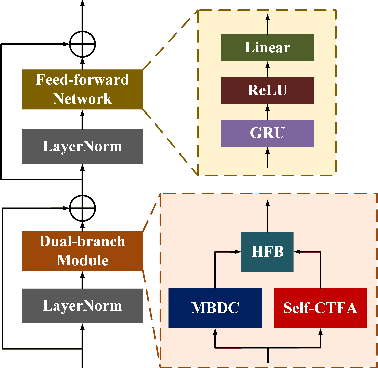
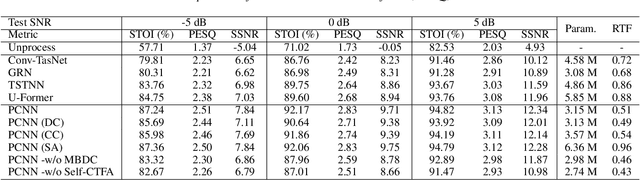
Convolutional neural networks (CNN) and Transformer have wildly succeeded in multimedia applications. However, more effort needs to be made to harmonize these two architectures effectively to satisfy speech enhancement. This paper aims to unify these two architectures and presents a Parallel Conformer for speech enhancement. In particular, the CNN and the self-attention (SA) in the Transformer are fully exploited for local format patterns and global structure representations. Based on the small receptive field size of CNN and the high computational complexity of SA, we specially designed a multi-branch dilated convolution (MBDC) and a self-channel-time-frequency attention (Self-CTFA) module. MBDC contains three convolutional layers with different dilation rates for the feature from local to non-local processing. Experimental results show that our method performs better than state-of-the-art methods in most evaluation criteria while maintaining the lowest model parameters.
Exploring the Interactions between Target Positive and Negative Information for Acoustic Echo Cancellation
Jul 26, 2023Acoustic echo cancellation (AEC) aims to remove interference signals while leaving near-end speech least distorted. As the indistinguishable patterns between near-end speech and interference signals, near-end speech can't be separated completely, causing speech distortion and interference signals residual. We observe that besides target positive information, e.g., ground-truth speech and features, the target negative information, such as interference signals and features, helps make pattern of target speech and interference signals more discriminative. Therefore, we present a novel AEC model encoder-decoder architecture with the guidance of negative information termed as CMNet. A collaboration module (CM) is designed to establish the correlation between the target positive and negative information in a learnable manner via three blocks: target positive, target negative, and interactive block. Experimental results demonstrate our CMNet achieves superior performance than recent methods.
A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
Jul 25, 2023
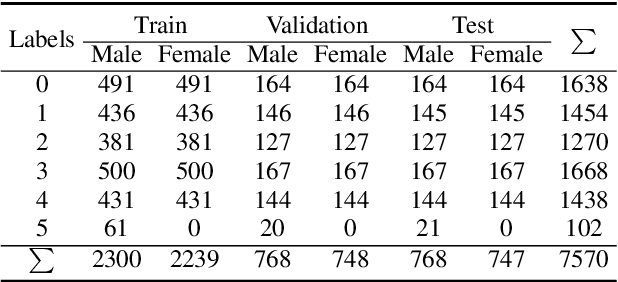
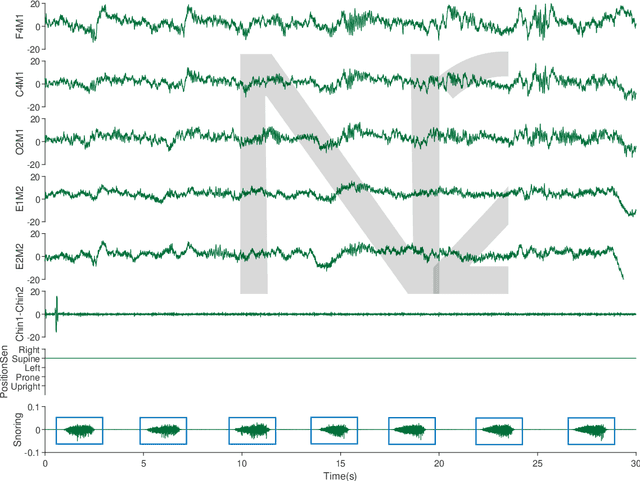
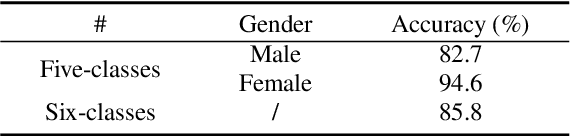
Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a chronic breathing disorder caused by a blockage in the upper airways. Snoring is a prominent symptom of OSAHS, and previous studies have attempted to identify the obstruction site of the upper airways by snoring sounds. Despite some progress, the classification of the obstruction site remains challenging in real-world clinical settings due to the influence of sleep body position on upper airways. To address this challenge, this paper proposes a snore-based sleep body position recognition dataset (SSBPR) consisting of 7570 snoring recordings, which comprises six distinct labels for sleep body position: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone. Experimental results show that snoring sounds exhibit certain acoustic features that enable their effective utilization for identifying body posture during sleep in real-world scenarios.
CQNV: A combination of coarsely quantized bitstream and neural vocoder for low rate speech coding
Jul 25, 2023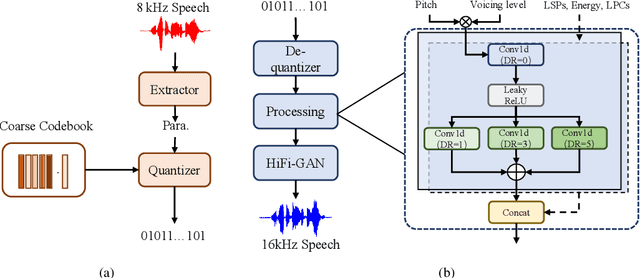

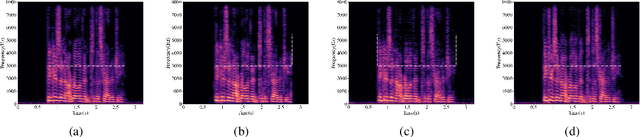

Recently, speech codecs based on neural networks have proven to perform better than traditional methods. However, redundancy in traditional parameter quantization is visible within the codec architecture of combining the traditional codec with the neural vocoder. In this paper, we propose a novel framework named CQNV, which combines the coarsely quantized parameters of a traditional parametric codec to reduce the bitrate with a neural vocoder to improve the quality of the decoded speech. Furthermore, we introduce a parameters processing module into the neural vocoder to enhance the application of the bitstream of traditional speech coding parameters to the neural vocoder, further improving the reconstructed speech's quality. In the experiments, both subjective and objective evaluations demonstrate the effectiveness of the proposed CQNV framework. Specifically, our proposed method can achieve higher quality reconstructed speech at 1.1 kbps than Lyra and Encodec at 3 kbps.
All Information is Necessary: Integrating Speech Positive and Negative Information by Contrastive Learning for Speech Enhancement
Apr 26, 2023



Monaural speech enhancement (SE) is an ill-posed problem due to the irreversible degradation process. Recent methods to achieve SE tasks rely solely on positive information, e.g., ground-truth speech and speech-relevant features. Different from the above, we observe that the negative information, such as original speech mixture and speech-irrelevant features, are valuable to guide the SE model training procedure. In this study, we propose a SE model that integrates both speech positive and negative information for improving SE performance by adopting contrastive learning, in which two innovations have consisted. (1) We design a collaboration module (CM), which contains two parts, contrastive attention for separating relevant and irrelevant features via contrastive learning and interactive attention for establishing the correlation between both speech features in a learnable and self-adaptive manner. (2) We propose a contrastive regularization (CR) built upon contrastive learning to ensure that the estimated speech is pulled closer to the clean speech and pushed far away from the noisy speech in the representation space by integrating self-supervised models. We term the proposed SE network with CM and CR as CMCR-Net. Experimental results demonstrate that our CMCR-Net achieves comparable and superior performance to recent approaches.
Selector-Enhancer: Learning Dynamic Selection of Local and Non-local Attention Operation for Speech Enhancement
Dec 07, 2022



Attention mechanisms, such as local and non-local attention, play a fundamental role in recent deep learning based speech enhancement (SE) systems. However, natural speech contains many fast-changing and relatively brief acoustic events, therefore, capturing the most informative speech features by indiscriminately using local and non-local attention is challenged. We observe that the noise type and speech feature vary within a sequence of speech and the local and non-local operations can respectively extract different features from corrupted speech. To leverage this, we propose Selector-Enhancer, a dual-attention based convolution neural network (CNN) with a feature-filter that can dynamically select regions from low-resolution speech features and feed them to local or non-local attention operations. In particular, the proposed feature-filter is trained by using reinforcement learning (RL) with a developed difficulty-regulated reward that is related to network performance, model complexity, and "the difficulty of the SE task". The results show that our method achieves comparable or superior performance to existing approaches. In particular, Selector-Enhancer is potentially effective for real-world denoising, where the number and types of noise are varies on a single noisy mixture.