 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiang Wan
CorrNet+: Sign Language Recognition and Translation via Spatial-Temporal Correlation
Apr 17, 2024
In sign language, the conveyance of human body trajectories predominantly relies upon the coordinated movements of hands and facial expressions across successive frames. Despite the recent advancements of sign language understanding methods, they often solely focus on individual frames, inevitably overlooking the inter-frame correlations that are essential for effectively modeling human body trajectories. To address this limitation, this paper introduces a spatial-temporal correlation network, denoted as CorrNet+, which explicitly identifies body trajectories across multiple frames. In specific, CorrNet+ employs a correlation module and an identification module to build human body trajectories. Afterwards, a temporal attention module is followed to adaptively evaluate the contributions of different frames. The resultant features offer a holistic perspective on human body movements, facilitating a deeper understanding of sign language. As a unified model, CorrNet+ achieves new state-of-the-art performance on two extensive sign language understanding tasks, including continuous sign language recognition (CSLR) and sign language translation (SLT). Especially, CorrNet+ surpasses previous methods equipped with resource-intensive pose-estimation networks or pre-extracted heatmaps for hand and facial feature extraction. Compared with CorrNet, CorrNet+ achieves a significant performance boost across all benchmarks while halving the computational overhead. A comprehensive comparison with previous spatial-temporal reasoning methods verifies the superiority of CorrNet+. Code is available at https://github.com/hulianyuyy/CorrNet_Plus.
Elastic Multi-Gradient Descent for Parallel Continual Learning
Jan 02, 2024The goal of Continual Learning (CL) is to continuously learn from new data streams and accomplish the corresponding tasks. Previously studied CL assumes that data are given in sequence nose-to-tail for different tasks, thus indeed belonging to Serial Continual Learning (SCL). This paper studies the novel paradigm of Parallel Continual Learning (PCL) in dynamic multi-task scenarios, where a diverse set of tasks is encountered at different time points. PCL presents challenges due to the training of an unspecified number of tasks with varying learning progress, leading to the difficulty of guaranteeing effective model updates for all encountered tasks. In our previous conference work, we focused on measuring and reducing the discrepancy among gradients in a multi-objective optimization problem, which, however, may still contain negative transfers in every model update. To address this issue, in the dynamic multi-objective optimization problem, we introduce task-specific elastic factors to adjust the descent direction towards the Pareto front. The proposed method, called Elastic Multi-Gradient Descent (EMGD), ensures that each update follows an appropriate Pareto descent direction, minimizing any negative impact on previously learned tasks. To balance the training between old and new tasks, we also propose a memory editing mechanism guided by the gradient computed using EMGD. This editing process updates the stored data points, reducing interference in the Pareto descent direction from previous tasks. Experiments on public datasets validate the effectiveness of our EMGD in the PCL setting.
Long-Tailed Learning as Multi-Objective Optimization
Nov 01, 2023Real-world data is extremely imbalanced and presents a long-tailed distribution, resulting in models that are biased towards classes with sufficient samples and perform poorly on rare classes. Recent methods propose to rebalance classes but they undertake the seesaw dilemma (what is increasing performance on tail classes may decrease that of head classes, and vice versa). In this paper, we argue that the seesaw dilemma is derived from gradient imbalance of different classes, in which gradients of inappropriate classes are set to important for updating, thus are prone to overcompensation or undercompensation on tail classes. To achieve ideal compensation, we formulate the long-tailed recognition as an multi-objective optimization problem, which fairly respects the contributions of head and tail classes simultaneously. For efficiency, we propose a Gradient-Balancing Grouping (GBG) strategy to gather the classes with similar gradient directions, thus approximately make every update under a Pareto descent direction. Our GBG method drives classes with similar gradient directions to form more representative gradient and provide ideal compensation to the tail classes. Moreover, We conduct extensive experiments on commonly used benchmarks in long-tailed learning and demonstrate the superiority of our method over existing SOTA methods.
Bilateral Network with Residual U-blocks and Dual-Guided Attention for Real-time Semantic Segmentation
Oct 31, 2023When some application scenarios need to use semantic segmentation technology, like automatic driving, the primary concern comes to real-time performance rather than extremely high segmentation accuracy. To achieve a good trade-off between speed and accuracy, two-branch architecture has been proposed in recent years. It treats spatial information and semantics information separately which allows the model to be composed of two networks both not heavy. However, the process of fusing features with two different scales becomes a performance bottleneck for many nowaday two-branch models. In this research, we design a new fusion mechanism for two-branch architecture which is guided by attention computation. To be precise, we use the Dual-Guided Attention (DGA) module we proposed to replace some multi-scale transformations with the calculation of attention which means we only use several attention layers of near linear complexity to achieve performance comparable to frequently-used multi-layer fusion. To ensure that our module can be effective, we use Residual U-blocks (RSU) to build one of the two branches in our networks which aims to obtain better multi-scale features. Extensive experiments on Cityscapes and CamVid dataset show the effectiveness of our method.
Open Compound Domain Adaptation with Object Style Compensation for Semantic Segmentation
Sep 28, 2023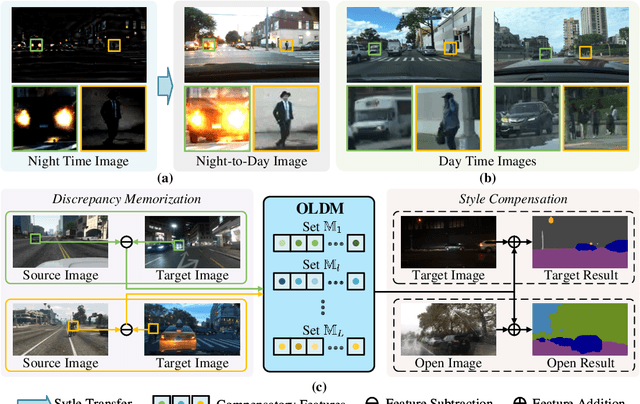
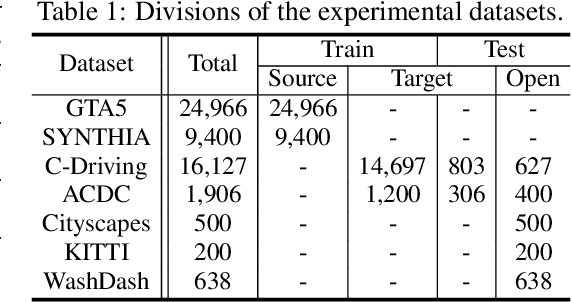
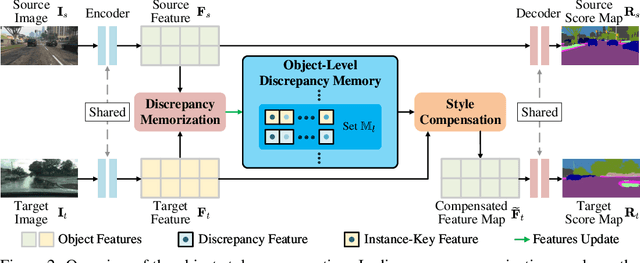
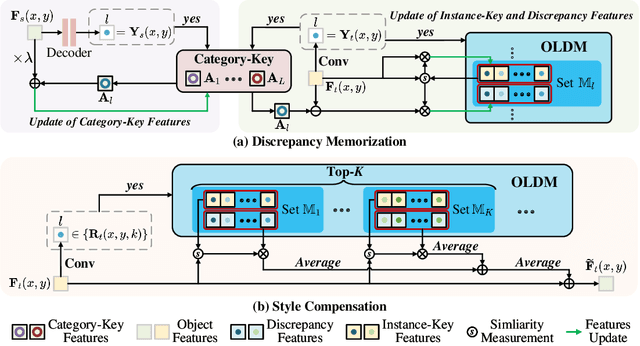
Many methods of semantic image segmentation have borrowed the success of open compound domain adaptation. They minimize the style gap between the images of source and target domains, more easily predicting the accurate pseudo annotations for target domain's images that train segmentation network. The existing methods globally adapt the scene style of the images, whereas the object styles of different categories or instances are adapted improperly. This paper proposes the Object Style Compensation, where we construct the Object-Level Discrepancy Memory with multiple sets of discrepancy features. The discrepancy features in a set capture the style changes of the same category's object instances adapted from target to source domains. We learn the discrepancy features from the images of source and target domains, storing the discrepancy features in memory. With this memory, we select appropriate discrepancy features for compensating the style information of the object instances of various categories, adapting the object styles to a unified style of source domain. Our method enables a more accurate computation of the pseudo annotations for target domain's images, thus yielding state-of-the-art results on different datasets.
Improving the Transferability of Adversarial Examples with Arbitrary Style Transfer
Aug 21, 2023
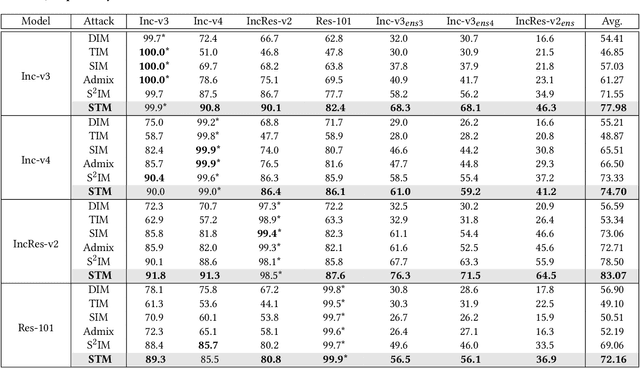
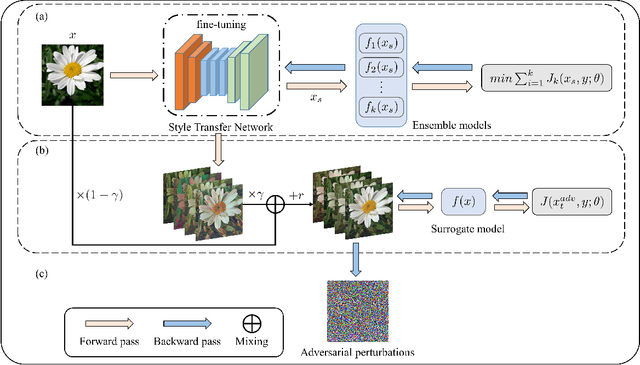
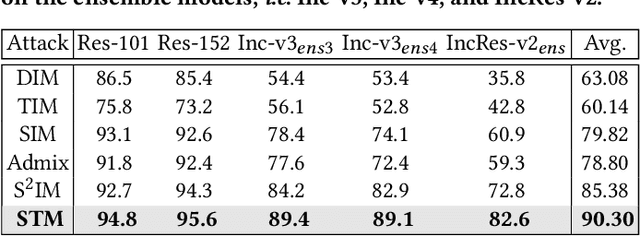
Deep neural networks are vulnerable to adversarial examples crafted by applying human-imperceptible perturbations on clean inputs. Although many attack methods can achieve high success rates in the white-box setting, they also exhibit weak transferability in the black-box setting. Recently, various methods have been proposed to improve adversarial transferability, in which the input transformation is one of the most effective methods. In this work, we notice that existing input transformation-based works mainly adopt the transformed data in the same domain for augmentation. Inspired by domain generalization, we aim to further improve the transferability using the data augmented from different domains. Specifically, a style transfer network can alter the distribution of low-level visual features in an image while preserving semantic content for humans. Hence, we propose a novel attack method named Style Transfer Method (STM) that utilizes a proposed arbitrary style transfer network to transform the images into different domains. To avoid inconsistent semantic information of stylized images for the classification network, we fine-tune the style transfer network and mix up the generated images added by random noise with the original images to maintain semantic consistency and boost input diversity. Extensive experimental results on the ImageNet-compatible dataset show that our proposed method can significantly improve the adversarial transferability on either normally trained models or adversarially trained models than state-of-the-art input transformation-based attacks. Code is available at: https://github.com/Zhijin-Ge/STM.
Multi-Loss Convolutional Network with Time-Frequency Attention for Speech Enhancement
Jun 15, 2023
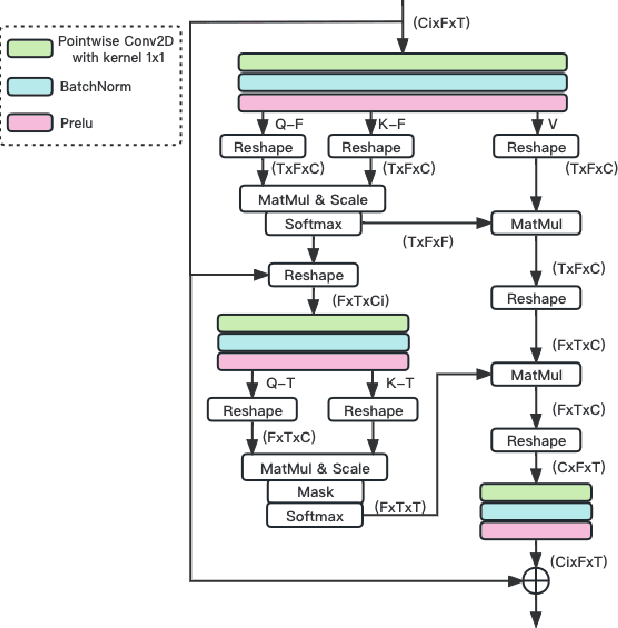
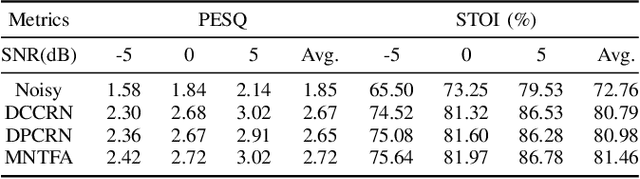
The Dual-Path Convolution Recurrent Network (DPCRN) was proposed to effectively exploit time-frequency domain information. By combining the DPRNN module with Convolution Recurrent Network (CRN), the DPCRN obtained a promising performance in speech separation with a limited model size. In this paper, we explore self-attention in the DPCRN module and design a model called Multi-Loss Convolutional Network with Time-Frequency Attention(MNTFA) for speech enhancement. We use self-attention modules to exploit the long-time information, where the intra-chunk self-attentions are used to model the spectrum pattern and the inter-chunk self-attention are used to model the dependence between consecutive frames. Compared to DPRNN, axial self-attention greatly reduces the need for memory and computation, which is more suitable for long sequences of speech signals. In addition, we propose a joint training method of a multi-resolution STFT loss and a WavLM loss using a pre-trained WavLM network. Experiments show that with only 0.23M parameters, the proposed model achieves a better performance than DPCRN.
HybridMIM: A Hybrid Masked Image Modeling Framework for 3D Medical Image Segmentation
Mar 18, 2023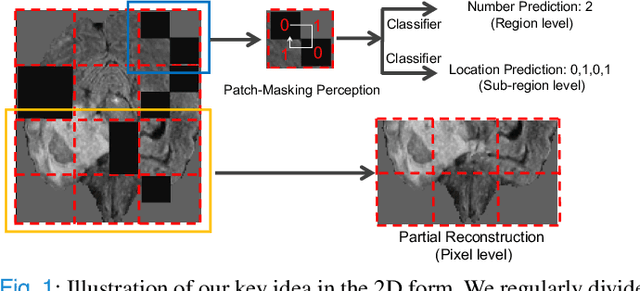
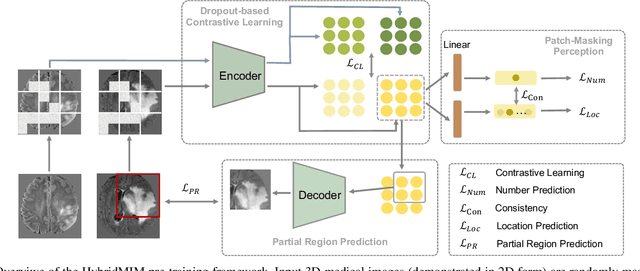
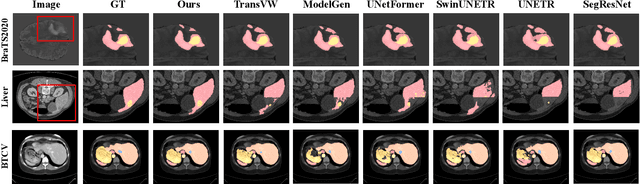
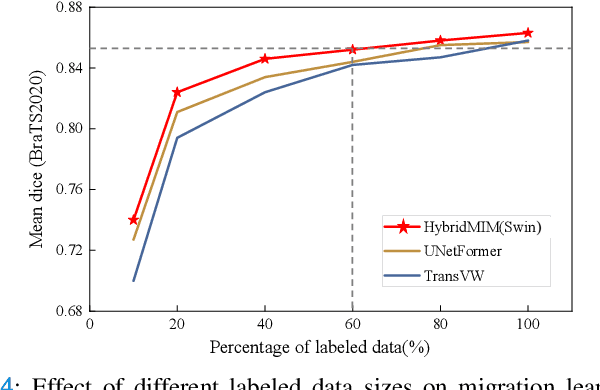
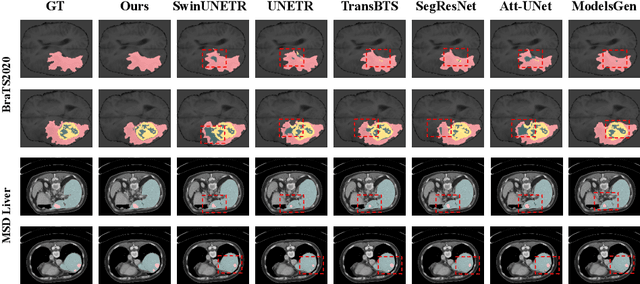
Masked image modeling (MIM) with transformer backbones has recently been exploited as a powerful self-supervised pre-training technique. The existing MIM methods adopt the strategy to mask random patches of the image and reconstruct the missing pixels, which only considers semantic information at a lower level, and causes a long pre-training time.This paper presents HybridMIM, a novel hybrid self-supervised learning method based on masked image modeling for 3D medical image segmentation.Specifically, we design a two-level masking hierarchy to specify which and how patches in sub-volumes are masked, effectively providing the constraints of higher level semantic information. Then we learn the semantic information of medical images at three levels, including:1) partial region prediction to reconstruct key contents of the 3D image, which largely reduces the pre-training time burden (pixel-level); 2) patch-masking perception to learn the spatial relationship between the patches in each sub-volume (region-level).and 3) drop-out-based contrastive learning between samples within a mini-batch, which further improves the generalization ability of the framework (sample-level). The proposed framework is versatile to support both CNN and transformer as encoder backbones, and also enables to pre-train decoders for image segmentation. We conduct comprehensive experiments on four widely-used public medical image segmentation datasets, including BraTS2020, BTCV, MSD Liver, and MSD Spleen. The experimental results show the clear superiority of HybridMIM against competing supervised methods, masked pre-training approaches, and other self-supervised methods, in terms of quantitative metrics, timing performance and qualitative observations. The codes of HybridMIM are available at https://github.com/ge-xing/HybridMIM
Diff-UNet: A Diffusion Embedded Network for Volumetric Segmentation
Mar 18, 2023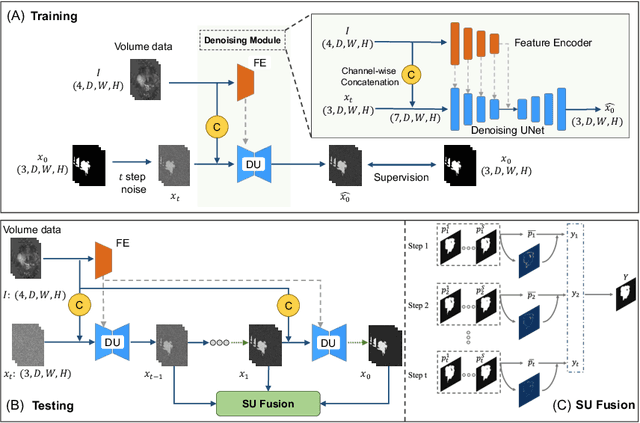

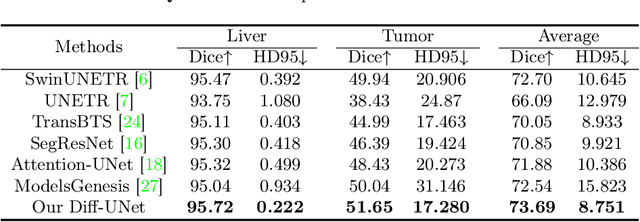
In recent years, Denoising Diffusion Models have demonstrated remarkable success in generating semantically valuable pixel-wise representations for image generative modeling. In this study, we propose a novel end-to-end framework, called Diff-UNet, for medical volumetric segmentation. Our approach integrates the diffusion model into a standard U-shaped architecture to extract semantic information from the input volume effectively, resulting in excellent pixel-level representations for medical volumetric segmentation. To enhance the robustness of the diffusion model's prediction results, we also introduce a Step-Uncertainty based Fusion (SUF) module during inference to combine the outputs of the diffusion models at each step. We evaluate our method on three datasets, including multimodal brain tumors in MRI, liver tumors, and multi-organ CT volumes, and demonstrate that Diff-UNet outperforms other state-of-the-art methods significantly. Our experimental results also indicate the universality and effectiveness of the proposed model. The proposed framework has the potential to facilitate the accurate diagnosis and treatment of medical conditions by enabling more precise segmentation of anatomical structures. The codes of Diff-UNet are available at https://github.com/ge-xing/Diff-UNet
Learning Physical-Spatio-Temporal Features for Video Shadow Removal
Mar 16, 2023

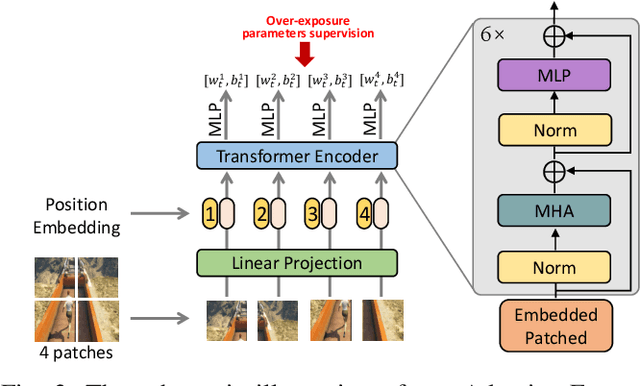
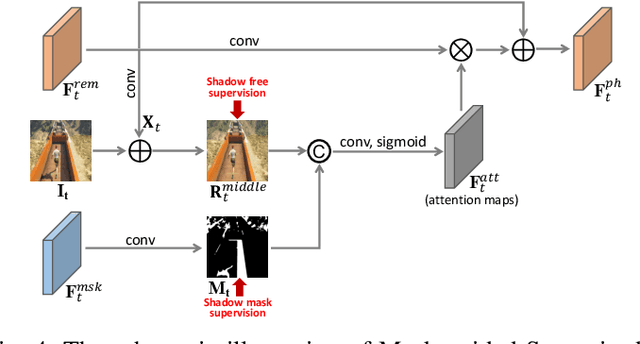
Shadow removal in a single image has received increasing attention in recent years. However, removing shadows over dynamic scenes remains largely under-explored. In this paper, we propose the first data-driven video shadow removal model, termed PSTNet, by exploiting three essential characteristics of video shadows, i.e., physical property, spatio relation, and temporal coherence. Specifically, a dedicated physical branch was established to conduct local illumination estimation, which is more applicable for scenes with complex lighting and textures, and then enhance the physical features via a mask-guided attention strategy. Then, we develop a progressive aggregation module to enhance the spatio and temporal characteristics of features maps, and effectively integrate the three kinds of features. Furthermore, to tackle the lack of datasets of paired shadow videos, we synthesize a dataset (SVSRD-85) with aid of the popular game GTAV by controlling the switch of the shadow renderer. Experiments against 9 state-of-the-art models, including image shadow removers and image/video restoration methods, show that our method improves the best SOTA in terms of RMSE error for the shadow area by 14.7. In addition, we develop a lightweight model adaptation strategy to make our synthetic-driven model effective in real world scenes. The visual comparison on the public SBU-TimeLapse dataset verifies the generalization ability of our model in real scenes.