 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLing Liang
An Inexact Halpern Iteration with Application to Distributionally Robust Optimization
Feb 12, 2024
The Halpern iteration for solving monotone inclusion problems has gained increasing interests in recent years due to its simple form and appealing convergence properties. In this paper, we investigate the inexact variants of the scheme in both deterministic and stochastic settings. We conduct extensive convergence analysis and show that by choosing the inexactness tolerances appropriately, the inexact schemes admit an $O(k^{-1})$ convergence rate in terms of the (expected) residue norm. Our results relax the state-of-the-art inexactness conditions employed in the literature while sharing the same competitive convergence properties. We then demonstrate how the proposed methods can be applied for solving two classes of data-driven Wasserstein distributionally robust optimization problems that admit convex-concave min-max optimization reformulations. We highlight its capability of performing inexact computations for distributionally robust learning with stochastic first-order methods.
On the Stochastic (Variance-Reduced) Proximal Gradient Method for Regularized Expected Reward Optimization
Jan 23, 2024We consider a regularized expected reward optimization problem in the non-oblivious setting that covers many existing problems in reinforcement learning (RL). In order to solve such an optimization problem, we apply and analyze the classical stochastic proximal gradient method. In particular, the method has shown to admit an $O(\epsilon^{-4})$ sample complexity to an $\epsilon$-stationary point, under standard conditions. Since the variance of the classical stochastic gradient estimator is typically large which slows down the convergence, we also apply an efficient stochastic variance-reduce proximal gradient method with an importance sampling based ProbAbilistic Gradient Estimator (PAGE). To the best of our knowledge, the application of this method represents a novel approach in addressing the general regularized reward optimization problem. Our analysis shows that the sample complexity can be improved from $O(\epsilon^{-4})$ to $O(\epsilon^{-3})$ under additional conditions. Our results on the stochastic (variance-reduced) proximal gradient method match the sample complexity of their most competitive counterparts under similar settings in the RL literature.
Escaping Spurious Local Minima of Low-Rank Matrix Factorization Through Convex Lifting
Apr 29, 2022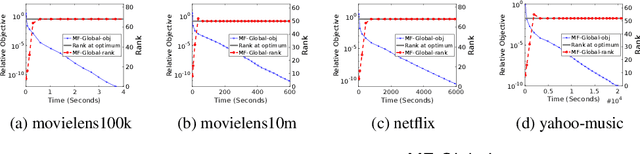
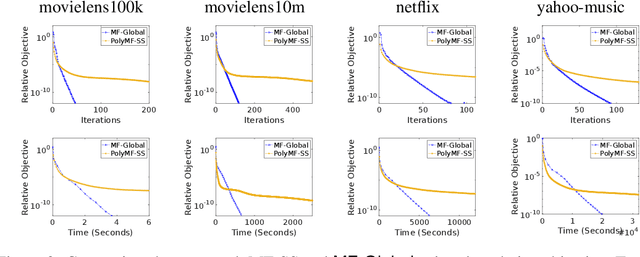
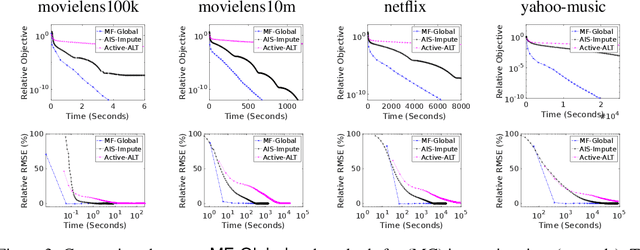
This work proposes a rapid global solver for nonconvex low-rank matrix factorization (MF) problems that we name MF-Global. Through convex lifting steps, our method efficiently escapes saddle points and spurious local minima ubiquitous in noisy real-world data, and is guaranteed to always converge to the global optima. Moreover, the proposed approach adaptively adjusts the rank for the factorization and provably identifies the optimal rank for MF automatically in the course of optimization through tools of manifold identification, and thus it also spends significantly less time on parameter tuning than existing MF methods, which require an exhaustive search for this optimal rank. On the other hand, when compared to methods for solving the lifted convex form only, MF-Global leads to significantly faster convergence and much shorter running time. Experiments on real-world large-scale recommendation system problems confirm that MF-Global can indeed effectively escapes spurious local solutions at which existing MF approaches stuck, and is magnitudes faster than state-of-the-art algorithms for the lifted convex form.
ScaleCert: Scalable Certified Defense against Adversarial Patches with Sparse Superficial Layers
Nov 04, 2021
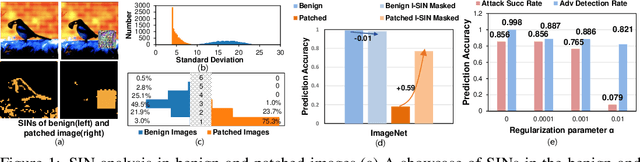
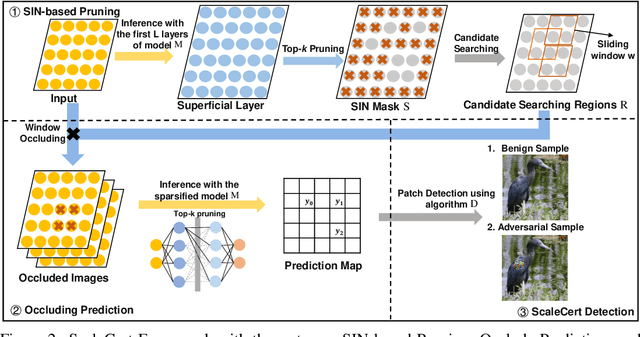
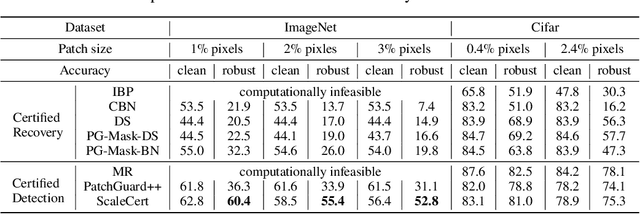
Adversarial patch attacks that craft the pixels in a confined region of the input images show their powerful attack effectiveness in physical environments even with noises or deformations. Existing certified defenses towards adversarial patch attacks work well on small images like MNIST and CIFAR-10 datasets, but achieve very poor certified accuracy on higher-resolution images like ImageNet. It is urgent to design both robust and effective defenses against such a practical and harmful attack in industry-level larger images. In this work, we propose the certified defense methodology that achieves high provable robustness for high-resolution images and largely improves the practicality for real adoption of the certified defense. The basic insight of our work is that the adversarial patch intends to leverage localized superficial important neurons (SIN) to manipulate the prediction results. Hence, we leverage the SIN-based DNN compression techniques to significantly improve the certified accuracy, by reducing the adversarial region searching overhead and filtering the prediction noises. Our experimental results show that the certified accuracy is increased from 36.3% (the state-of-the-art certified detection) to 60.4% on the ImageNet dataset, largely pushing the certified defenses for practical use.
H2Learn: High-Efficiency Learning Accelerator for High-Accuracy Spiking Neural Networks
Jul 25, 2021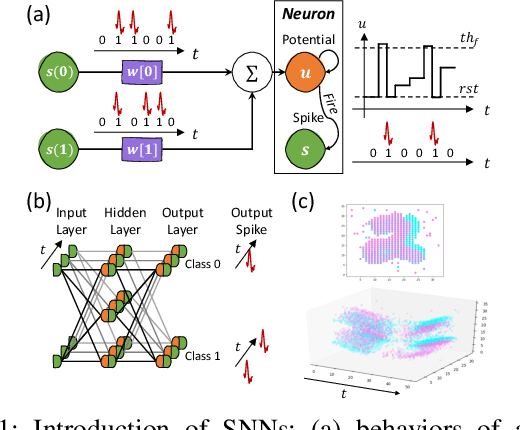
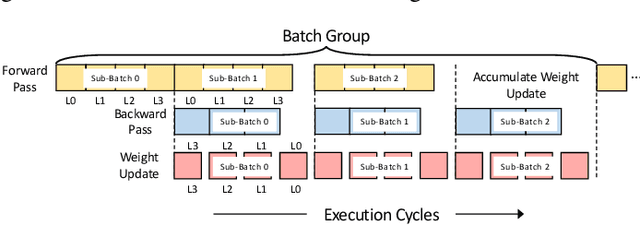
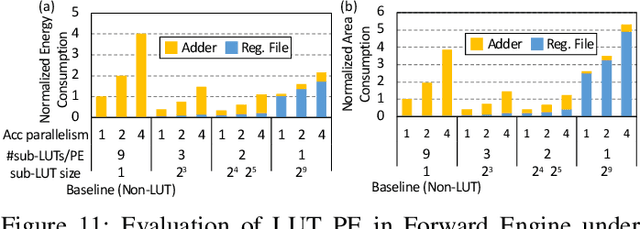
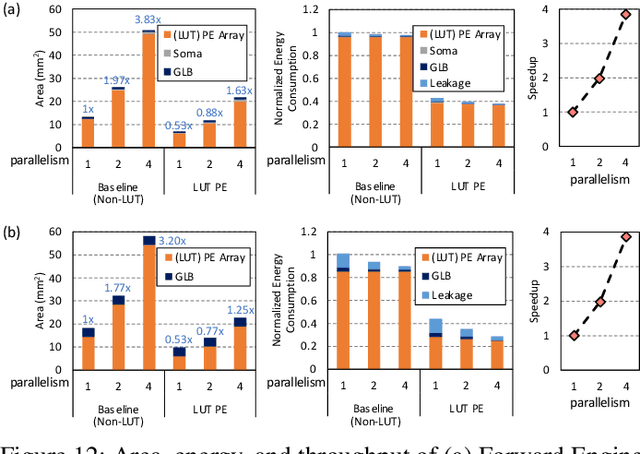
Although spiking neural networks (SNNs) take benefits from the bio-plausible neural modeling, the low accuracy under the common local synaptic plasticity learning rules limits their application in many practical tasks. Recently, an emerging SNN supervised learning algorithm inspired by backpropagation through time (BPTT) from the domain of artificial neural networks (ANNs) has successfully boosted the accuracy of SNNs and helped improve the practicability of SNNs. However, current general-purpose processors suffer from low efficiency when performing BPTT for SNNs due to the ANN-tailored optimization. On the other hand, current neuromorphic chips cannot support BPTT because they mainly adopt local synaptic plasticity rules for simplified implementation. In this work, we propose H2Learn, a novel architecture that can achieve high efficiency for BPTT-based SNN learning which ensures high accuracy of SNNs. At the beginning, we characterized the behaviors of BPTT-based SNN learning. Benefited from the binary spike-based computation in the forward pass and the weight update, we first design lookup table (LUT) based processing elements in Forward Engine and Weight Update Engine to make accumulations implicit and to fuse the computations of multiple input points. Second, benefited from the rich sparsity in the backward pass, we design a dual-sparsity-aware Backward Engine which exploits both input and output sparsity. Finally, we apply a pipeline optimization between different engines to build an end-to-end solution for the BPTT-based SNN learning. Compared with the modern NVIDIA V100 GPU, H2Learn achieves 7.38x area saving, 5.74-10.20x speedup, and 5.25-7.12x energy saving on several benchmark datasets.
STRIDE along Spectrahedral Vertices for Solving Large-Scale Rank-One Semidefinite Relaxations
May 28, 2021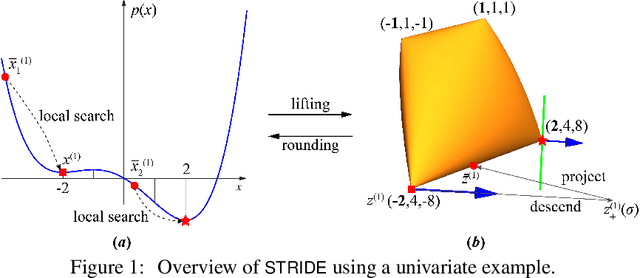
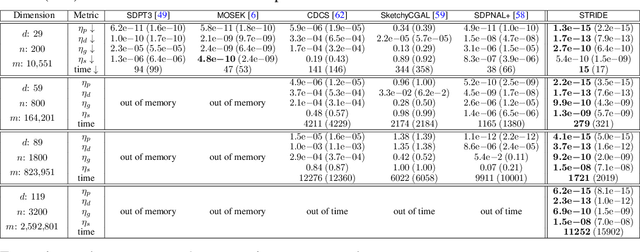
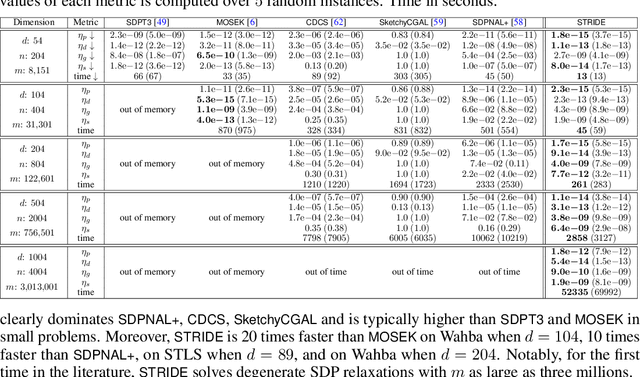
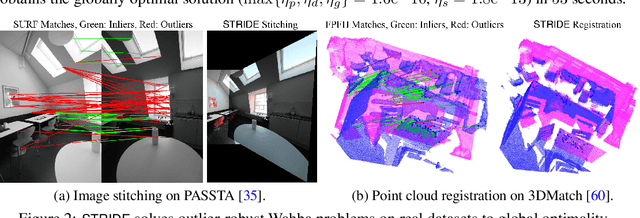
We consider solving high-order semidefinite programming (SDP) relaxations of nonconvex polynomial optimization problems (POPs) that admit rank-one optimal solutions. Existing approaches, which solve the SDP independently from the POP, either cannot scale to large problems or suffer from slow convergence due to the typical degeneracy of such SDPs. We propose a new algorithmic framework, called SpecTrahedral pRoximal gradIent Descent along vErtices (STRIDE), that blends fast local search on the nonconvex POP with global descent on the convex SDP. Specifically, STRIDE follows a globally convergent trajectory driven by a proximal gradient method (PGM) for solving the SDP, while simultaneously probing long, but safeguarded, rank-one "strides", generated by fast nonlinear programming algorithms on the POP, to seek rapid descent. We prove STRIDE has global convergence. To solve the subproblem of projecting a given point onto the feasible set of the SDP, we reformulate the projection step as a continuously differentiable unconstrained optimization and apply a limited-memory BFGS method to achieve both scalability and accuracy. We conduct numerical experiments on solving second-order SDP relaxations arising from two important applications in machine learning and computer vision. STRIDE dominates a diverse set of five existing SDP solvers and is the only solver that can solve degenerate rank-one SDPs to high accuracy (e.g., KKT residuals below 1e-9), even in the presence of millions of equality constraints.
Exploring Adversarial Attack in Spiking Neural Networks with Spike-Compatible Gradient
Jan 01, 2020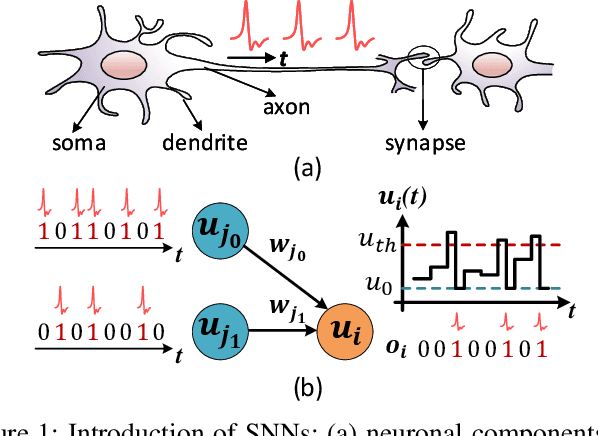
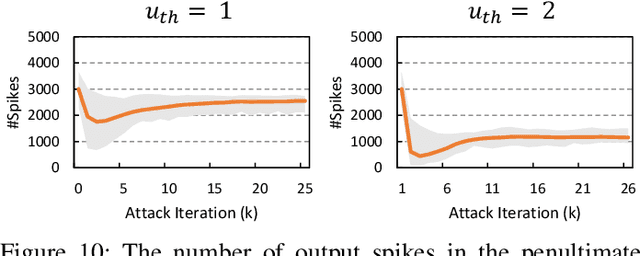
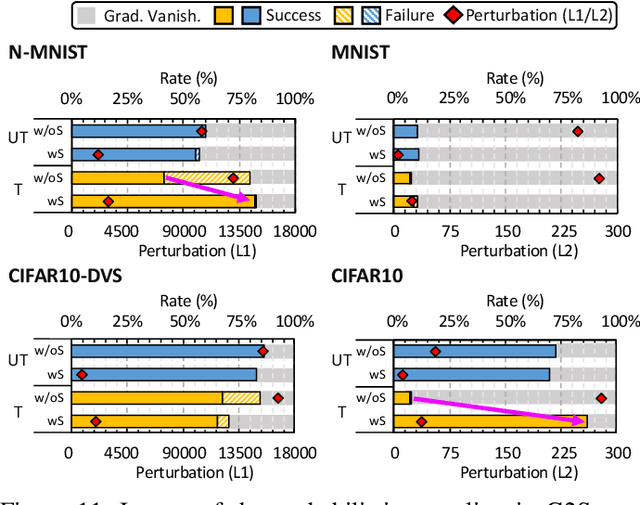
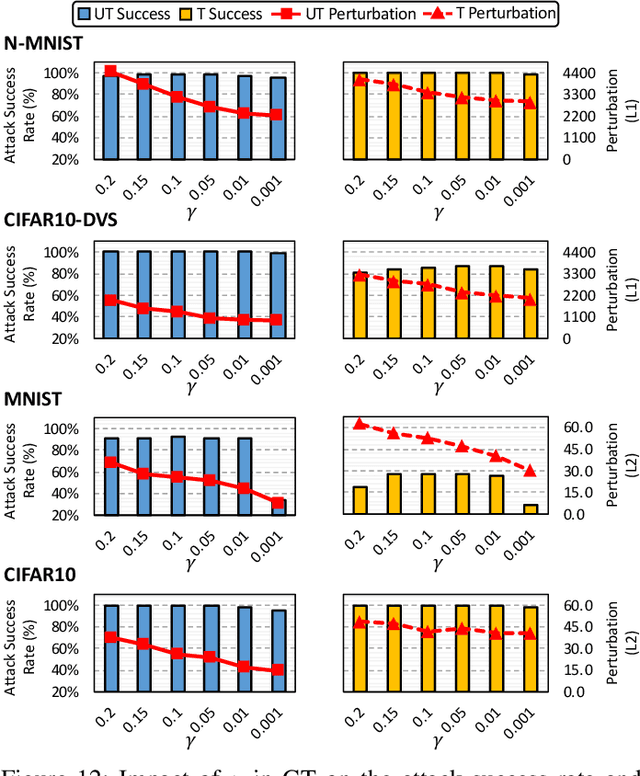
Recently, backpropagation through time inspired learning algorithms are widely introduced into SNNs to improve the performance, which brings the possibility to attack the models accurately given Spatio-temporal gradient maps. We propose two approaches to address the challenges of gradient input incompatibility and gradient vanishing. Specifically, we design a gradient to spike converter to convert continuous gradients to ternary ones compatible with spike inputs. Then, we design a gradient trigger to construct ternary gradients that can randomly flip the spike inputs with a controllable turnover rate, when meeting all zero gradients. Putting these methods together, we build an adversarial attack methodology for SNNs trained by supervised algorithms. Moreover, we analyze the influence of the training loss function and the firing threshold of the penultimate layer, which indicates a "trap" region under the cross-entropy loss that can be escaped by threshold tuning. Extensive experiments are conducted to validate the effectiveness of our solution. Besides the quantitative analysis of the influence factors, we evidence that SNNs are more robust against adversarial attack than ANNs. This work can help reveal what happens in SNN attack and might stimulate more research on the security of SNN models and neuromorphic devices.
Comprehensive SNN Compression Using ADMM Optimization and Activity Regularization
Nov 03, 2019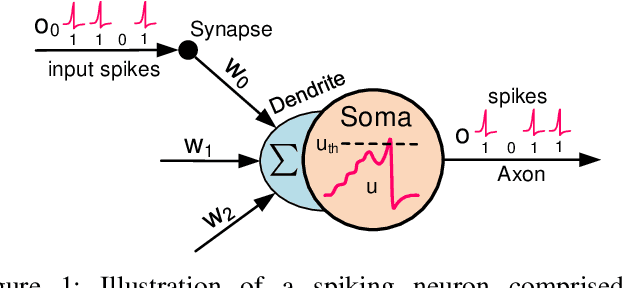
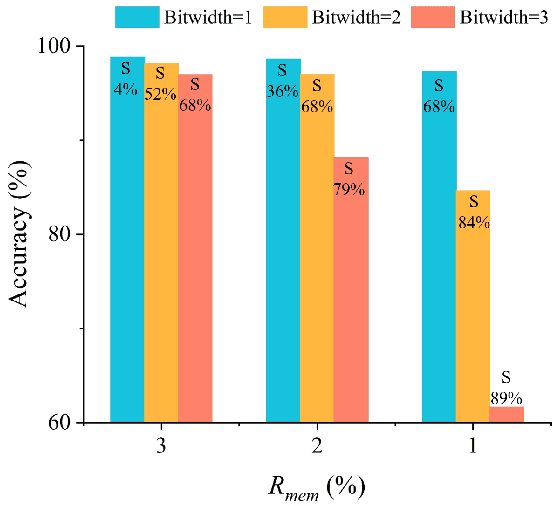
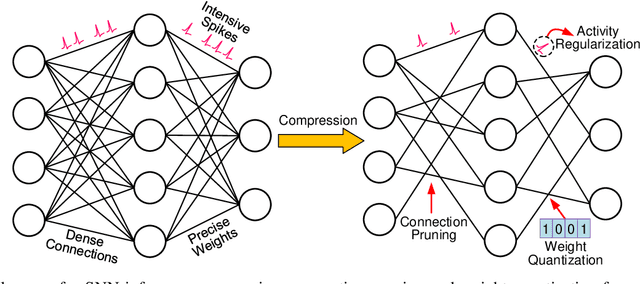
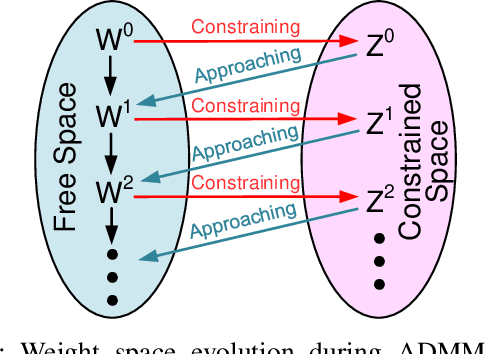
Spiking neural network is an important family of models to emulate the brain, which has been widely adopted by neuromorphic platforms. In the meantime, it is well-known that the huge memory and compute costs of neural networks greatly hinder the execution with high efficiency, especially on edge devices. To this end, model compression is proposed as a promising technique to improve the running efficiency via parameter and operation reduction. Therefore, it is interesting to investigate how much an SNN model can be compressed without compromising much functionality. However, this is quite challenging because SNNs usually behave distinctly from deep learning models. Specifically, i) the accuracy of spike-coded SNNs is usually sensitive to any network change; ii) the computation of SNNs is event-driven rather than static. Here we present a comprehensive SNN compression through three steps. First, we formulate the connection pruning and the weight quantization as a supervised learning-based constrained optimization problem. Second, we combine the emerging spatio-temporal backpropagation and the powerful alternating direction method of multipliers to solve the problem with minimum accuracy loss. Third, we further propose an activity regularization to reduce the spike events for fewer active operations. We define several quantitative metrics to evaluation the compression performance for SNNs and validate our methodology in pattern recognition tasks over MNIST, N-MNIST, and CIFAR10 datasets. Extensive comparisons between different compression strategies, the corresponding result analysis, and some interesting insights are provided. To our best knowledge, this is the first work that studies SNN compression in a comprehensive manner by exploiting all possible compression ways and achieves better results. Our work offers a promising solution to pursue ultra-efficient neuromorphic systems.
Multi-View Fuzzy Clustering with The Alternative Learning between Shared Hidden Space and Partition
Aug 12, 2019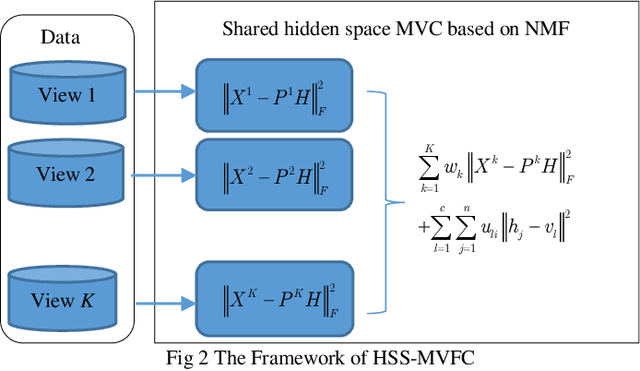
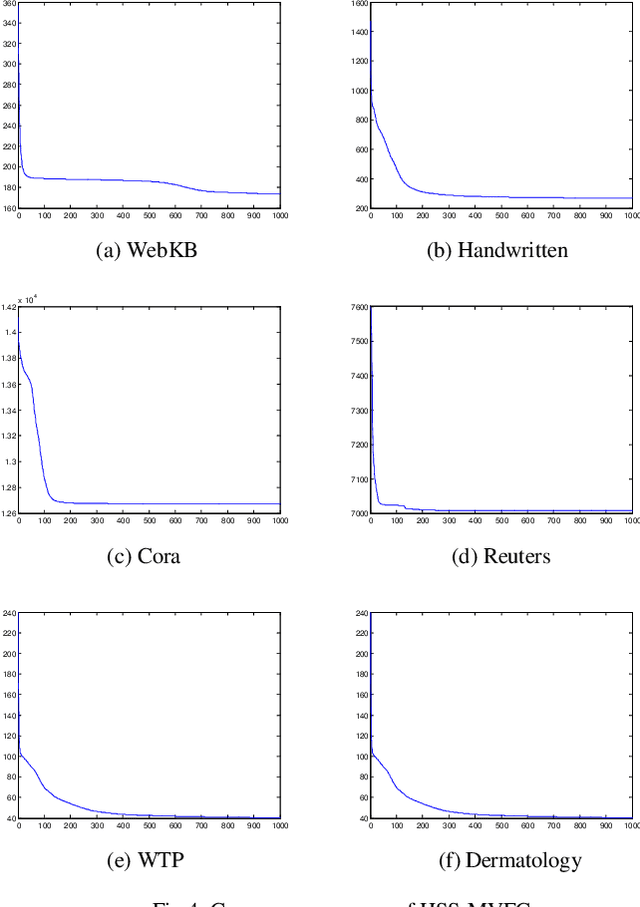

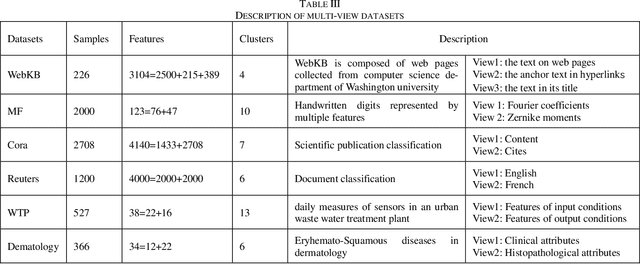
As the multi-view data grows in the real world, multi-view clus-tering has become a prominent technique in data mining, pattern recognition, and machine learning. How to exploit the relation-ship between different views effectively using the characteristic of multi-view data has become a crucial challenge. Aiming at this, a hidden space sharing multi-view fuzzy clustering (HSS-MVFC) method is proposed in the present study. This method is based on the classical fuzzy c-means clustering model, and obtains associ-ated information between different views by introducing shared hidden space. Especially, the shared hidden space and the fuzzy partition can be learned alternatively and contribute to each other. Meanwhile, the proposed method uses maximum entropy strategy to control the weights of different views while learning the shared hidden space. The experimental result shows that the proposed multi-view clustering method has better performance than many related clustering methods.
Crossbar-aware neural network pruning
Jul 25, 2018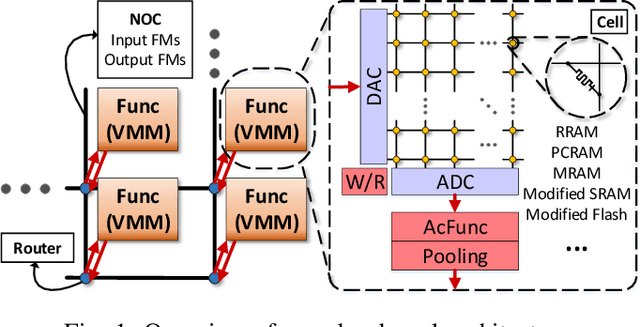
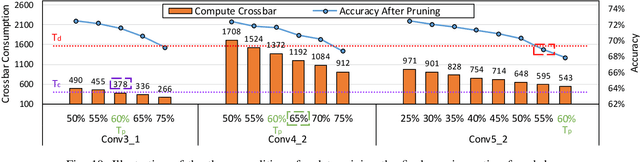

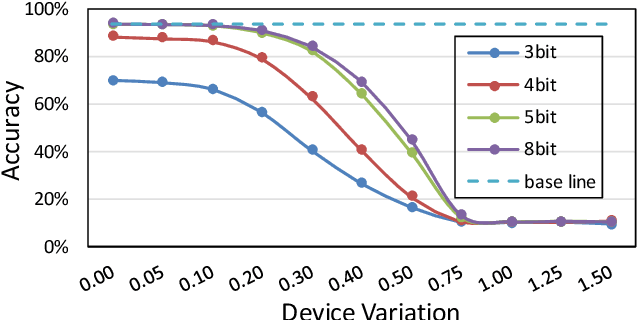
Crossbar architecture based devices have been widely adopted in neural network accelerators by taking advantage of the high efficiency on vector-matrix multiplication (VMM) operations. However, in the case of convolutional neural networks (CNNs), the efficiency is compromised dramatically due to the large amounts of data reuse. Although some mapping methods have been designed to achieve a balance between the execution throughput and resource overhead, the resource consumption cost is still huge while maintaining the throughput. Network pruning is a promising and widely studied leverage to shrink the model size. Whereas, previous work didn`t consider the crossbar architecture and the corresponding mapping method, which cannot be directly utilized by crossbar-based neural network accelerators. Tightly combining the crossbar structure and its mapping, this paper proposes a crossbar-aware pruning framework based on a formulated L0-norm constrained optimization problem. Specifically, we design an L0-norm constrained gradient descent (LGD) with relaxant probabilistic projection (RPP) to solve this problem. Two grains of sparsity are successfully achieved: i) intuitive crossbar-grain sparsity and ii) column-grain sparsity with output recombination, based on which we further propose an input feature maps (FMs) reorder method to improve the model accuracy. We evaluate our crossbar-aware pruning framework on median-scale CIFAR10 dataset and large-scale ImageNet dataset with VGG and ResNet models. Our method is able to reduce the crossbar overhead by 44%-72% with little accuracy degradation. This work greatly saves the resource and the related energy cost, which provides a new co-design solution for mapping CNNs onto various crossbar devices with significantly higher efficiency.