 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLorenzo Porzi
Revising Densification in Gaussian Splatting
Apr 09, 2024
In this paper, we address the limitations of Adaptive Density Control (ADC) in 3D Gaussian Splatting (3DGS), a scene representation method achieving high-quality, photorealistic results for novel view synthesis. ADC has been introduced for automatic 3D point primitive management, controlling densification and pruning, however, with certain limitations in the densification logic. Our main contribution is a more principled, pixel-error driven formulation for density control in 3DGS, leveraging an auxiliary, per-pixel error function as the criterion for densification. We further introduce a mechanism to control the total number of primitives generated per scene and correct a bias in the current opacity handling strategy of ADC during cloning operations. Our approach leads to consistent quality improvements across a variety of benchmark scenes, without sacrificing the method's efficiency.
Robust Gaussian Splatting
Apr 05, 2024In this paper, we address common error sources for 3D Gaussian Splatting (3DGS) including blur, imperfect camera poses, and color inconsistencies, with the goal of improving its robustness for practical applications like reconstructions from handheld phone captures. Our main contribution involves modeling motion blur as a Gaussian distribution over camera poses, allowing us to address both camera pose refinement and motion blur correction in a unified way. Additionally, we propose mechanisms for defocus blur compensation and for addressing color in-consistencies caused by ambient light, shadows, or due to camera-related factors like varying white balancing settings. Our proposed solutions integrate in a seamless way with the 3DGS formulation while maintaining its benefits in terms of training efficiency and rendering speed. We experimentally validate our contributions on relevant benchmark datasets including Scannet++ and Deblur-NeRF, obtaining state-of-the-art results and thus consistent improvements over relevant baselines.
Multi-Level Neural Scene Graphs for Dynamic Urban Environments
Mar 29, 2024We estimate the radiance field of large-scale dynamic areas from multiple vehicle captures under varying environmental conditions. Previous works in this domain are either restricted to static environments, do not scale to more than a single short video, or struggle to separately represent dynamic object instances. To this end, we present a novel, decomposable radiance field approach for dynamic urban environments. We propose a multi-level neural scene graph representation that scales to thousands of images from dozens of sequences with hundreds of fast-moving objects. To enable efficient training and rendering of our representation, we develop a fast composite ray sampling and rendering scheme. To test our approach in urban driving scenarios, we introduce a new, novel view synthesis benchmark. We show that our approach outperforms prior art by a significant margin on both established and our proposed benchmark while being faster in training and rendering.
HybridNeRF: Efficient Neural Rendering via Adaptive Volumetric Surfaces
Dec 05, 2023Neural radiance fields provide state-of-the-art view synthesis quality but tend to be slow to render. One reason is that they make use of volume rendering, thus requiring many samples (and model queries) per ray at render time. Although this representation is flexible and easy to optimize, most real-world objects can be modeled more efficiently with surfaces instead of volumes, requiring far fewer samples per ray. This observation has spurred considerable progress in surface representations such as signed distance functions, but these may struggle to model semi-opaque and thin structures. We propose a method, HybridNeRF, that leverages the strengths of both representations by rendering most objects as surfaces while modeling the (typically) small fraction of challenging regions volumetrically. We evaluate HybridNeRF against the challenging Eyeful Tower dataset along with other commonly used view synthesis datasets. When comparing to state-of-the-art baselines, including recent rasterization-based approaches, we improve error rates by 15-30% while achieving real-time framerates (at least 36 FPS) for virtual-reality resolutions (2Kx2K).
VR-NeRF: High-Fidelity Virtualized Walkable Spaces
Nov 05, 2023We present an end-to-end system for the high-fidelity capture, model reconstruction, and real-time rendering of walkable spaces in virtual reality using neural radiance fields. To this end, we designed and built a custom multi-camera rig to densely capture walkable spaces in high fidelity and with multi-view high dynamic range images in unprecedented quality and density. We extend instant neural graphics primitives with a novel perceptual color space for learning accurate HDR appearance, and an efficient mip-mapping mechanism for level-of-detail rendering with anti-aliasing, while carefully optimizing the trade-off between quality and speed. Our multi-GPU renderer enables high-fidelity volume rendering of our neural radiance field model at the full VR resolution of dual 2K$\times$2K at 36 Hz on our custom demo machine. We demonstrate the quality of our results on our challenging high-fidelity datasets, and compare our method and datasets to existing baselines. We release our dataset on our project website.
GANeRF: Leveraging Discriminators to Optimize Neural Radiance Fields
Jun 09, 2023

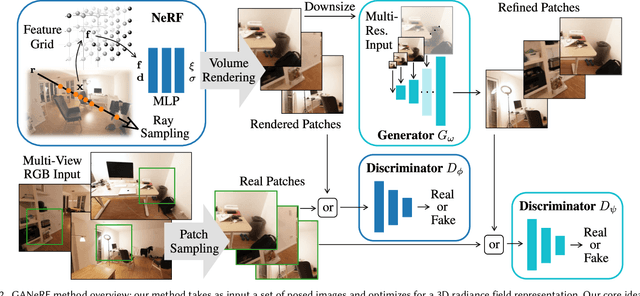
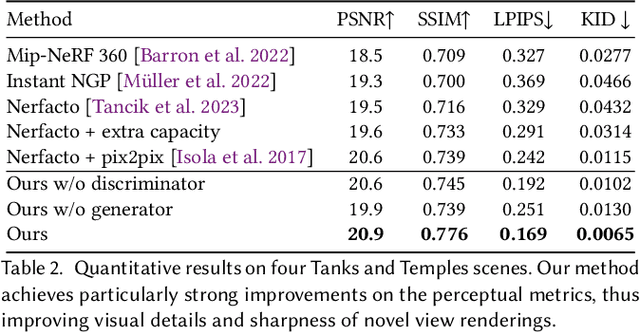
Neural Radiance Fields (NeRF) have shown impressive novel view synthesis results; nonetheless, even thorough recordings yield imperfections in reconstructions, for instance due to poorly observed areas or minor lighting changes. Our goal is to mitigate these imperfections from various sources with a joint solution: we take advantage of the ability of generative adversarial networks (GANs) to produce realistic images and use them to enhance realism in 3D scene reconstruction with NeRFs. To this end, we learn the patch distribution of a scene using an adversarial discriminator, which provides feedback to the radiance field reconstruction, thus improving realism in a 3D-consistent fashion. Thereby, rendering artifacts are repaired directly in the underlying 3D representation by imposing multi-view path rendering constraints. In addition, we condition a generator with multi-resolution NeRF renderings which is adversarially trained to further improve rendering quality. We demonstrate that our approach significantly improves rendering quality, e.g., nearly halving LPIPS scores compared to Nerfacto while at the same time improving PSNR by 1.4dB on the advanced indoor scenes of Tanks and Temples.
Panoptic Lifting for 3D Scene Understanding with Neural Fields
Dec 19, 2022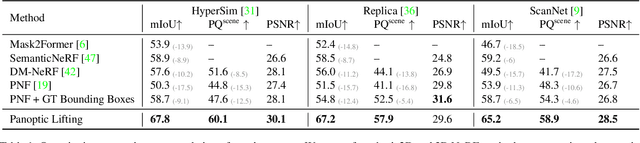
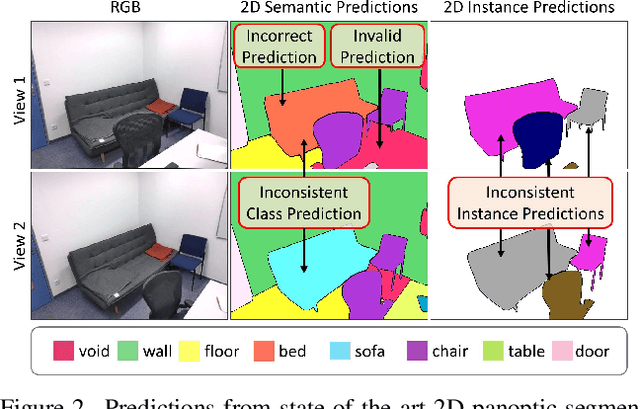
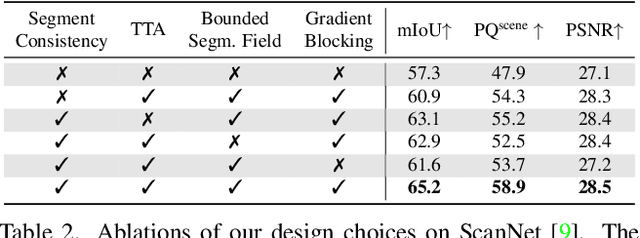
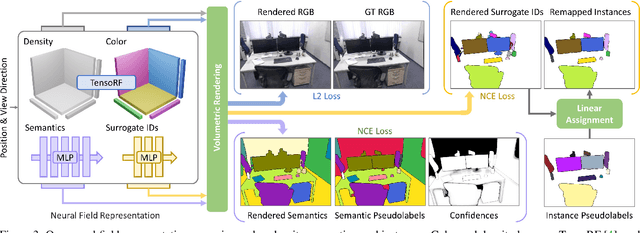
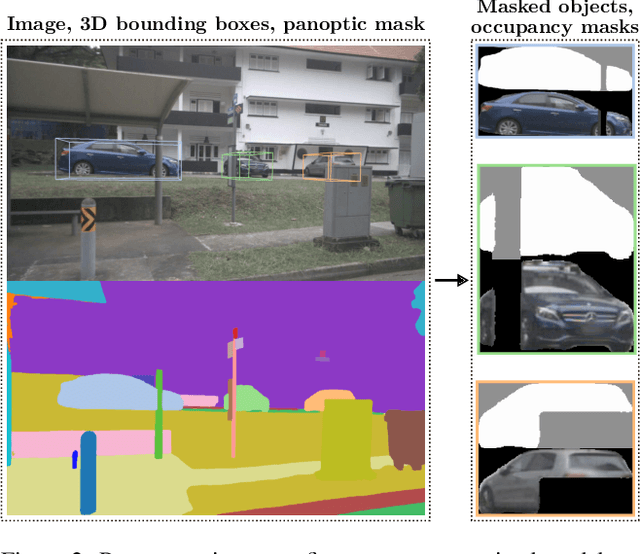
We propose Panoptic Lifting, a novel approach for learning panoptic 3D volumetric representations from images of in-the-wild scenes. Once trained, our model can render color images together with 3D-consistent panoptic segmentation from novel viewpoints. Unlike existing approaches which use 3D input directly or indirectly, our method requires only machine-generated 2D panoptic segmentation masks inferred from a pre-trained network. Our core contribution is a panoptic lifting scheme based on a neural field representation that generates a unified and multi-view consistent, 3D panoptic representation of the scene. To account for inconsistencies of 2D instance identifiers across views, we solve a linear assignment with a cost based on the model's current predictions and the machine-generated segmentation masks, thus enabling us to lift 2D instances to 3D in a consistent way. We further propose and ablate contributions that make our method more robust to noisy, machine-generated labels, including test-time augmentations for confidence estimates, segment consistency loss, bounded segmentation fields, and gradient stopping. Experimental results validate our approach on the challenging Hypersim, Replica, and ScanNet datasets, improving by 8.4, 13.8, and 10.6% in scene-level PQ over state of the art.
DiffRF: Rendering-Guided 3D Radiance Field Diffusion
Dec 02, 2022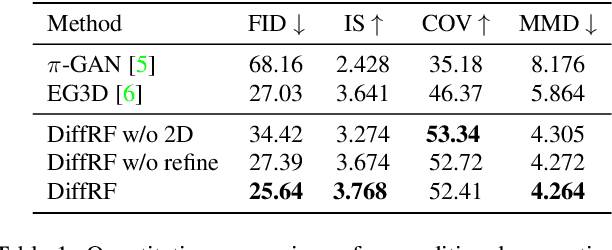
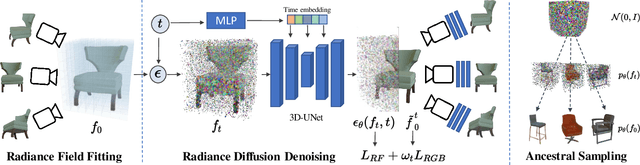
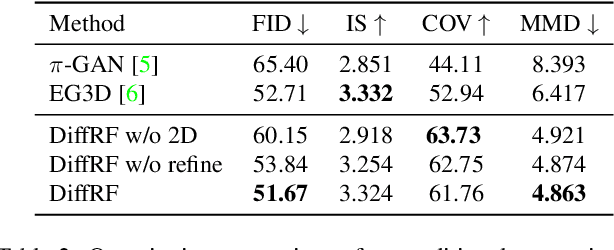
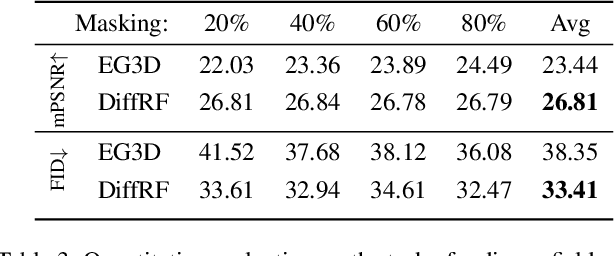
We introduce DiffRF, a novel approach for 3D radiance field synthesis based on denoising diffusion probabilistic models. While existing diffusion-based methods operate on images, latent codes, or point cloud data, we are the first to directly generate volumetric radiance fields. To this end, we propose a 3D denoising model which directly operates on an explicit voxel grid representation. However, as radiance fields generated from a set of posed images can be ambiguous and contain artifacts, obtaining ground truth radiance field samples is non-trivial. We address this challenge by pairing the denoising formulation with a rendering loss, enabling our model to learn a deviated prior that favours good image quality instead of trying to replicate fitting errors like floating artifacts. In contrast to 2D-diffusion models, our model learns multi-view consistent priors, enabling free-view synthesis and accurate shape generation. Compared to 3D GANs, our diffusion-based approach naturally enables conditional generation such as masked completion or single-view 3D synthesis at inference time.
AutoRF: Learning 3D Object Radiance Fields from Single View Observations
Apr 07, 2022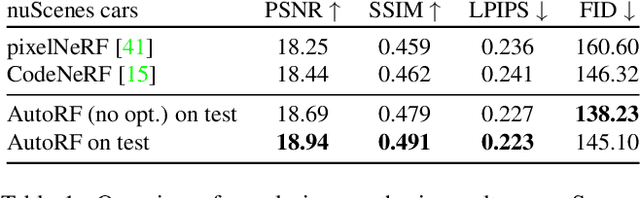
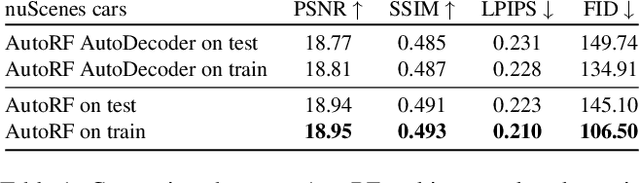
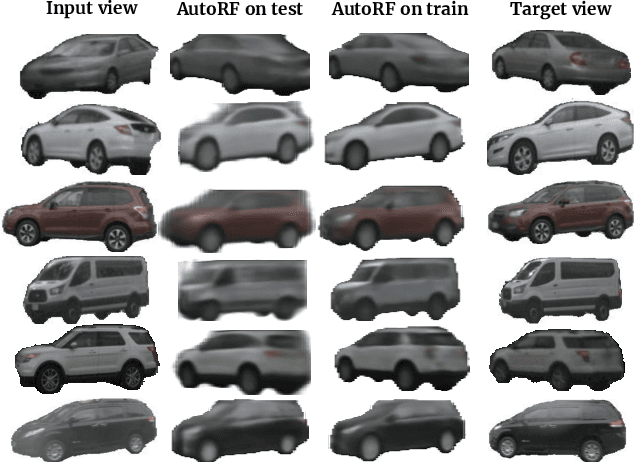
We introduce AutoRF - a new approach for learning neural 3D object representations where each object in the training set is observed by only a single view. This setting is in stark contrast to the majority of existing works that leverage multiple views of the same object, employ explicit priors during training, or require pixel-perfect annotations. To address this challenging setting, we propose to learn a normalized, object-centric representation whose embedding describes and disentangles shape, appearance, and pose. Each encoding provides well-generalizable, compact information about the object of interest, which is decoded in a single-shot into a new target view, thus enabling novel view synthesis. We further improve the reconstruction quality by optimizing shape and appearance codes at test time by fitting the representation tightly to the input image. In a series of experiments, we show that our method generalizes well to unseen objects, even across different datasets of challenging real-world street scenes such as nuScenes, KITTI, and Mapillary Metropolis.
Inferring Latent Domains for Unsupervised Deep Domain Adaptation
Mar 25, 2021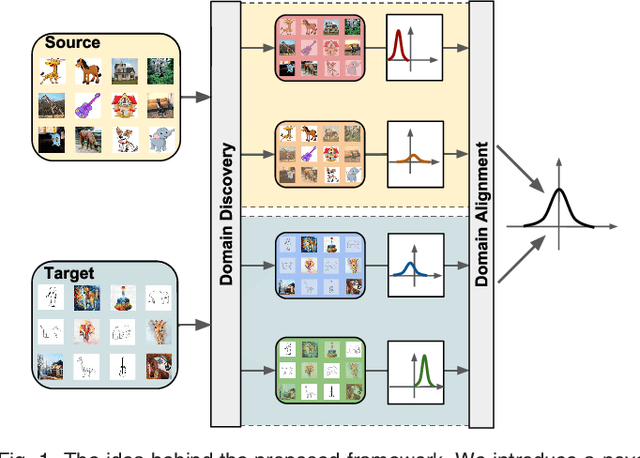

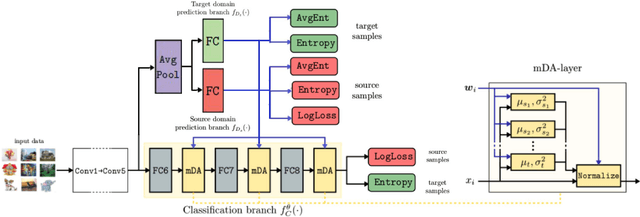
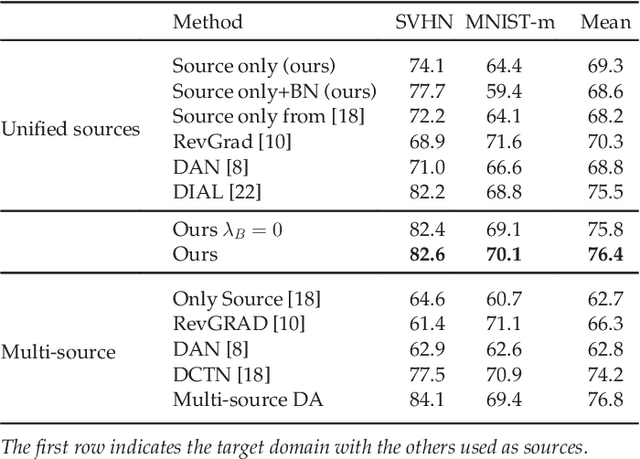
Unsupervised Domain Adaptation (UDA) refers to the problem of learning a model in a target domain where labeled data are not available by leveraging information from annotated data in a source domain. Most deep UDA approaches operate in a single-source, single-target scenario, i.e. they assume that the source and the target samples arise from a single distribution. However, in practice most datasets can be regarded as mixtures of multiple domains. In these cases, exploiting traditional single-source, single-target methods for learning classification models may lead to poor results. Furthermore, it is often difficult to provide the domain labels for all data points, i.e. latent domains should be automatically discovered. This paper introduces a novel deep architecture which addresses the problem of UDA by automatically discovering latent domains in visual datasets and exploiting this information to learn robust target classifiers. Specifically, our architecture is based on two main components, i.e. a side branch that automatically computes the assignment of each sample to its latent domain and novel layers that exploit domain membership information to appropriately align the distribution of the CNN internal feature representations to a reference distribution. We evaluate our approach on publicly available benchmarks, showing that it outperforms state-of-the-art domain adaptation methods.