 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyang Yang
FinGPT: Instruction Tuning Benchmark for Open-Source Large Language Models in Financial Datasets
Oct 07, 2023
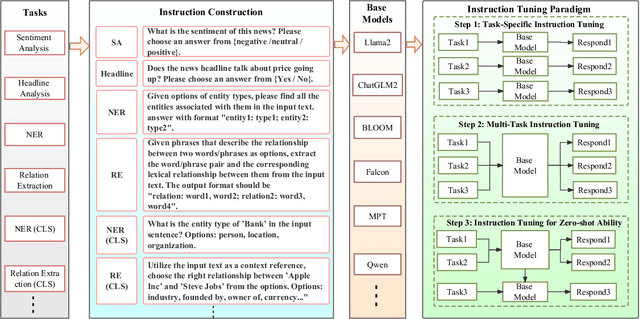
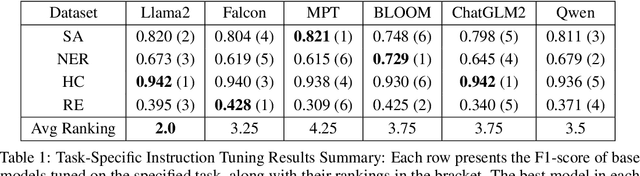
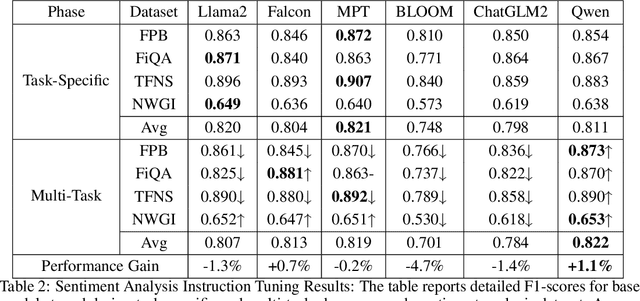
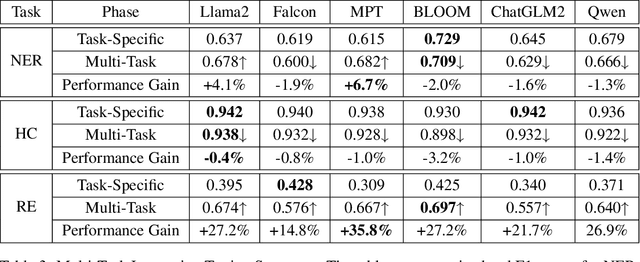
In the swiftly expanding domain of Natural Language Processing (NLP), the potential of GPT-based models for the financial sector is increasingly evident. However, the integration of these models with financial datasets presents challenges, notably in determining their adeptness and relevance. This paper introduces a distinctive approach anchored in the Instruction Tuning paradigm for open-source large language models, specifically adapted for financial contexts. Through this methodology, we capitalize on the interoperability of open-source models, ensuring a seamless and transparent integration. We begin by explaining the Instruction Tuning paradigm, highlighting its effectiveness for immediate integration. The paper presents a benchmarking scheme designed for end-to-end training and testing, employing a cost-effective progression. Firstly, we assess basic competencies and fundamental tasks, such as Named Entity Recognition (NER) and sentiment analysis to enhance specialization. Next, we delve into a comprehensive model, executing multi-task operations by amalgamating all instructional tunings to examine versatility. Finally, we explore the zero-shot capabilities by earmarking unseen tasks and incorporating novel datasets to understand adaptability in uncharted terrains. Such a paradigm fortifies the principles of openness and reproducibility, laying a robust foundation for future investigations in open-source financial large language models (FinLLMs).
Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models
Oct 06, 2023

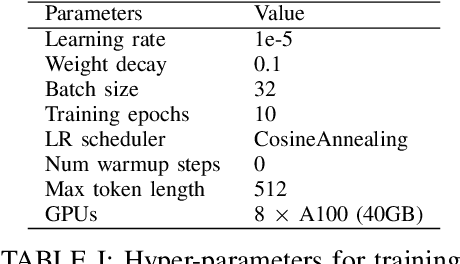
Financial sentiment analysis is critical for valuation and investment decision-making. Traditional NLP models, however, are limited by their parameter size and the scope of their training datasets, which hampers their generalization capabilities and effectiveness in this field. Recently, Large Language Models (LLMs) pre-trained on extensive corpora have demonstrated superior performance across various NLP tasks due to their commendable zero-shot abilities. Yet, directly applying LLMs to financial sentiment analysis presents challenges: The discrepancy between the pre-training objective of LLMs and predicting the sentiment label can compromise their predictive performance. Furthermore, the succinct nature of financial news, often devoid of sufficient context, can significantly diminish the reliability of LLMs' sentiment analysis. To address these challenges, we introduce a retrieval-augmented LLMs framework for financial sentiment analysis. This framework includes an instruction-tuned LLMs module, which ensures LLMs behave as predictors of sentiment labels, and a retrieval-augmentation module which retrieves additional context from reliable external sources. Benchmarked against traditional models and LLMs like ChatGPT and LLaMA, our approach achieves 15\% to 48\% performance gain in accuracy and F1 score.
Instruct-FinGPT: Financial Sentiment Analysis by Instruction Tuning of General-Purpose Large Language Models
Jun 22, 2023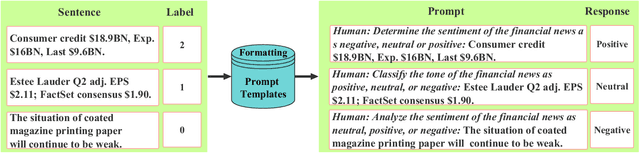
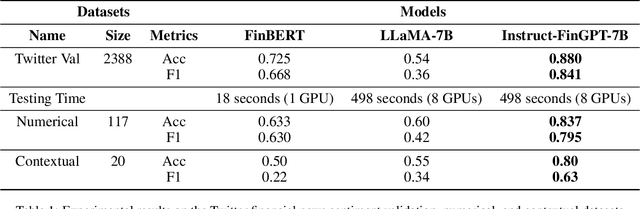
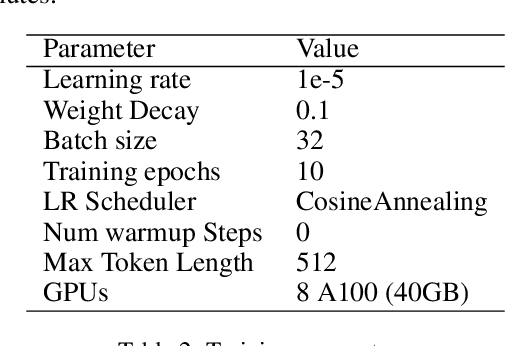
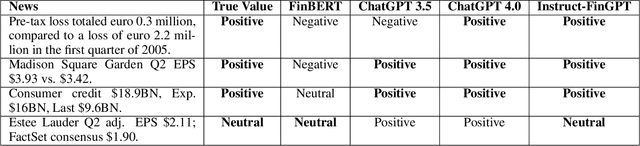
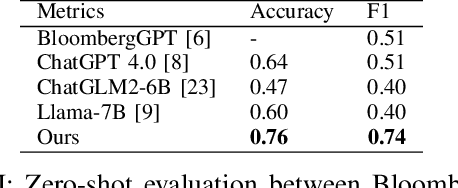
Sentiment analysis is a vital tool for uncovering insights from financial articles, news, and social media, shaping our understanding of market movements. Despite the impressive capabilities of large language models (LLMs) in financial natural language processing (NLP), they still struggle with accurately interpreting numerical values and grasping financial context, limiting their effectiveness in predicting financial sentiment. In this paper, we introduce a simple yet effective instruction tuning approach to address these issues. By transforming a small portion of supervised financial sentiment analysis data into instruction data and fine-tuning a general-purpose LLM with this method, we achieve remarkable advancements in financial sentiment analysis. In the experiment, our approach outperforms state-of-the-art supervised sentiment analysis models, as well as widely used LLMs like ChatGPT and LLaMAs, particularly in scenarios where numerical understanding and contextual comprehension are vital.
FinGPT: Open-Source Financial Large Language Models
Jun 09, 2023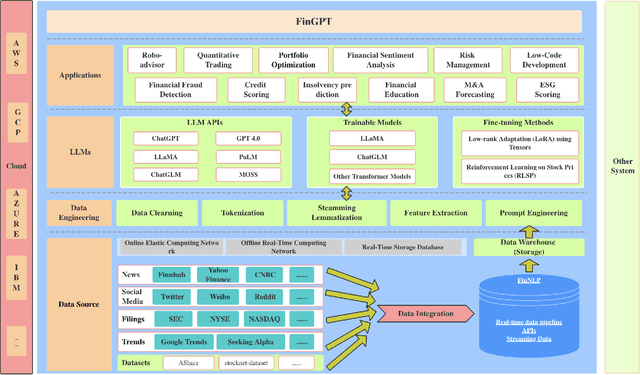
Large language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). While proprietary models like BloombergGPT have taken advantage of their unique data accumulation, such privileged access calls for an open-source alternative to democratize Internet-scale financial data. In this paper, we present an open-source large language model, FinGPT, for the finance sector. Unlike proprietary models, FinGPT takes a data-centric approach, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. We highlight the importance of an automatic data curation pipeline and the lightweight low-rank adaptation technique in building FinGPT. Furthermore, we showcase several potential applications as stepping stones for users, such as robo-advising, algorithmic trading, and low-code development. Through collaborative efforts within the open-source AI4Finance community, FinGPT aims to stimulate innovation, democratize FinLLMs, and unlock new opportunities in open finance. Two associated code repos are \url{https://github.com/AI4Finance-Foundation/FinGPT} and \url{https://github.com/AI4Finance-Foundation/FinNLP}
Dynamic Datasets and Market Environments for Financial Reinforcement Learning
Apr 25, 2023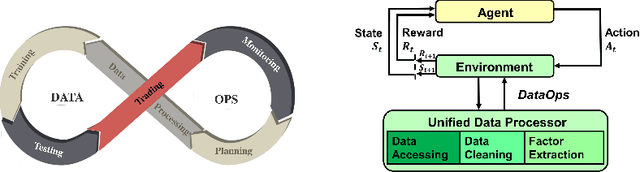
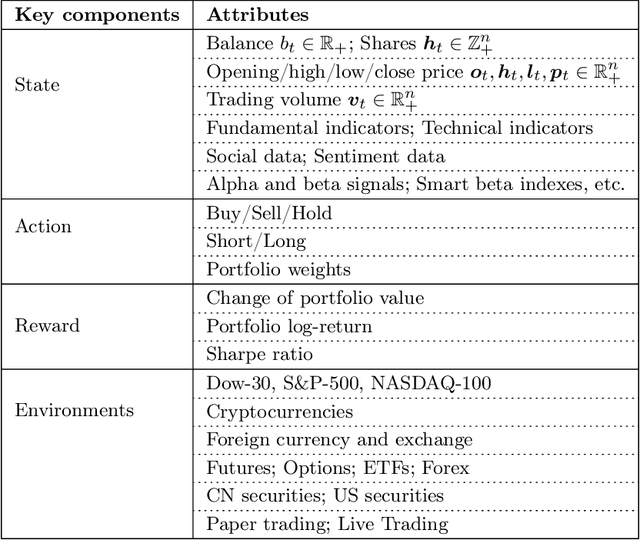
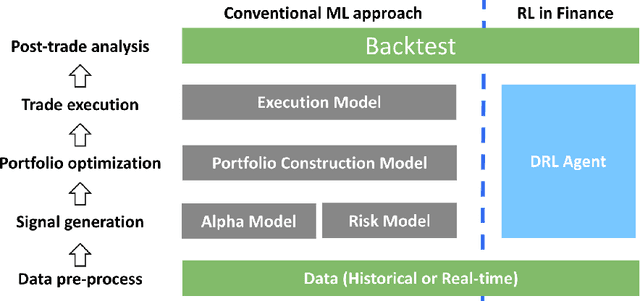
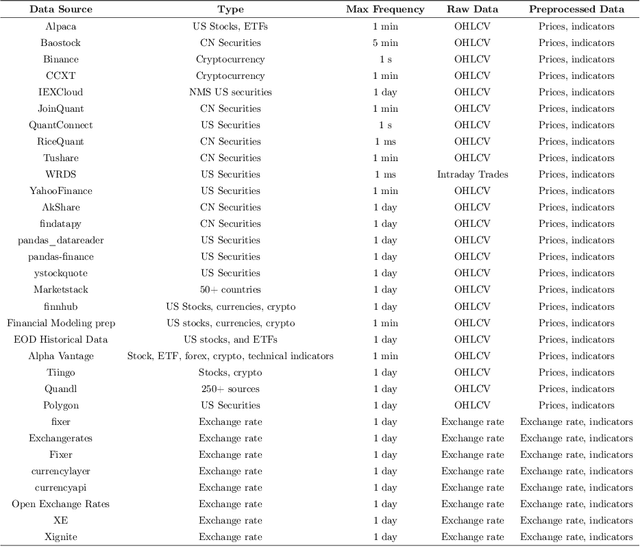
The financial market is a particularly challenging playground for deep reinforcement learning due to its unique feature of dynamic datasets. Building high-quality market environments for training financial reinforcement learning (FinRL) agents is difficult due to major factors such as the low signal-to-noise ratio of financial data, survivorship bias of historical data, and model overfitting. In this paper, we present FinRL-Meta, a data-centric and openly accessible library that processes dynamic datasets from real-world markets into gym-style market environments and has been actively maintained by the AI4Finance community. First, following a DataOps paradigm, we provide hundreds of market environments through an automatic data curation pipeline. Second, we provide homegrown examples and reproduce popular research papers as stepping stones for users to design new trading strategies. We also deploy the library on cloud platforms so that users can visualize their own results and assess the relative performance via community-wise competitions. Third, we provide dozens of Jupyter/Python demos organized into a curriculum and a documentation website to serve the rapidly growing community. The open-source codes for the data curation pipeline are available at https://github.com/AI4Finance-Foundation/FinRL-Meta
FinRL-Meta: A Universe of Near-Real Market Environments for Data-Driven Deep Reinforcement Learning in Quantitative Finance
Dec 13, 2021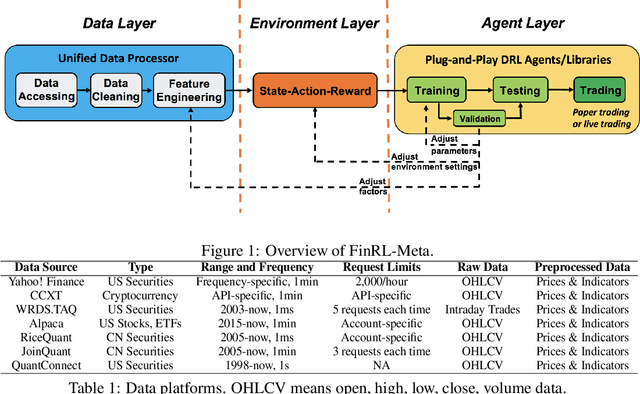
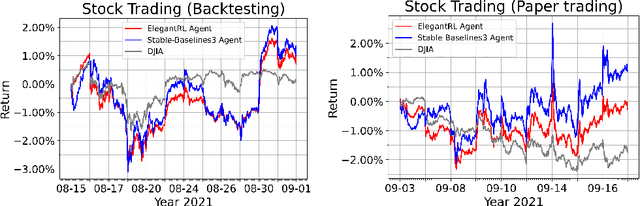

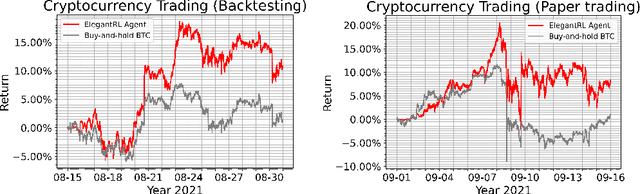
Deep reinforcement learning (DRL) has shown huge potentials in building financial market simulators recently. However, due to the highly complex and dynamic nature of real-world markets, raw historical financial data often involve large noise and may not reflect the future of markets, degrading the fidelity of DRL-based market simulators. Moreover, the accuracy of DRL-based market simulators heavily relies on numerous and diverse DRL agents, which increases demand for a universe of market environments and imposes a challenge on simulation speed. In this paper, we present a FinRL-Meta framework that builds a universe of market environments for data-driven financial reinforcement learning. First, FinRL-Meta separates financial data processing from the design pipeline of DRL-based strategy and provides open-source data engineering tools for financial big data. Second, FinRL-Meta provides hundreds of market environments for various trading tasks. Third, FinRL-Meta enables multiprocessing simulation and training by exploiting thousands of GPU cores. Our codes are available online at https://github.com/AI4Finance-Foundation/FinRL-Meta.
FinRL: Deep Reinforcement Learning Framework to Automate Trading in Quantitative Finance
Nov 07, 2021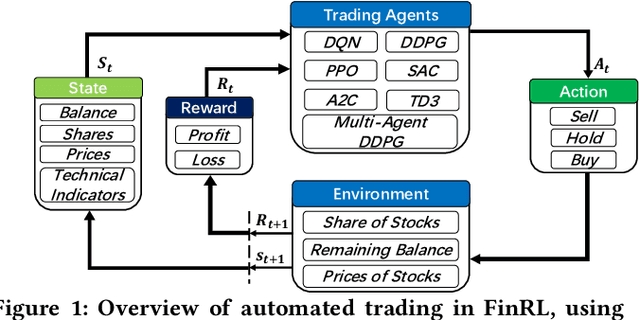
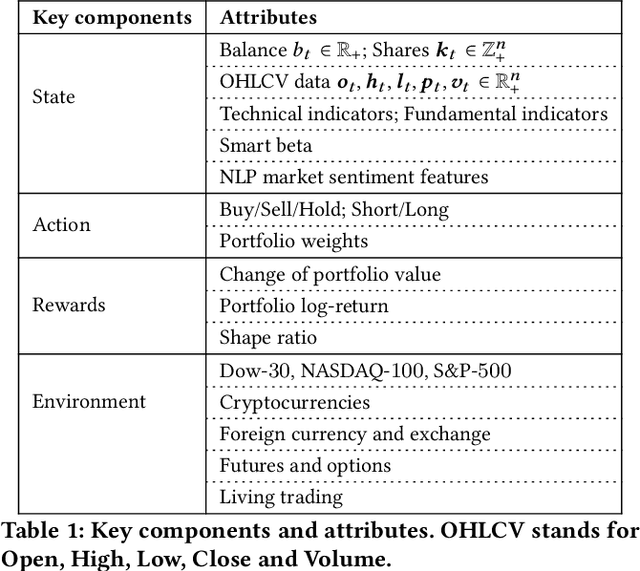


Deep reinforcement learning (DRL) has been envisioned to have a competitive edge in quantitative finance. However, there is a steep development curve for quantitative traders to obtain an agent that automatically positions to win in the market, namely \textit{to decide where to trade, at what price} and \textit{what quantity}, due to the error-prone programming and arduous debugging. In this paper, we present the first open-source framework \textit{FinRL} as a full pipeline to help quantitative traders overcome the steep learning curve. FinRL is featured with simplicity, applicability and extensibility under the key principles, \textit{full-stack framework, customization, reproducibility} and \textit{hands-on tutoring}. Embodied as a three-layer architecture with modular structures, FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads. Thus, we help users pipeline the strategy design at a high turnover rate. At multiple levels of time granularity, FinRL simulates various markets as training environments using historical data and live trading APIs. Being highly extensible, FinRL reserves a set of user-import interfaces and incorporates trading constraints such as market friction, market liquidity and investor's risk-aversion. Moreover, serving as practitioners' stepping stones, typical trading tasks are provided as step-by-step tutorials, e.g., stock trading, portfolio allocation, cryptocurrency trading, etc.
* ACM International Conference on AI in Finance
FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance
Nov 19, 2020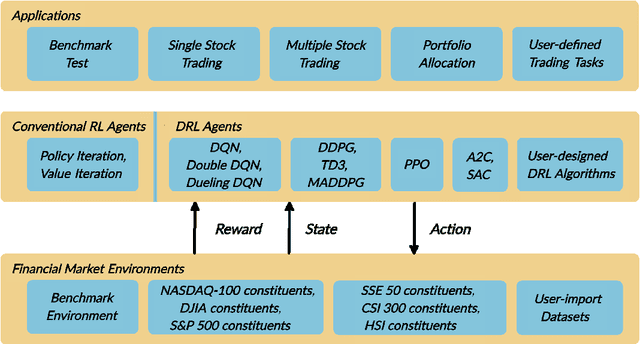
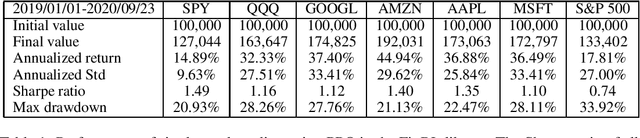
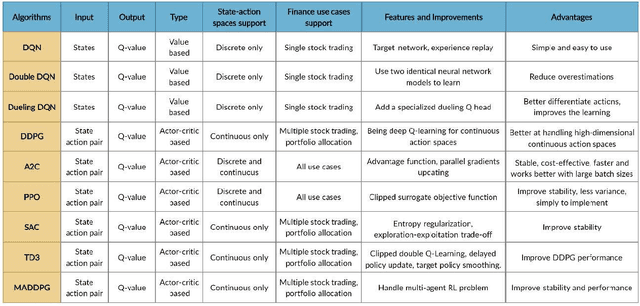
As deep reinforcement learning (DRL) has been recognized as an effective approach in quantitative finance, getting hands-on experiences is attractive to beginners. However, to train a practical DRL trading agent that decides where to trade, at what price, and what quantity involves error-prone and arduous development and debugging. In this paper, we introduce a DRL library FinRL that facilitates beginners to expose themselves to quantitative finance and to develop their own stock trading strategies. Along with easily-reproducible tutorials, FinRL library allows users to streamline their own developments and to compare with existing schemes easily. Within FinRL, virtual environments are configured with stock market datasets, trading agents are trained with neural networks, and extensive backtesting is analyzed via trading performance. Moreover, it incorporates important trading constraints such as transaction cost, market liquidity and the investor's degree of risk-aversion. FinRL is featured with completeness, hands-on tutorial and reproducibility that favors beginners: (i) at multiple levels of time granularity, FinRL simulates trading environments across various stock markets, including NASDAQ-100, DJIA, S&P 500, HSI, SSE 50, and CSI 300; (ii) organized in a layered architecture with modular structure, FinRL provides fine-tuned state-of-the-art DRL algorithms (DQN, DDPG, PPO, SAC, A2C, TD3, etc.), commonly-used reward functions and standard evaluation baselines to alleviate the debugging workloads and promote the reproducibility, and (iii) being highly extendable, FinRL reserves a complete set of user-import interfaces. Furthermore, we incorporated three application demonstrations, namely single stock trading, multiple stock trading, and portfolio allocation. The FinRL library will be available on Github at link https://github.com/AI4Finance-LLC/FinRL-Library.
DP-LSTM: Differential Privacy-inspired LSTM for Stock Prediction Using Financial News
Dec 20, 2019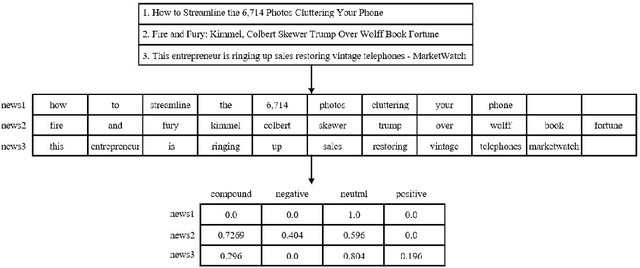
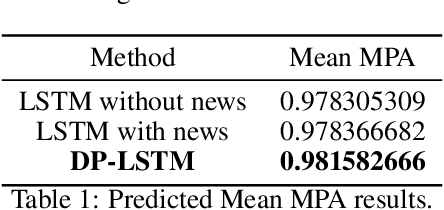

Stock price prediction is important for value investments in the stock market. In particular, short-term prediction that exploits financial news articles is promising in recent years. In this paper, we propose a novel deep neural network DP-LSTM for stock price prediction, which incorporates the news articles as hidden information and integrates difference news sources through the differential privacy mechanism. First, based on the autoregressive moving average model (ARMA), a sentiment-ARMA is formulated by taking into consideration the information of financial news articles in the model. Then, an LSTM-based deep neural network is designed, which consists of three components: LSTM, VADER model and differential privacy (DP) mechanism. The proposed DP-LSTM scheme can reduce prediction errors and increase the robustness. Extensive experiments on S&P 500 stocks show that (i) the proposed DP-LSTM achieves 0.32% improvement in mean MPA of prediction result, and (ii) for the prediction of the market index S&P 500, we achieve up to 65.79% improvement in MSE.
Practical Deep Reinforcement Learning Approach for Stock Trading
Dec 02, 2018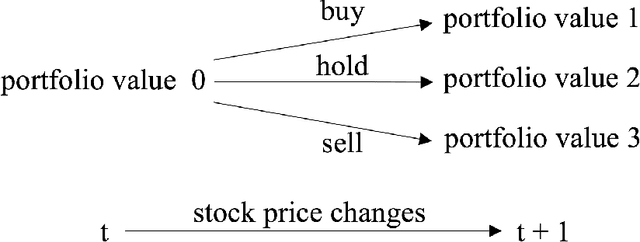
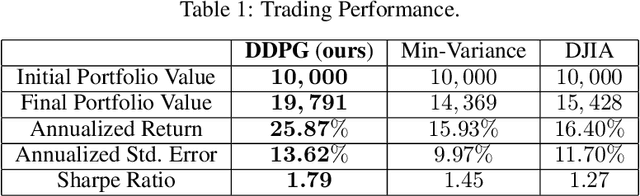
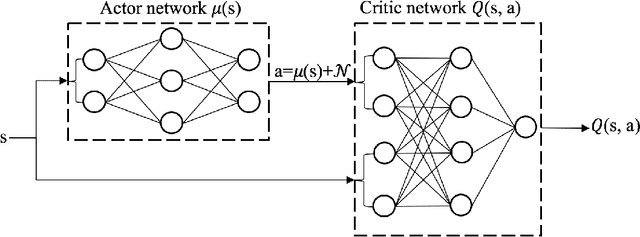
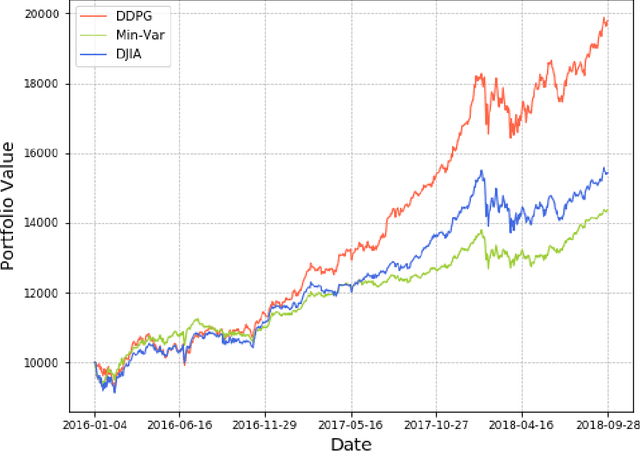
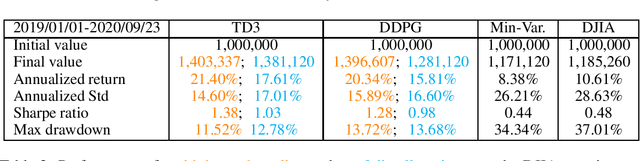
Stock trading strategy plays a crucial role in investment companies. However, it is challenging to obtain optimal strategy in the complex and dynamic stock market. We explore the potential of deep reinforcement learning to optimize stock trading strategy and thus maximize investment return. 30 stocks are selected as our trading stocks and their daily prices are used as the training and trading market environment. We train a deep reinforcement learning agent and obtain an adaptive trading strategy. The agent's performance is evaluated and compared with Dow Jones Industrial Average and the traditional min-variance portfolio allocation strategy. The proposed deep reinforcement learning approach is shown to outperform the two baselines in terms of both the Sharpe ratio and cumulative returns.