 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasatoshi Uehara
Regularized DeepIV with Model Selection
Mar 07, 2024

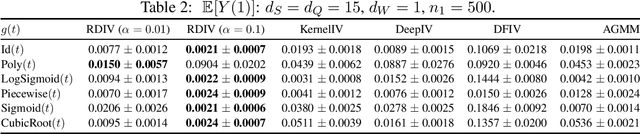
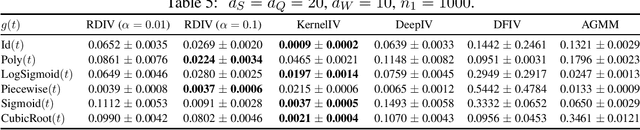
In this paper, we study nonparametric estimation of instrumental variable (IV) regressions. While recent advancements in machine learning have introduced flexible methods for IV estimation, they often encounter one or more of the following limitations: (1) restricting the IV regression to be uniquely identified; (2) requiring minimax computation oracle, which is highly unstable in practice; (3) absence of model selection procedure. In this paper, we present the first method and analysis that can avoid all three limitations, while still enabling general function approximation. Specifically, we propose a minimax-oracle-free method called Regularized DeepIV (RDIV) regression that can converge to the least-norm IV solution. Our method consists of two stages: first, we learn the conditional distribution of covariates, and by utilizing the learned distribution, we learn the estimator by minimizing a Tikhonov-regularized loss function. We further show that our method allows model selection procedures that can achieve the oracle rates in the misspecified regime. When extended to an iterative estimator, our method matches the current state-of-the-art convergence rate. Our method is a Tikhonov regularized variant of the popular DeepIV method with a non-parametric MLE first-stage estimator, and our results provide the first rigorous guarantees for this empirically used method, showcasing the importance of regularization which was absent from the original work.
Fine-Tuning of Continuous-Time Diffusion Models as Entropy-Regularized Control
Feb 28, 2024Diffusion models excel at capturing complex data distributions, such as those of natural images and proteins. While diffusion models are trained to represent the distribution in the training dataset, we often are more concerned with other properties, such as the aesthetic quality of the generated images or the functional properties of generated proteins. Diffusion models can be finetuned in a goal-directed way by maximizing the value of some reward function (e.g., the aesthetic quality of an image). However, these approaches may lead to reduced sample diversity, significant deviations from the training data distribution, and even poor sample quality due to the exploitation of an imperfect reward function. The last issue often occurs when the reward function is a learned model meant to approximate a ground-truth "genuine" reward, as is the case in many practical applications. These challenges, collectively termed "reward collapse," pose a substantial obstacle. To address this reward collapse, we frame the finetuning problem as entropy-regularized control against the pretrained diffusion model, i.e., directly optimizing entropy-enhanced rewards with neural SDEs. We present theoretical and empirical evidence that demonstrates our framework is capable of efficiently generating diverse samples with high genuine rewards, mitigating the overoptimization of imperfect reward models.
Feedback Efficient Online Fine-Tuning of Diffusion Models
Feb 27, 2024Diffusion models excel at modeling complex data distributions, including those of images, proteins, and small molecules. However, in many cases, our goal is to model parts of the distribution that maximize certain properties: for example, we may want to generate images with high aesthetic quality, or molecules with high bioactivity. It is natural to frame this as a reinforcement learning (RL) problem, in which the objective is to fine-tune a diffusion model to maximize a reward function that corresponds to some property. Even with access to online queries of the ground-truth reward function, efficiently discovering high-reward samples can be challenging: they might have a low probability in the initial distribution, and there might be many infeasible samples that do not even have a well-defined reward (e.g., unnatural images or physically impossible molecules). In this work, we propose a novel reinforcement learning procedure that efficiently explores on the manifold of feasible samples. We present a theoretical analysis providing a regret guarantee, as well as empirical validation across three domains: images, biological sequences, and molecules.
Functional Graphical Models: Structure Enables Offline Data-Driven Optimization
Jan 12, 2024While machine learning models are typically trained to solve prediction problems, we might often want to use them for optimization problems. For example, given a dataset of proteins and their corresponding fluorescence levels, we might want to optimize for a new protein with the highest possible fluorescence. This kind of data-driven optimization (DDO) presents a range of challenges beyond those in standard prediction problems, since we need models that successfully predict the performance of new designs that are better than the best designs seen in the training set. It is not clear theoretically when existing approaches can even perform better than the naive approach that simply selects the best design in the dataset. In this paper, we study how structure can enable sample-efficient data-driven optimization. To formalize the notion of structure, we introduce functional graphical models (FGMs) and show theoretically how they can provide for principled data-driven optimization by decomposing the original high-dimensional optimization problem into smaller sub-problems. This allows us to derive much more practical regret bounds for DDO, and the result implies that DDO with FGMs can achieve nearly optimal designs in situations where naive approaches fail due to insufficient coverage of the offline data. We further present a data-driven optimization algorithm that inferes the FGM structure itself, either over the original input variables or a latent variable representation of the inputs.
Source Condition Double Robust Inference on Functionals of Inverse Problems
Jul 25, 2023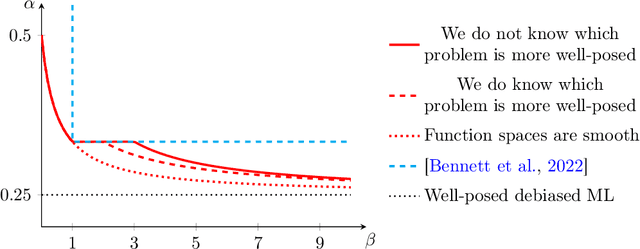
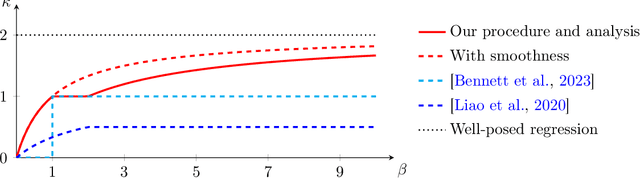
We consider estimation of parameters defined as linear functionals of solutions to linear inverse problems. Any such parameter admits a doubly robust representation that depends on the solution to a dual linear inverse problem, where the dual solution can be thought as a generalization of the inverse propensity function. We provide the first source condition double robust inference method that ensures asymptotic normality around the parameter of interest as long as either the primal or the dual inverse problem is sufficiently well-posed, without knowledge of which inverse problem is the more well-posed one. Our result is enabled by novel guarantees for iterated Tikhonov regularized adversarial estimators for linear inverse problems, over general hypothesis spaces, which are developments of independent interest.
Off-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023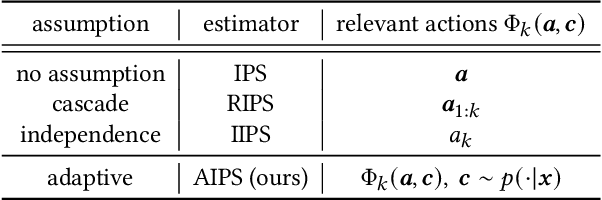
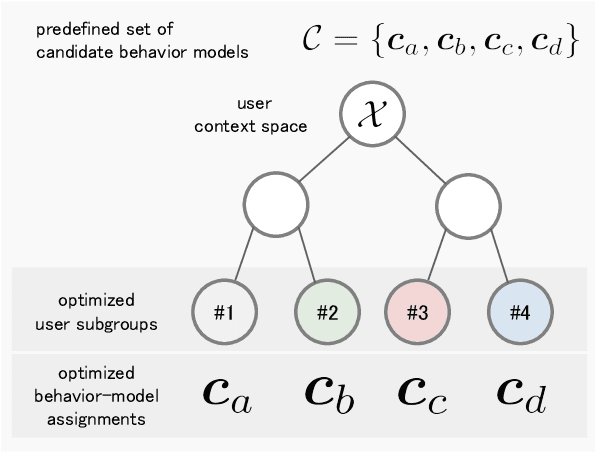
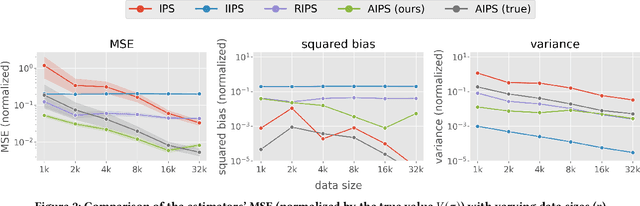
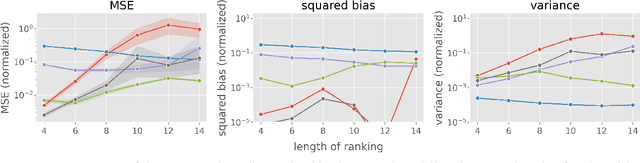
Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
How to Query Human Feedback Efficiently in RL?
May 29, 2023Reinforcement Learning with Human Feedback (RLHF) is a paradigm in which an RL agent learns to optimize a task using pair-wise preference-based feedback over trajectories, rather than explicit reward signals. While RLHF has demonstrated practical success in fine-tuning language models, existing empirical work does not address the challenge of how to efficiently sample trajectory pairs for querying human feedback. In this study, we propose an efficient sampling approach to acquiring exploratory trajectories that enable accurate learning of hidden reward functions before collecting any human feedback. Theoretical analysis demonstrates that our algorithm requires less human feedback for learning the optimal policy under preference-based models with linear parameterization and unknown transitions, compared to the existing literature. Specifically, our framework can incorporate linear and low-rank MDPs. Additionally, we investigate RLHF with action-based comparison feedback and introduce an efficient querying algorithm tailored to this scenario.
Provable Offline Reinforcement Learning with Human Feedback
May 24, 2023In this paper, we investigate the problem of offline reinforcement learning with human feedback where feedback is available in the form of preference between trajectory pairs rather than explicit rewards. Our proposed algorithm consists of two main steps: (1) estimate the implicit reward using Maximum Likelihood Estimation (MLE) with general function approximation from offline data and (2) solve a distributionally robust planning problem over a confidence set around the MLE. We consider the general reward setting where the reward can be defined over the whole trajectory and provide a novel guarantee that allows us to learn any target policy with a polynomial number of samples, as long as the target policy is covered by the offline data. This guarantee is the first of its kind with general function approximation. To measure the coverage of the target policy, we introduce a new single-policy concentrability coefficient, which can be upper bounded by the per-trajectory concentrability coefficient. We also establish lower bounds that highlight the necessity of such concentrability and the difference from standard RL, where state-action-wise rewards are directly observed. We further extend and analyze our algorithm when the feedback is given over action pairs.