 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingxiao Ma
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Feb 27, 2024
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
BitNet: Scaling 1-bit Transformers for Large Language Models
Oct 17, 2023The increasing size of large language models has posed challenges for deployment and raised concerns about environmental impact due to high energy consumption. In this work, we introduce BitNet, a scalable and stable 1-bit Transformer architecture designed for large language models. Specifically, we introduce BitLinear as a drop-in replacement of the nn.Linear layer in order to train 1-bit weights from scratch. Experimental results on language modeling show that BitNet achieves competitive performance while substantially reducing memory footprint and energy consumption, compared to state-of-the-art 8-bit quantization methods and FP16 Transformer baselines. Furthermore, BitNet exhibits a scaling law akin to full-precision Transformers, suggesting its potential for effective scaling to even larger language models while maintaining efficiency and performance benefits.
FlexMoE: Scaling Large-scale Sparse Pre-trained Model Training via Dynamic Device Placement
Apr 08, 2023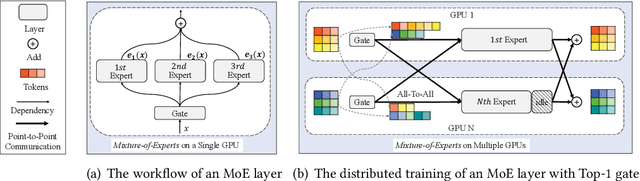
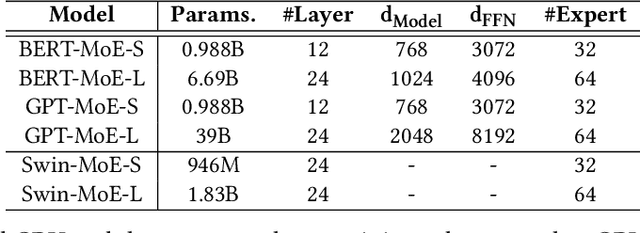
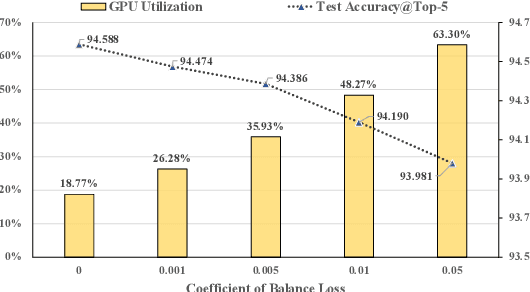
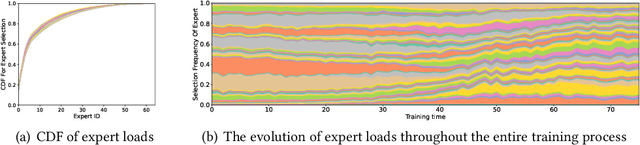
With the increasing data volume, there is a trend of using large-scale pre-trained models to store the knowledge into an enormous number of model parameters. The training of these models is composed of lots of dense algebras, requiring a huge amount of hardware resources. Recently, sparsely-gated Mixture-of-Experts (MoEs) are becoming more popular and have demonstrated impressive pretraining scalability in various downstream tasks. However, such a sparse conditional computation may not be effective as expected in practical systems due to the routing imbalance and fluctuation problems. Generally, MoEs are becoming a new data analytics paradigm in the data life cycle and suffering from unique challenges at scales, complexities, and granularities never before possible. In this paper, we propose a novel DNN training framework, FlexMoE, which systematically and transparently address the inefficiency caused by dynamic dataflow. We first present an empirical analysis on the problems and opportunities of training MoE models, which motivates us to overcome the routing imbalance and fluctuation problems by a dynamic expert management and device placement mechanism. Then we introduce a novel scheduling module over the existing DNN runtime to monitor the data flow, make the scheduling plans, and dynamically adjust the model-to-hardware mapping guided by the real-time data traffic. A simple but efficient heuristic algorithm is exploited to dynamically optimize the device placement during training. We have conducted experiments on both NLP models (e.g., BERT and GPT) and vision models (e.g., Swin). And results show FlexMoE can achieve superior performance compared with existing systems on real-world workloads -- FlexMoE outperforms DeepSpeed by 1.70x on average and up to 2.10x, and outperforms FasterMoE by 1.30x on average and up to 1.45x.
* Accepted by SIGMOD 2023
SparDA: Accelerating Dynamic Sparse Deep Neural Networks via Sparse-Dense Transformation
Jan 26, 2023

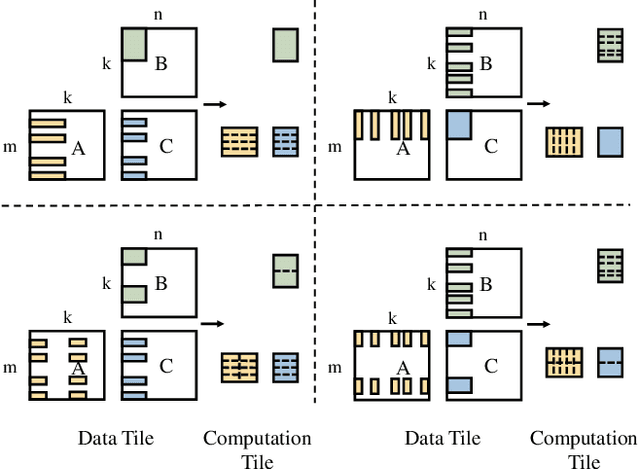

Due to its high cost-effectiveness, sparsity has become the most important approach for building efficient deep-learning models. However, commodity accelerators are built mainly for efficient dense computation, creating a huge gap for general sparse computation to leverage. Existing solutions have to use time-consuming compiling to improve the efficiency of sparse kernels in an ahead-of-time manner and thus are limited to static sparsity. A wide range of dynamic sparsity opportunities is missed because their sparsity patterns are only known at runtime. This limits the future of building more biological brain-like neural networks that should be dynamically and sparsely activated. In this paper, we bridge the gap between sparse computation and commodity accelerators by proposing a system, called Spider, for efficiently executing deep learning models with dynamic sparsity. We identify an important property called permutation invariant that applies to most deep-learning computations. The property enables Spider (1) to extract dynamic sparsity patterns of tensors that are only known at runtime with little overhead; and (2) to transform the dynamic sparse computation into an equivalent dense computation which has been extremely optimized on commodity accelerators. Extensive evaluation on diverse models shows Spider can extract and transform dynamic sparsity with negligible overhead but brings up to 9.4x speedup over state-of-art solutions.
Dense-to-Sparse Gate for Mixture-of-Experts
Dec 29, 2021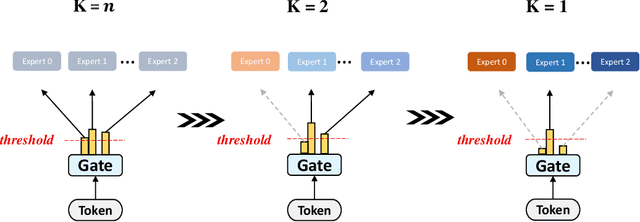

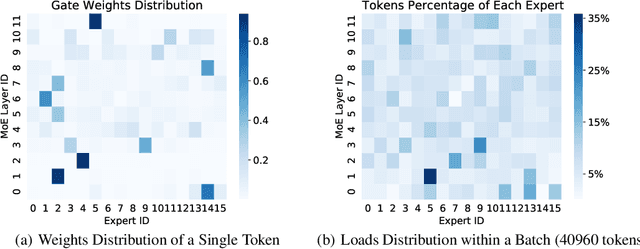
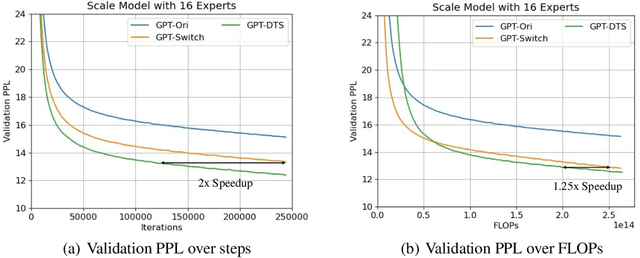
Mixture-of-experts (MoE) is becoming popular due to its success in improving the model quality, especially in Transformers. By routing tokens with a sparse gate to a few experts that each only contains part of the full model, MoE keeps the model size unchanged and significantly reduces per-token computation, which effectively scales neural networks. However, we found that the current approach of jointly training experts and the sparse gate introduces a negative impact on model accuracy, diminishing the efficiency of expensive large-scale model training. In this work, we proposed Dense-To-Sparse gate (DTS-Gate) for MoE training. Specifically, instead of using a permanent sparse gate, DTS-Gate begins as a dense gate that routes tokens to all experts, then gradually and adaptively becomes sparser while routes to fewer experts. MoE with DTS-Gate naturally decouples the training of experts and the sparse gate by training all experts at first and then learning the sparse gate. Experiments show that compared with the state-of-the-art Switch-Gate in GPT-MoE(1.5B) model with OpenWebText dataset(40GB), DTS-Gate can obtain 2.0x speed-up to reach the same validation perplexity, as well as higher FLOPs-efficiency of a 1.42x speed-up.
Architectural Implications of Graph Neural Networks
Sep 02, 2020
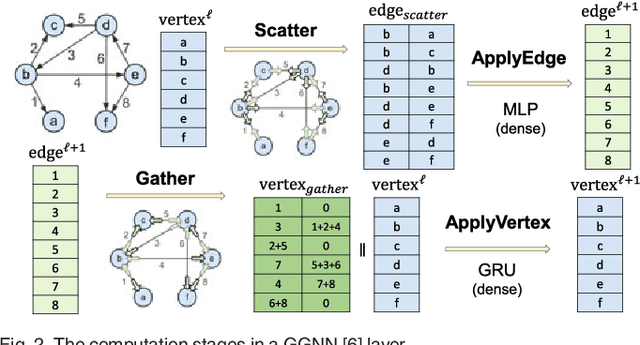
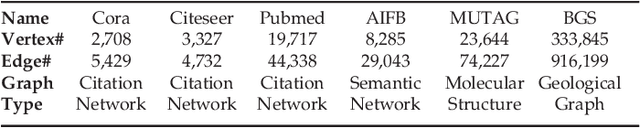
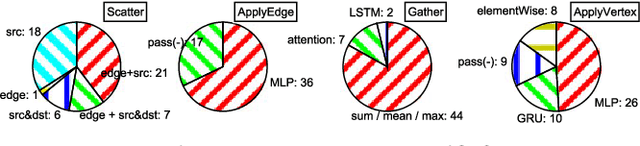
Graph neural networks (GNN) represent an emerging line of deep learning models that operate on graph structures. It is becoming more and more popular due to its high accuracy achieved in many graph-related tasks. However, GNN is not as well understood in the system and architecture community as its counterparts such as multi-layer perceptrons and convolutional neural networks. This work tries to introduce the GNN to our community. In contrast to prior work that only presents characterizations of GCNs, our work covers a large portion of the varieties for GNN workloads based on a general GNN description framework. By constructing the models on top of two widely-used libraries, we characterize the GNN computation at inference stage concerning general-purpose and application-specific architectures and hope our work can foster more system and architecture research for GNNs.
* 4 pages, published in IEEE Computer Architecture Letters (CAL) 2020
Towards Efficient Large-Scale Graph Neural Network Computing
Oct 19, 2018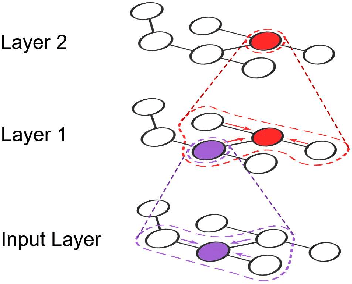


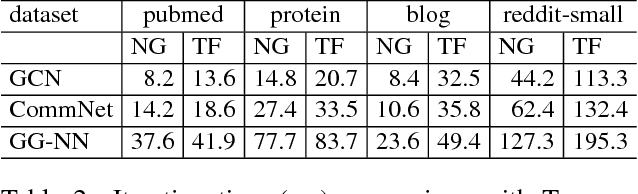
Recent deep learning models have moved beyond low-dimensional regular grids such as image, video, and speech, to high-dimensional graph-structured data, such as social networks, brain connections, and knowledge graphs. This evolution has led to large graph-based irregular and sparse models that go beyond what existing deep learning frameworks are designed for. Further, these models are not easily amenable to efficient, at scale, acceleration on parallel hardwares (e.g. GPUs). We introduce NGra, the first parallel processing framework for graph-based deep neural networks (GNNs). NGra presents a new SAGA-NN model for expressing deep neural networks as vertex programs with each layer in well-defined (Scatter, ApplyEdge, Gather, ApplyVertex) graph operation stages. This model not only allows GNNs to be expressed intuitively, but also facilitates the mapping to an efficient dataflow representation. NGra addresses the scalability challenge transparently through automatic graph partitioning and chunk-based stream processing out of GPU core or over multiple GPUs, which carefully considers data locality, data movement, and overlapping of parallel processing and data movement. NGra further achieves efficiency through highly optimized Scatter/Gather operators on GPUs despite its sparsity. Our evaluation shows that NGra scales to large real graphs that none of the existing frameworks can handle directly, while achieving up to about 4 times speedup even at small scales over the multiple-baseline design on TensorFlow.