 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiuqing Yang
Superposed IM-OFDM (S-IM-OFDM): An Enhanced OFDM for Integrated Sensing and Communications
Mar 20, 2024
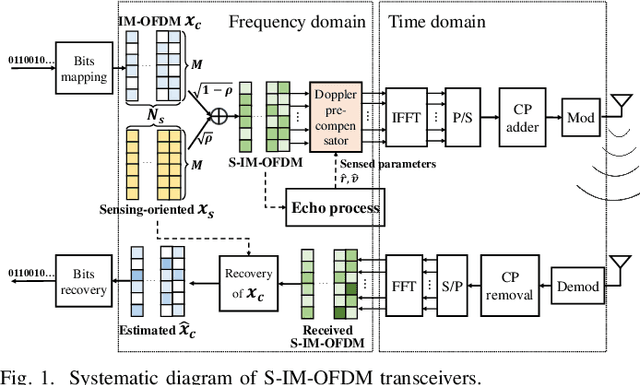
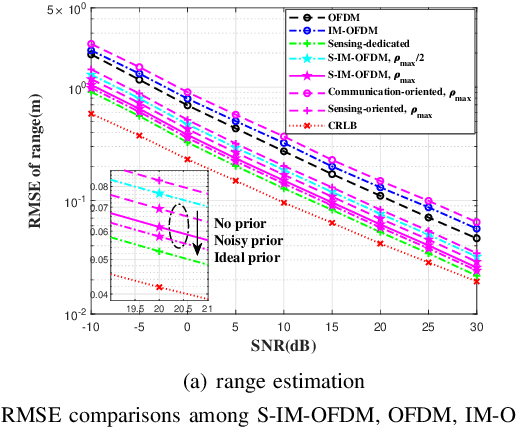
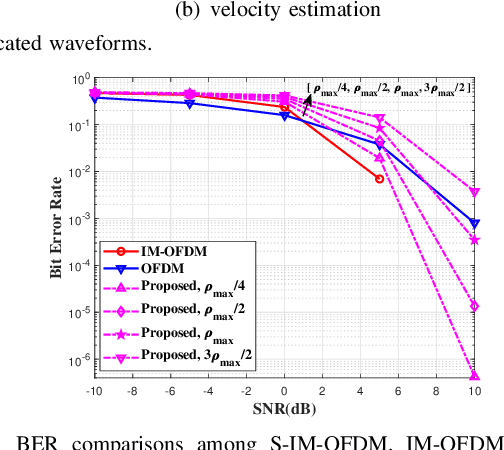
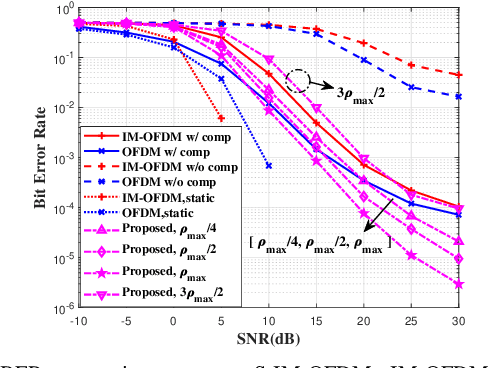
Integrated sensing and communications (ISAC) is a critical enabler for emerging 6G applications, and at its core lies in the dual-functional waveform design. While orthogonal frequency division multiplexing (OFDM) has been a popular basic waveform, its primitive version falls short in sensing due to the inherent unregulated auto-correlation properties. Furthermore, the sensitivity to Doppler shift hinders its broader applications in dynamic scenarios. To address these issues, we propose a superposed index-modulated OFDM (S-IM-OFDM). The proposed scheme improves the sensing performance without excess power consumption by translating the energy efficiency of IM-OFDM onto sensing-oriented signals over OFDM. Also, it maintains excellent communication performance in time-varying channels by leveraging the sensed parameters to compensate for Doppler. Compared to conventional OFDM, the proposed S-IM-OFDM waveform exhibits better sensing capabilities and wider applicability in dynamic scenarios. Both theoretical analyses and simulations corroborate its dual benefits.
A Survey on Federated Learning in Intelligent Transportation Systems
Mar 14, 2024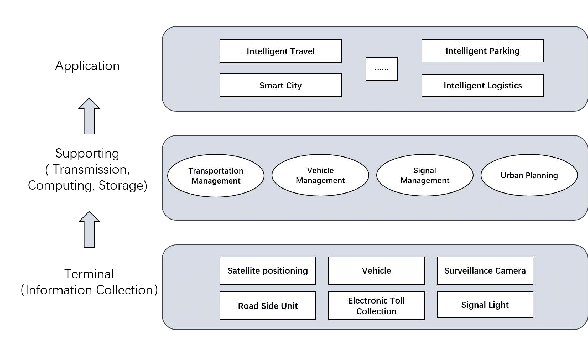
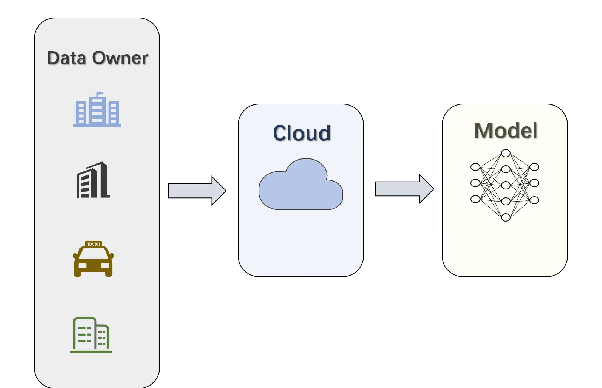
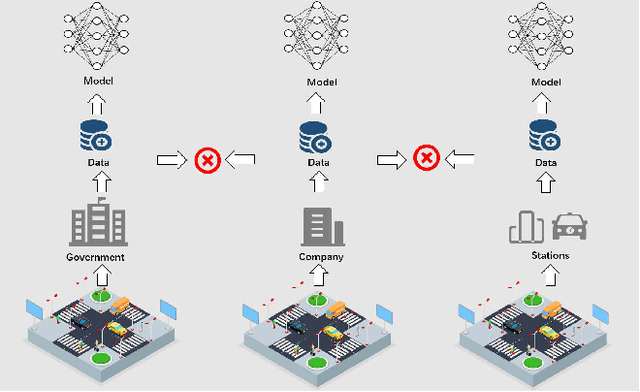
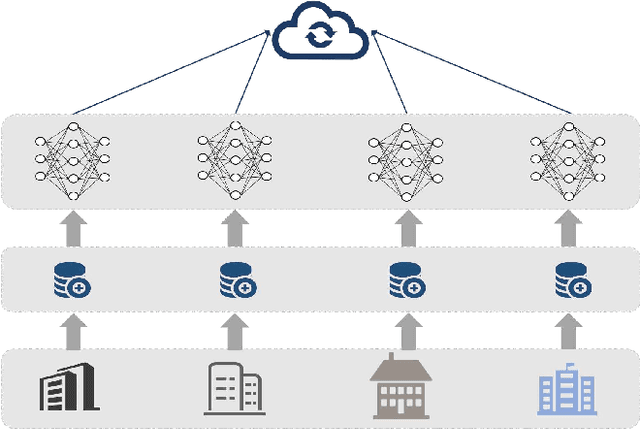
The development of Intelligent Transportation System (ITS) has brought about comprehensive urban traffic information that not only provides convenience to urban residents in their daily lives but also enhances the efficiency of urban road usage, leading to a more harmonious and sustainable urban life. Typical scenarios in ITS mainly include traffic flow prediction, traffic target recognition, and vehicular edge computing. However, most current ITS applications rely on a centralized training approach where users upload source data to a cloud server with high computing power for management and centralized training. This approach has limitations such as poor real-time performance, data silos, and difficulty in guaranteeing data privacy. To address these limitations, federated learning (FL) has been proposed as a promising solution. In this paper, we present a comprehensive review of the application of FL in ITS, with a particular focus on three key scenarios: traffic flow prediction, traffic target recognition, and vehicular edge computing. For each scenario, we provide an in-depth analysis of its key characteristics, current challenges, and specific manners in which FL is leveraged. Moreover, we discuss the benefits that FL can offer as a potential solution to the limitations of the centralized training approach currently used in ITS applications.
Integrated Sensing and Communications towards Proactive Beamforming in mmWave V2I via Multi-Modal Feature Fusion (MMFF)
Oct 04, 2023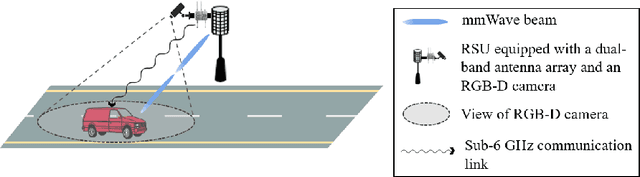
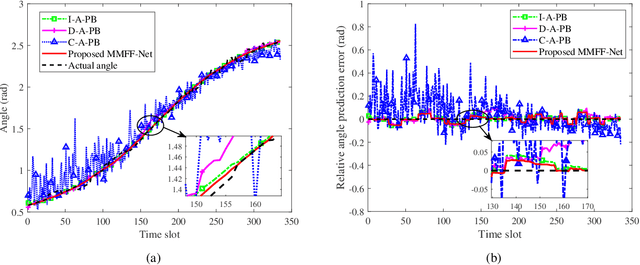
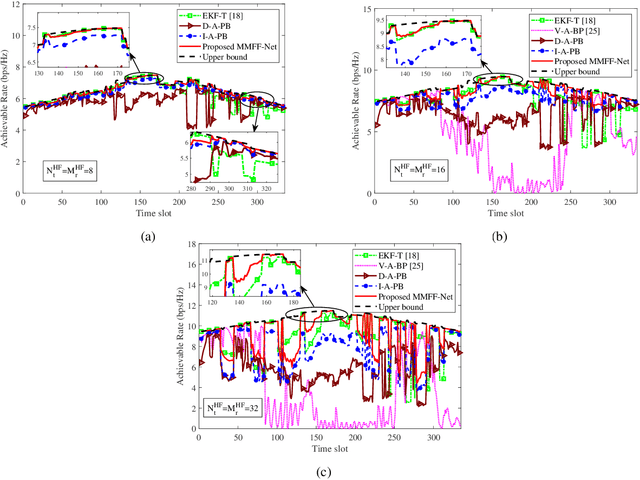
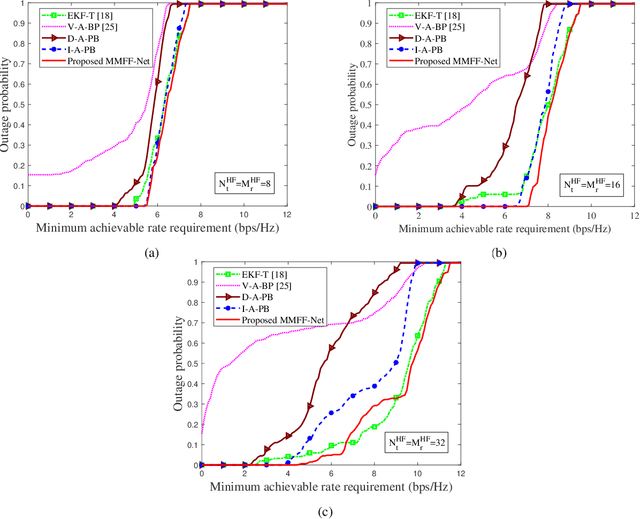
The future of vehicular communication networks relies on mmWave massive multi-input-multi-output antenna arrays for intensive data transfer and massive vehicle access. However, reliable vehicle-to-infrastructure links require narrow beam alignment, which traditionally involves excessive signaling overhead. To address this issue, we propose a novel proactive beamforming scheme that integrates multi-modal sensing and communications via Multi-Modal Feature Fusion Network (MMFF-Net), which is composed of multiple neural network components with distinct functions. Unlike existing methods that rely solely on communication processing, our approach obtains comprehensive environmental features to improve beam alignment accuracy. We verify our scheme on the ViWi dataset, which we enriched with realistic vehicle drifting behavior. Our proposed MMFF-Net achieves more accurate and stable angle prediction, which in turn increases the achievable rates and reduces the communication system outage probability. Even in complex dynamic scenarios, robust prediction results can be guaranteed, demonstrating the feasibility and practicality of the proposed proactive beamforming approach.
Fast Approximation of the Shapley Values Based on Order-of-Addition Experimental Designs
Sep 16, 2023
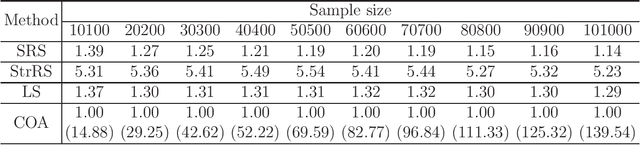
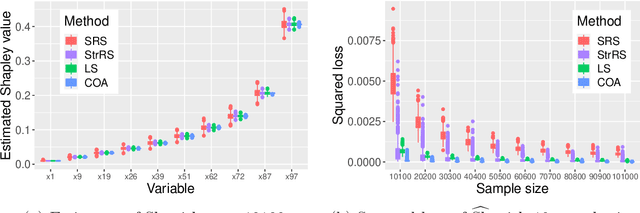
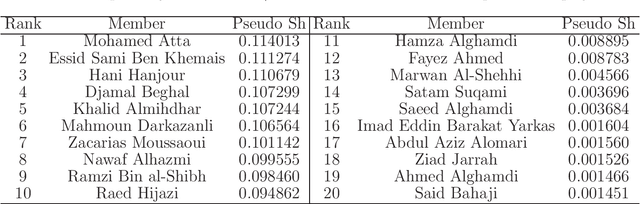
Shapley value is originally a concept in econometrics to fairly distribute both gains and costs to players in a coalition game. In the recent decades, its application has been extended to other areas such as marketing, engineering and machine learning. For example, it produces reasonable solutions for problems in sensitivity analysis, local model explanation towards the interpretable machine learning, node importance in social network, attribution models, etc. However, its heavy computational burden has been long recognized but rarely investigated. Specifically, in a $d$-player coalition game, calculating a Shapley value requires the evaluation of $d!$ or $2^d$ marginal contribution values, depending on whether we are taking the permutation or combination formulation of the Shapley value. Hence it becomes infeasible to calculate the Shapley value when $d$ is reasonably large. A common remedy is to take a random sample of the permutations to surrogate for the complete list of permutations. We find an advanced sampling scheme can be designed to yield much more accurate estimation of the Shapley value than the simple random sampling (SRS). Our sampling scheme is based on combinatorial structures in the field of design of experiments (DOE), particularly the order-of-addition experimental designs for the study of how the orderings of components would affect the output. We show that the obtained estimates are unbiased, and can sometimes deterministically recover the original Shapley value. Both theoretical and simulations results show that our DOE-based sampling scheme outperforms SRS in terms of estimation accuracy. Surprisingly, it is also slightly faster than SRS. Lastly, real data analysis is conducted for the C. elegans nervous system and the 9/11 terrorist network.
Intelligent Multi-Modal Sensing-Communication Integration: Synesthesia of Machines
Jun 25, 2023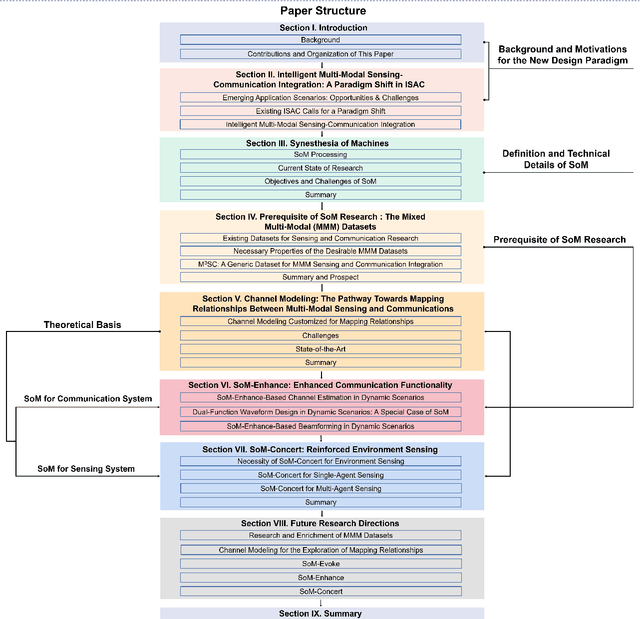
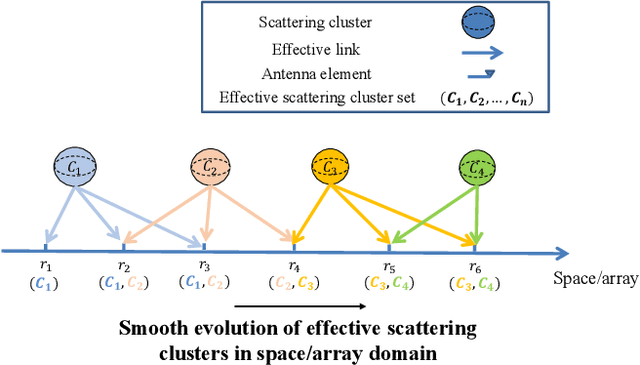
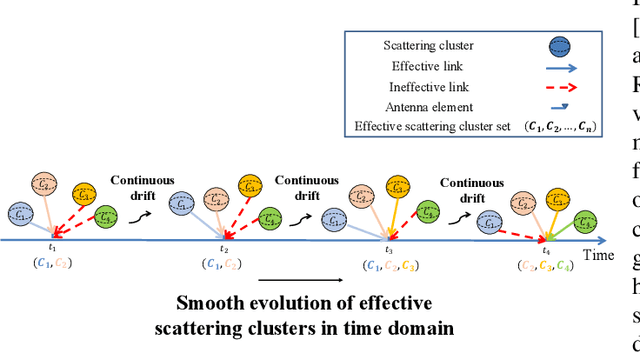
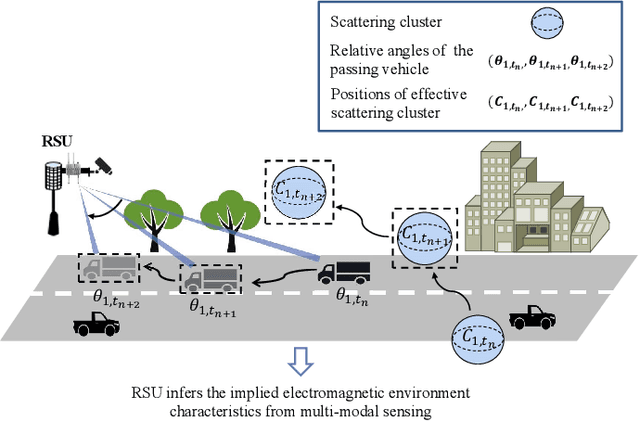
In the era of sixth-generation (6G) wireless communications, integrated sensing and communications (ISAC) is recognized as a promising solution to upgrading the physical system by endowing wireless communications with sensing capability. Existing ISAC is mainly oriented to static scenarios with radio-frequency sensors being the primary participants, thus lacking a comprehensive environment feature characterization and facing a severe performance bottleneck in dynamic environments. In light of this, we generalize the concept of ISAC by mimicking human synesthesia to support intelligent multi-modal sensing-communication integration. The so-termed Synesthesia of Machines (SoM) is not only oriented to generic scenarios, but also particularly suitable for solving challenges arising from dynamic scenarios. We commence by justifying the necessity and potentials of SoM. Subsequently, we offer the definition of SoM and zoom into the specific operating modes, followed by discussions of the state-of-the-art, corresponding objectives, and challenges. To facilitate SoM research, we overview the prerequisite of SoM research, that is, mixed multi-modal (MMM) datasets, and introduce our work. Built upon the MMM datasets, we introduce the mapping relationships between multi-modal sensing and communications, and discuss how channel modeling can be customized to support the exploration of such relationships. Afterwards, we delve into the current research state and implementing challenges of SoM-enhance-based and SoM-concert-based applications. We first overview the SoM-enhance-based communication system designs and present simulation results related to dual-function waveform and predictive beamforming design. Afterwards, we review the recent advances of SoM-concert for single-agent and multi-agent environment sensing. Finally, we propose some open issues and potential directions.
LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
Jun 19, 2023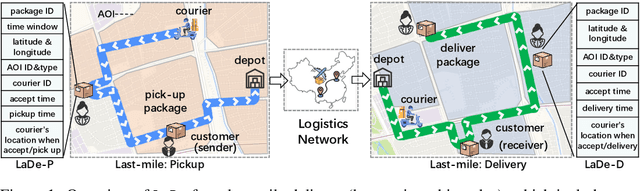

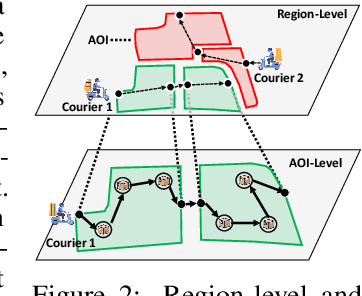
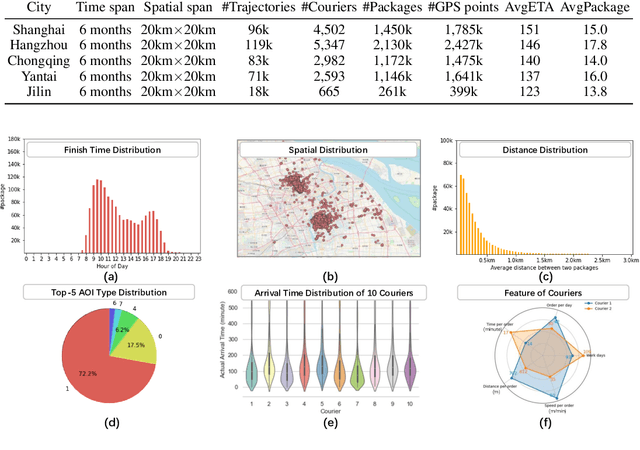
Real-world last-mile delivery datasets are crucial for research in logistics, supply chain management, and spatio-temporal data mining. Despite a plethora of algorithms developed to date, no widely accepted, publicly available last-mile delivery dataset exists to support research in this field. In this paper, we introduce \texttt{LaDe}, the first publicly available last-mile delivery dataset with millions of packages from the industry. LaDe has three unique characteristics: (1) Large-scale. It involves 10,677k packages of 21k couriers over 6 months of real-world operation. (2) Comprehensive information. It offers original package information, such as its location and time requirements, as well as task-event information, which records when and where the courier is while events such as task-accept and task-finish events happen. (3) Diversity. The dataset includes data from various scenarios, including package pick-up and delivery, and from multiple cities, each with its unique spatio-temporal patterns due to their distinct characteristics such as populations. We verify LaDe on three tasks by running several classical baseline models per task. We believe that the large-scale, comprehensive, diverse feature of LaDe can offer unparalleled opportunities to researchers in the supply chain community, data mining community, and beyond. The dataset homepage is publicly available at https://huggingface.co/datasets/Cainiao-AI/LaDe.
FinRL-Meta: A Universe of Near-Real Market Environments for Data-Driven Deep Reinforcement Learning in Quantitative Finance
Dec 13, 2021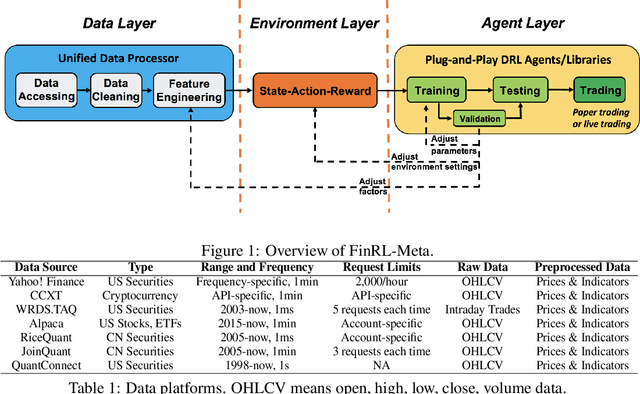
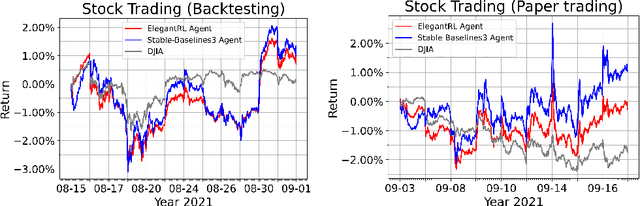

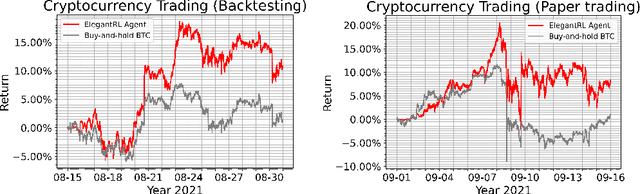
Deep reinforcement learning (DRL) has shown huge potentials in building financial market simulators recently. However, due to the highly complex and dynamic nature of real-world markets, raw historical financial data often involve large noise and may not reflect the future of markets, degrading the fidelity of DRL-based market simulators. Moreover, the accuracy of DRL-based market simulators heavily relies on numerous and diverse DRL agents, which increases demand for a universe of market environments and imposes a challenge on simulation speed. In this paper, we present a FinRL-Meta framework that builds a universe of market environments for data-driven financial reinforcement learning. First, FinRL-Meta separates financial data processing from the design pipeline of DRL-based strategy and provides open-source data engineering tools for financial big data. Second, FinRL-Meta provides hundreds of market environments for various trading tasks. Third, FinRL-Meta enables multiprocessing simulation and training by exploiting thousands of GPU cores. Our codes are available online at https://github.com/AI4Finance-Foundation/FinRL-Meta.
SCMA Codebook Design Based on Uniquely Decomposable Constellation Groups
Mar 06, 2021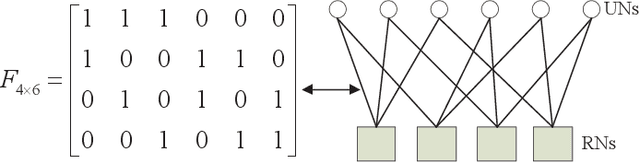
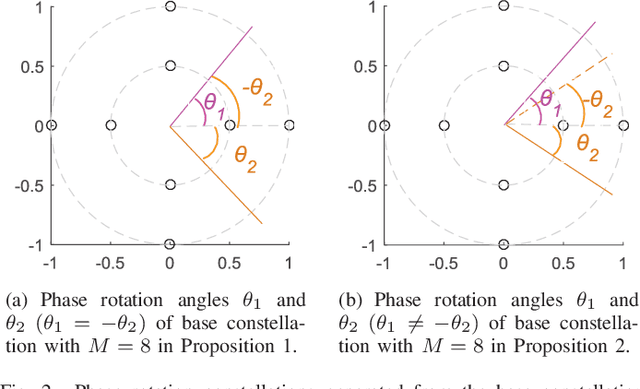
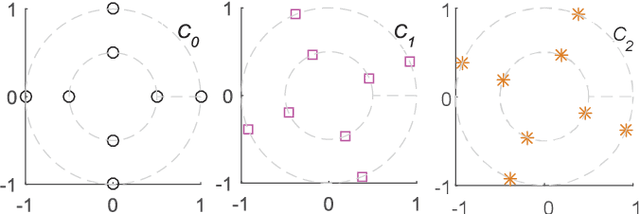
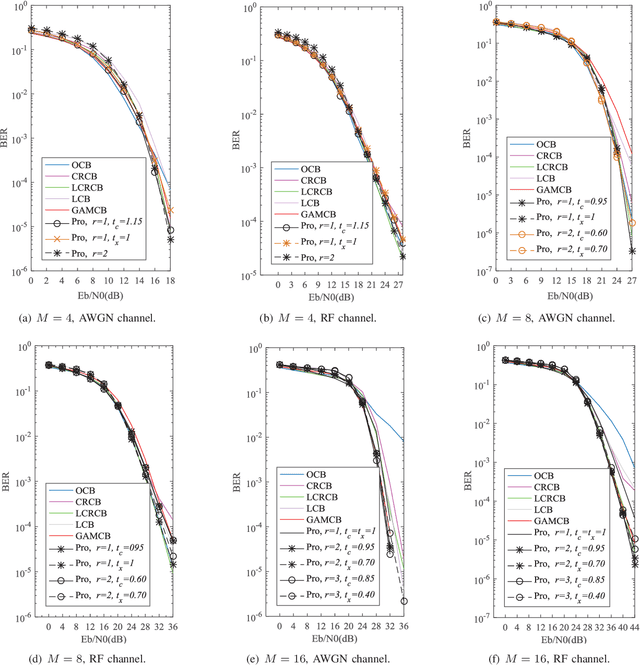
Sparse code multiple access (SCMA), which helps improve spectrum efficiency (SE) and enhance connectivity, has been proposed as a non-orthogonal multiple access (NOMA) scheme for 5G systems. In SCMA, codebook design determines system overload ratio and detection performance at a receiver. In this paper, an SCMA codebook design approach is proposed based on uniquely decomposable constellation group (UDCG). We show that there are $N+1 (N \geq 1)$ constellations in the proposed UDCG, each of which has $M (M \geq 2)$ constellation points. These constellations are allocated to users sharing the same resource. Combining the constellations allocated on multiple resources of each user, we can obtain UDCG-based codebook sets. Bit error ratio (BER) performance will be discussed in terms of coding gain maximization with superimposed constellations and UDCG-based codebooks. Simulation results demonstrate that the superimposed constellation of each resource has large minimum Euclidean distance (MED) and meets uniquely decodable constraint. Thus, BER performance of the proposed codebook design approach outperforms that of the existing codebook design schemes in both uncoded and coded SCMA systems, especially for large-size codebooks.
Adversarial Attacks and Defenses in Physiological Computing: A Systematic Review
Feb 11, 2021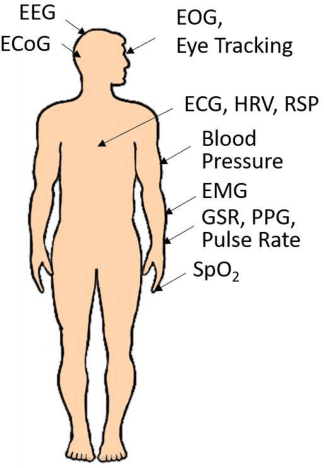
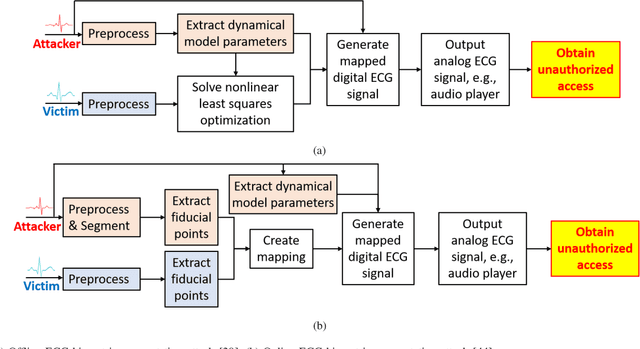
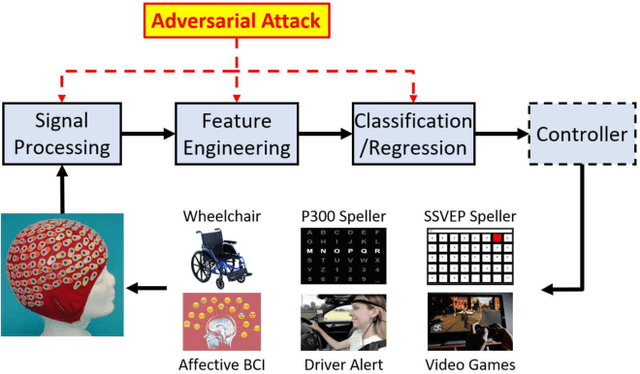
Physiological computing uses human physiological data as system inputs in real time. It includes, or significantly overlaps with, brain-computer interfaces, affective computing, adaptive automation, health informatics, and physiological signal based biometrics. Physiological computing increases the communication bandwidth from the user to the computer, but is also subject to various types of adversarial attacks, in which the attacker deliberately manipulates the training and/or test examples to hijack the machine learning algorithm output, leading to possibly user confusion, frustration, injury, or even death. However, the vulnerability of physiological computing systems has not been paid enough attention to, and there does not exist a comprehensive review on adversarial attacks to it. This paper fills this gap, by providing a systematic review on the main research areas of physiological computing, different types of adversarial attacks and their applications to physiological computing, and the corresponding defense strategies. We hope this review will attract more research interests on the vulnerability of physiological computing systems, and more importantly, defense strategies to make them more secure.
FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance
Nov 19, 2020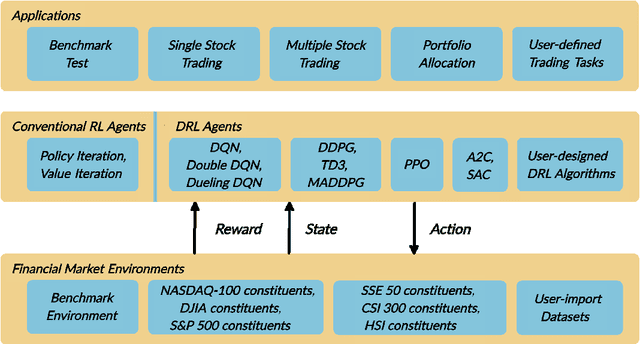
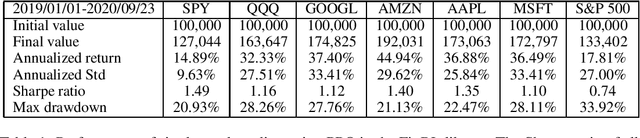
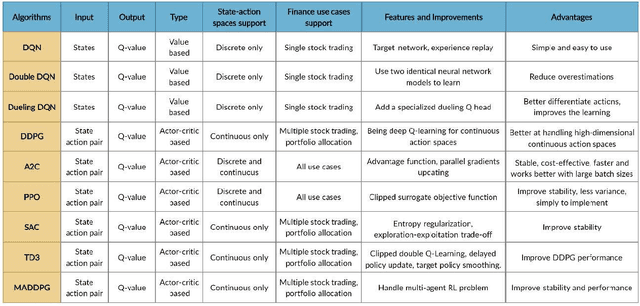
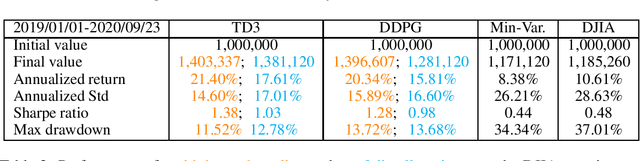
As deep reinforcement learning (DRL) has been recognized as an effective approach in quantitative finance, getting hands-on experiences is attractive to beginners. However, to train a practical DRL trading agent that decides where to trade, at what price, and what quantity involves error-prone and arduous development and debugging. In this paper, we introduce a DRL library FinRL that facilitates beginners to expose themselves to quantitative finance and to develop their own stock trading strategies. Along with easily-reproducible tutorials, FinRL library allows users to streamline their own developments and to compare with existing schemes easily. Within FinRL, virtual environments are configured with stock market datasets, trading agents are trained with neural networks, and extensive backtesting is analyzed via trading performance. Moreover, it incorporates important trading constraints such as transaction cost, market liquidity and the investor's degree of risk-aversion. FinRL is featured with completeness, hands-on tutorial and reproducibility that favors beginners: (i) at multiple levels of time granularity, FinRL simulates trading environments across various stock markets, including NASDAQ-100, DJIA, S&P 500, HSI, SSE 50, and CSI 300; (ii) organized in a layered architecture with modular structure, FinRL provides fine-tuned state-of-the-art DRL algorithms (DQN, DDPG, PPO, SAC, A2C, TD3, etc.), commonly-used reward functions and standard evaluation baselines to alleviate the debugging workloads and promote the reproducibility, and (iii) being highly extendable, FinRL reserves a complete set of user-import interfaces. Furthermore, we incorporated three application demonstrations, namely single stock trading, multiple stock trading, and portfolio allocation. The FinRL library will be available on Github at link https://github.com/AI4Finance-LLC/FinRL-Library.