 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMartin Danelljan
Efficient Video Object Segmentation via Modulated Cross-Attention Memory
Mar 26, 2024
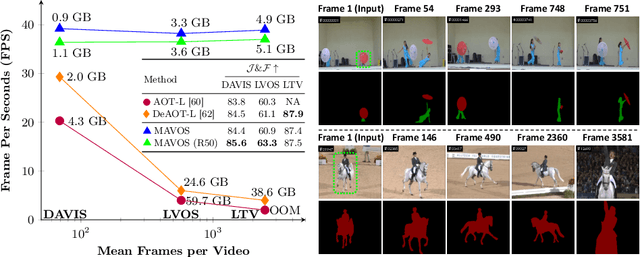

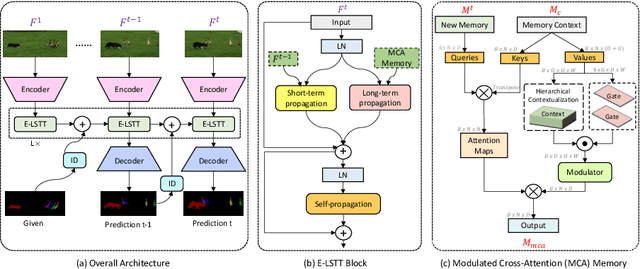
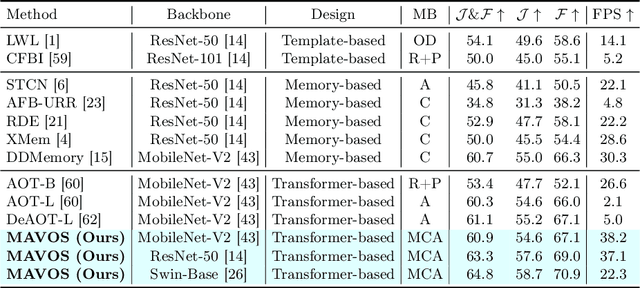
Recently, transformer-based approaches have shown promising results for semi-supervised video object segmentation. However, these approaches typically struggle on long videos due to increased GPU memory demands, as they frequently expand the memory bank every few frames. We propose a transformer-based approach, named MAVOS, that introduces an optimized and dynamic long-term modulated cross-attention (MCA) memory to model temporal smoothness without requiring frequent memory expansion. The proposed MCA effectively encodes both local and global features at various levels of granularity while efficiently maintaining consistent speed regardless of the video length. Extensive experiments on multiple benchmarks, LVOS, Long-Time Video, and DAVIS 2017, demonstrate the effectiveness of our proposed contributions leading to real-time inference and markedly reduced memory demands without any degradation in segmentation accuracy on long videos. Compared to the best existing transformer-based approach, our MAVOS increases the speed by 7.6x, while significantly reducing the GPU memory by 87% with comparable segmentation performance on short and long video datasets. Notably on the LVOS dataset, our MAVOS achieves a J&F score of 63.3% while operating at 37 frames per second (FPS) on a single V100 GPU. Our code and models will be publicly available at: https://github.com/Amshaker/MAVOS.
Analyzing Local Representations of Self-supervised Vision Transformers
Dec 31, 2023In this paper, we present a comparative analysis of various self-supervised Vision Transformers (ViTs), focusing on their local representative power. Inspired by large language models, we examine the abilities of ViTs to perform various computer vision tasks with little to no fine-tuning. We design an evaluation framework to analyze the quality of local, i.e. patch-level, representations in the context of few-shot semantic segmentation, instance identification, object retrieval, and tracking. We discover that contrastive learning based methods like DINO produce more universal patch representations that can be immediately applied for downstream tasks with no parameter tuning, compared to masked image modeling. The embeddings learned using the latter approach, e.g. in masked autoencoders, have high variance features that harm distance-based algorithms, such as k-NN, and do not contain useful information for most downstream tasks. Furthermore, we demonstrate that removing these high-variance features enhances k-NN by providing an analysis of the benchmarks for this work and for Scale-MAE, a recent extension of masked autoencoders. Finally, we find an object instance retrieval setting where DINOv2, a model pretrained on two orders of magnitude more data, performs worse than its less compute-intensive counterpart DINO.
Diffusion-Based Particle-DETR for BEV Perception
Dec 18, 2023The Bird-Eye-View (BEV) is one of the most widely-used scene representations for visual perception in Autonomous Vehicles (AVs) due to its well suited compatibility to downstream tasks. For the enhanced safety of AVs, modeling perception uncertainty in BEV is crucial. Recent diffusion-based methods offer a promising approach to uncertainty modeling for visual perception but fail to effectively detect small objects in the large coverage of the BEV. Such degradation of performance can be attributed primarily to the specific network architectures and the matching strategy used when training. Here, we address this problem by combining the diffusion paradigm with current state-of-the-art 3D object detectors in BEV. We analyze the unique challenges of this approach, which do not exist with deterministic detectors, and present a simple technique based on object query interpolation that allows the model to learn positional dependencies even in the presence of the diffusion noise. Based on this, we present a diffusion-based DETR model for object detection that bears similarities to particle methods. Abundant experimentation on the NuScenes dataset shows equal or better performance for our generative approach, compared to deterministic state-of-the-art methods. Our source code will be made publicly available.
Gaussian Grouping: Segment and Edit Anything in 3D Scenes
Dec 01, 2023The recent Gaussian Splatting achieves high-quality and real-time novel-view synthesis of the 3D scenes. However, it is solely concentrated on the appearance and geometry modeling, while lacking in fine-grained object-level scene understanding. To address this issue, we propose Gaussian Grouping, which extends Gaussian Splatting to jointly reconstruct and segment anything in open-world 3D scenes. We augment each Gaussian with a compact Identity Encoding, allowing the Gaussians to be grouped according to their object instance or stuff membership in the 3D scene. Instead of resorting to expensive 3D labels, we supervise the Identity Encodings during the differentiable rendering by leveraging the 2D mask predictions by SAM, along with introduced 3D spatial consistency regularization. Comparing to the implicit NeRF representation, we show that the discrete and grouped 3D Gaussians can reconstruct, segment and edit anything in 3D with high visual quality, fine granularity and efficiency. Based on Gaussian Grouping, we further propose a local Gaussian Editing scheme, which shows efficacy in versatile scene editing applications, including 3D object removal, inpainting, colorization and scene recomposition. Our code and models will be at https://github.com/lkeab/gaussian-grouping.
Probabilistic Sampling of Balanced K-Means using Adiabatic Quantum Computing
Oct 18, 2023Adiabatic quantum computing (AQC) is a promising quantum computing approach for discrete and often NP-hard optimization problems. Current AQCs allow to implement problems of research interest, which has sparked the development of quantum representations for many machine learning and computer vision tasks. Despite requiring multiple measurements from the noisy AQC, current approaches only utilize the best measurement, discarding information contained in the remaining ones. In this work, we explore the potential of using this information for probabilistic balanced k-means clustering. Instead of discarding non-optimal solutions, we propose to use them to compute calibrated posterior probabilities with little additional compute cost. This allows us to identify ambiguous solutions and data points, which we demonstrate on a D-Wave AQC on synthetic and real data.
R3D3: Dense 3D Reconstruction of Dynamic Scenes from Multiple Cameras
Aug 28, 2023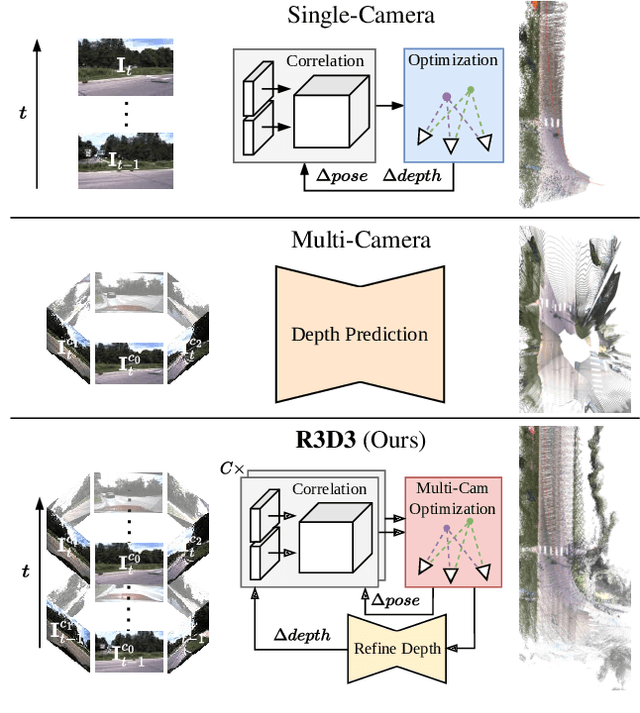

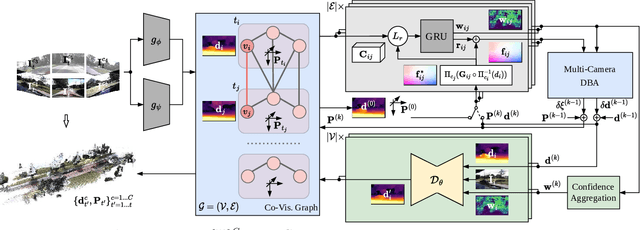
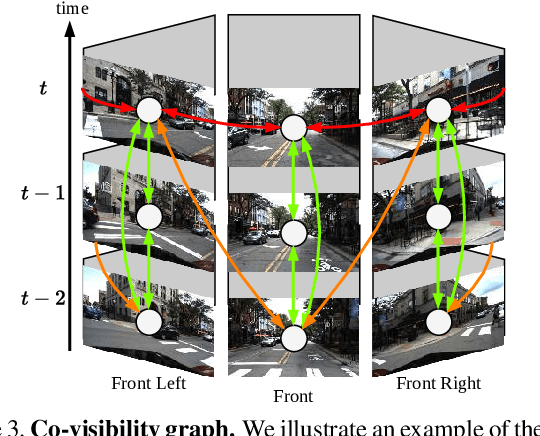
Dense 3D reconstruction and ego-motion estimation are key challenges in autonomous driving and robotics. Compared to the complex, multi-modal systems deployed today, multi-camera systems provide a simpler, low-cost alternative. However, camera-based 3D reconstruction of complex dynamic scenes has proven extremely difficult, as existing solutions often produce incomplete or incoherent results. We propose R3D3, a multi-camera system for dense 3D reconstruction and ego-motion estimation. Our approach iterates between geometric estimation that exploits spatial-temporal information from multiple cameras, and monocular depth refinement. We integrate multi-camera feature correlation and dense bundle adjustment operators that yield robust geometric depth and pose estimates. To improve reconstruction where geometric depth is unreliable, e.g. for moving objects or low-textured regions, we introduce learnable scene priors via a depth refinement network. We show that this design enables a dense, consistent 3D reconstruction of challenging, dynamic outdoor environments. Consequently, we achieve state-of-the-art dense depth prediction on the DDAD and NuScenes benchmarks.
MolGrapher: Graph-based Visual Recognition of Chemical Structures
Aug 23, 2023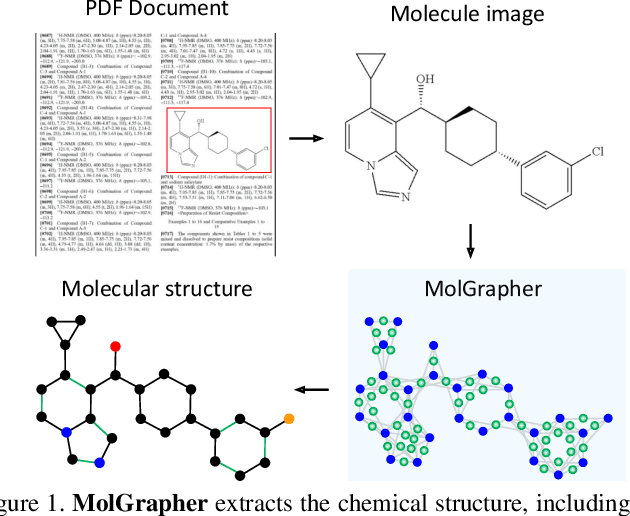

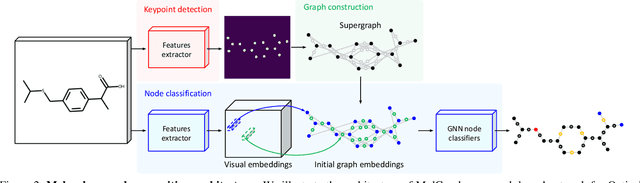
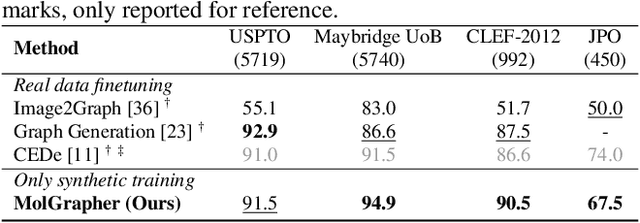
The automatic analysis of chemical literature has immense potential to accelerate the discovery of new materials and drugs. Much of the critical information in patent documents and scientific articles is contained in figures, depicting the molecule structures. However, automatically parsing the exact chemical structure is a formidable challenge, due to the amount of detailed information, the diversity of drawing styles, and the need for training data. In this work, we introduce MolGrapher to recognize chemical structures visually. First, a deep keypoint detector detects the atoms. Second, we treat all candidate atoms and bonds as nodes and put them in a graph. This construct allows a natural graph representation of the molecule. Last, we classify atom and bond nodes in the graph with a Graph Neural Network. To address the lack of real training data, we propose a synthetic data generation pipeline producing diverse and realistic results. In addition, we introduce a large-scale benchmark of annotated real molecule images, USPTO-30K, to spur research on this critical topic. Extensive experiments on five datasets show that our approach significantly outperforms classical and learning-based methods in most settings. Code, models, and datasets are available.
Strategic Preys Make Acute Predators: Enhancing Camouflaged Object Detectors by Generating Camouflaged Objects
Aug 06, 2023
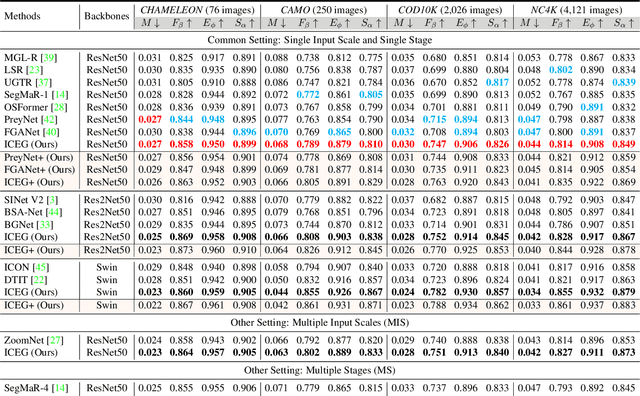
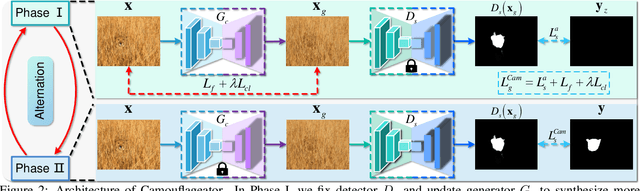
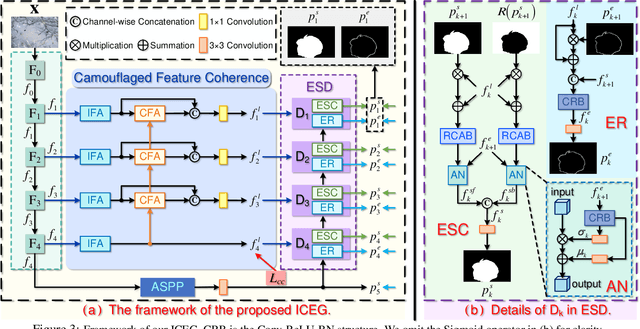
Camouflaged object detection (COD) is the challenging task of identifying camouflaged objects visually blended into surroundings. Albeit achieving remarkable success, existing COD detectors still struggle to obtain precise results in some challenging cases. To handle this problem, we draw inspiration from the prey-vs-predator game that leads preys to develop better camouflage and predators to acquire more acute vision systems and develop algorithms from both the prey side and the predator side. On the prey side, we propose an adversarial training framework, Camouflageator, which introduces an auxiliary generator to generate more camouflaged objects that are harder for a COD method to detect. Camouflageator trains the generator and detector in an adversarial way such that the enhanced auxiliary generator helps produce a stronger detector. On the predator side, we introduce a novel COD method, called Internal Coherence and Edge Guidance (ICEG), which introduces a camouflaged feature coherence module to excavate the internal coherence of camouflaged objects, striving to obtain more complete segmentation results. Additionally, ICEG proposes a novel edge-guided separated calibration module to remove false predictions to avoid obtaining ambiguous boundaries. Extensive experiments show that ICEG outperforms existing COD detectors and Camouflageator is flexible to improve various COD detectors, including ICEG, which brings state-of-the-art COD performance.
Cascade-DETR: Delving into High-Quality Universal Object Detection
Jul 20, 2023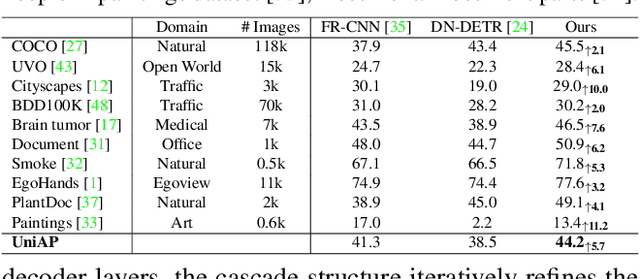
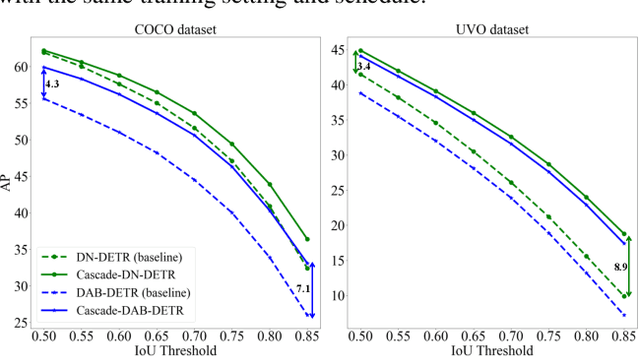

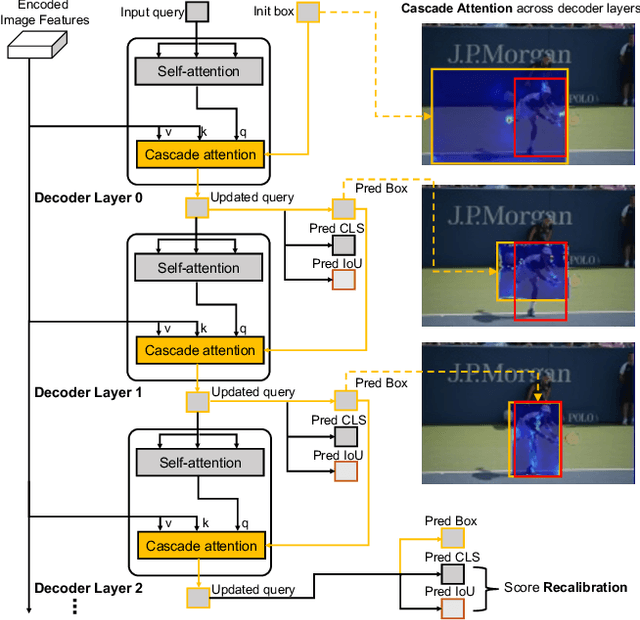
Object localization in general environments is a fundamental part of vision systems. While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains. Moreover, these methods still struggle to very accurately estimate the object bounding boxes in complex environments. We introduce Cascade-DETR for high-quality universal object detection. We jointly tackle the generalization to diverse domains and localization accuracy by proposing the Cascade Attention layer, which explicitly integrates object-centric information into the detection decoder by limiting the attention to the previous box prediction. To further enhance accuracy, we also revisit the scoring of queries. Instead of relying on classification scores, we predict the expected IoU of the query, leading to substantially more well-calibrated confidences. Lastly, we introduce a universal object detection benchmark, UDB10, that contains 10 datasets from diverse domains. While also advancing the state-of-the-art on COCO, Cascade-DETR substantially improves DETR-based detectors on all datasets in UDB10, even by over 10 mAP in some cases. The improvements under stringent quality requirements are even more pronounced. Our code and models will be released at https://github.com/SysCV/cascade-detr.
Prompting Diffusion Representations for Cross-Domain Semantic Segmentation
Jul 05, 2023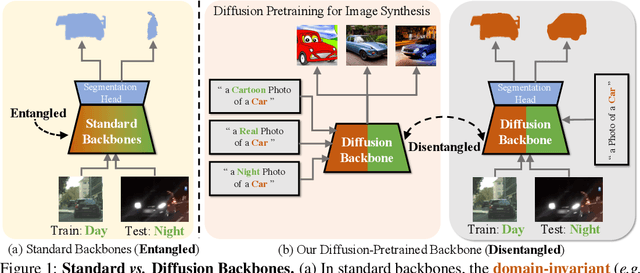

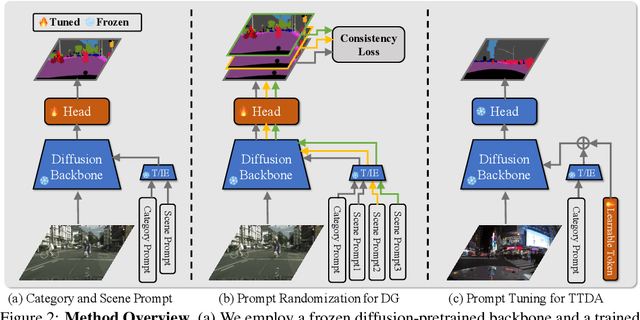
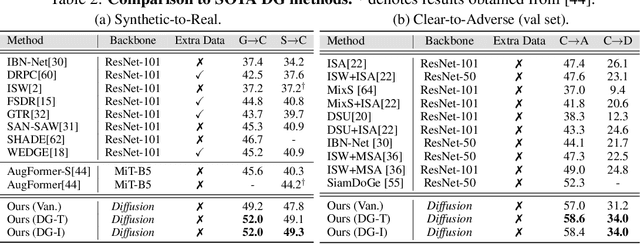
While originally designed for image generation, diffusion models have recently shown to provide excellent pretrained feature representations for semantic segmentation. Intrigued by this result, we set out to explore how well diffusion-pretrained representations generalize to new domains, a crucial ability for any representation. We find that diffusion-pretraining achieves extraordinary domain generalization results for semantic segmentation, outperforming both supervised and self-supervised backbone networks. Motivated by this, we investigate how to utilize the model's unique ability of taking an input prompt, in order to further enhance its cross-domain performance. We introduce a scene prompt and a prompt randomization strategy to help further disentangle the domain-invariant information when training the segmentation head. Moreover, we propose a simple but highly effective approach for test-time domain adaptation, based on learning a scene prompt on the target domain in an unsupervised manner. Extensive experiments conducted on four synthetic-to-real and clear-to-adverse weather benchmarks demonstrate the effectiveness of our approaches. Without resorting to any complex techniques, such as image translation, augmentation, or rare-class sampling, we set a new state-of-the-art on all benchmarks. Our implementation will be publicly available at \url{https://github.com/ETHRuiGong/PTDiffSeg}.