 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng Wu
Revisiting Edge Perturbation for Graph Neural Network in Graph Data Augmentation and Attack
Mar 10, 2024
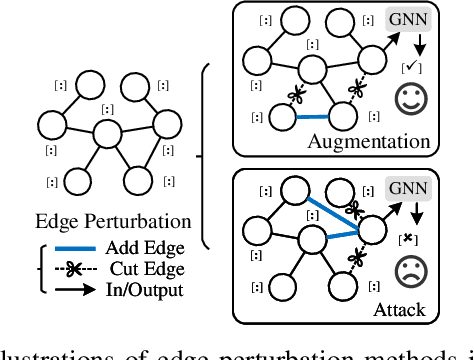
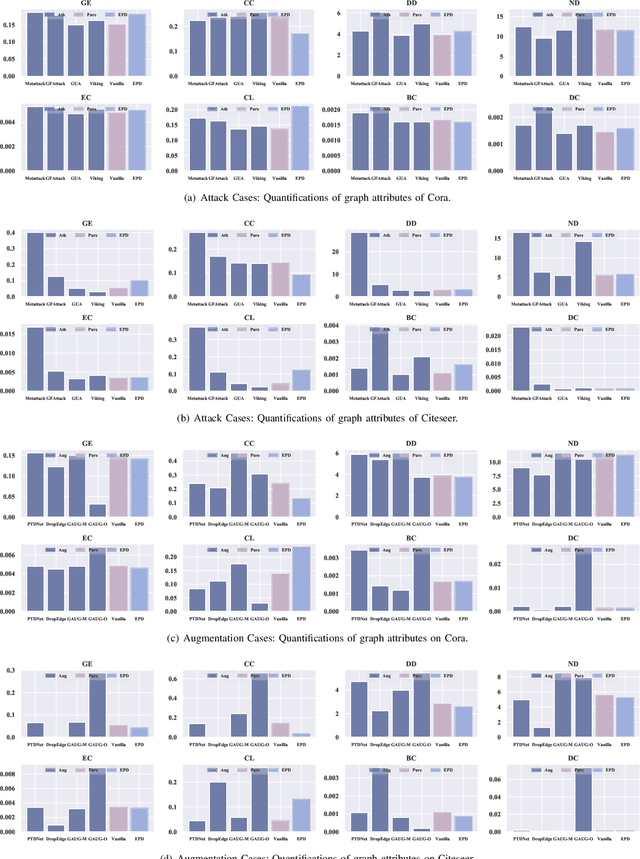
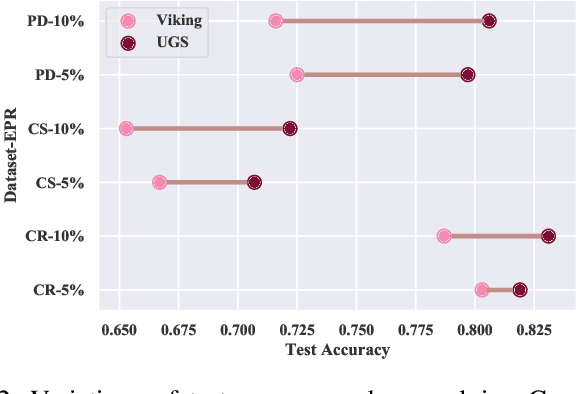
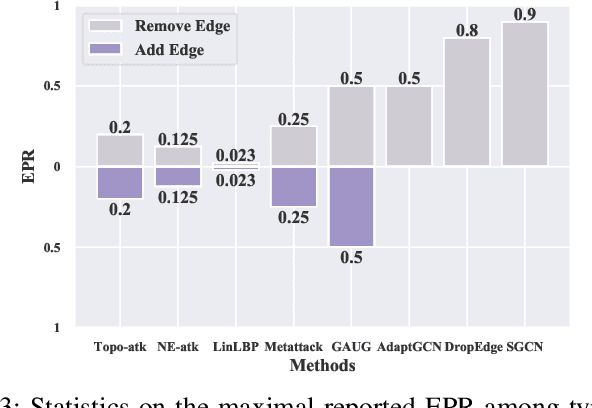
Edge perturbation is a basic method to modify graph structures. It can be categorized into two veins based on their effects on the performance of graph neural networks (GNNs), i.e., graph data augmentation and attack. Surprisingly, both veins of edge perturbation methods employ the same operations, yet yield opposite effects on GNNs' accuracy. A distinct boundary between these methods in using edge perturbation has never been clearly defined. Consequently, inappropriate perturbations may lead to undesirable outcomes, necessitating precise adjustments to achieve desired effects. Therefore, questions of ``why edge perturbation has a two-faced effect?'' and ``what makes edge perturbation flexible and effective?'' still remain unanswered. In this paper, we will answer these questions by proposing a unified formulation and establishing a clear boundary between two categories of edge perturbation methods. Specifically, we conduct experiments to elucidate the differences and similarities between these methods and theoretically unify the workflow of these methods by casting it to one optimization problem. Then, we devise Edge Priority Detector (EPD) to generate a novel priority metric, bridging these methods up in the workflow. Experiments show that EPD can make augmentation or attack flexibly and achieve comparable or superior performance to other counterparts with less time overhead.
ConUNETR: A Conditional Transformer Network for 3D Micro-CT Embryonic Cartilage Segmentation
Feb 06, 2024Studying the morphological development of cartilaginous and osseous structures is critical to the early detection of life-threatening skeletal dysmorphology. Embryonic cartilage undergoes rapid structural changes within hours, introducing biological variations and morphological shifts that limit the generalization of deep learning-based segmentation models that infer across multiple embryonic age groups. Obtaining individual models for each age group is expensive and less effective, while direct transfer (predicting an age unseen during training) suffers a potential performance drop due to morphological shifts. We propose a novel Transformer-based segmentation model with improved biological priors that better distills morphologically diverse information through conditional mechanisms. This enables a single model to accurately predict cartilage across multiple age groups. Experiments on the mice cartilage dataset show the superiority of our new model compared to other competitive segmentation models. Additional studies on a separate mice cartilage dataset with a distinct mutation show that our model generalizes well and effectively captures age-based cartilage morphology patterns.
TLMCM Network for Medical Image Hierarchical Multi-Label Classification
Nov 11, 2023Medical Image Hierarchical Multi-Label Classification (MI-HMC) is of paramount importance in modern healthcare, presenting two significant challenges: data imbalance and \textit{hierarchy constraint}. Existing solutions involve complex model architecture design or domain-specific preprocessing, demanding considerable expertise or effort in implementation. To address these limitations, this paper proposes Transfer Learning with Maximum Constraint Module (TLMCM) network for the MI-HMC task. The TLMCM network offers a novel approach to overcome the aforementioned challenges, outperforming existing methods based on the Area Under the Average Precision and Recall Curve($AU\overline{(PRC)}$) metric. In addition, this research proposes two novel accuracy metrics, $EMR$ and $HammingAccuracy$, which have not been extensively explored in the context of the MI-HMC task. Experimental results demonstrate that the TLMCM network achieves high multi-label prediction accuracy($80\%$-$90\%$) for MI-HMC tasks, making it a valuable contribution to healthcare domain applications.
Detaching and Boosting: Dual Engine for Scale-Invariant Self-Supervised Monocular Depth Estimation
Oct 08, 2022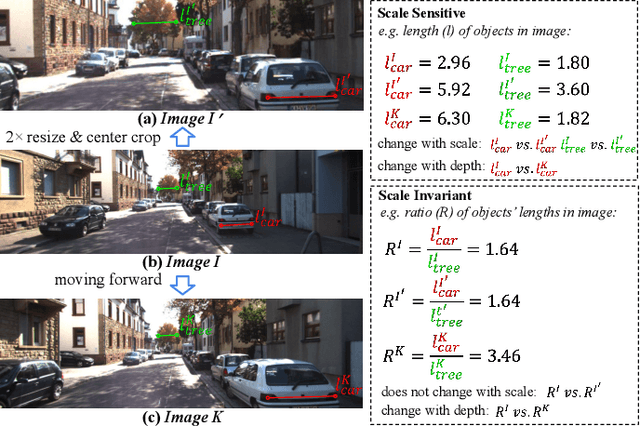
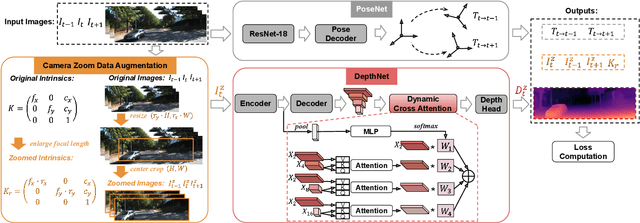
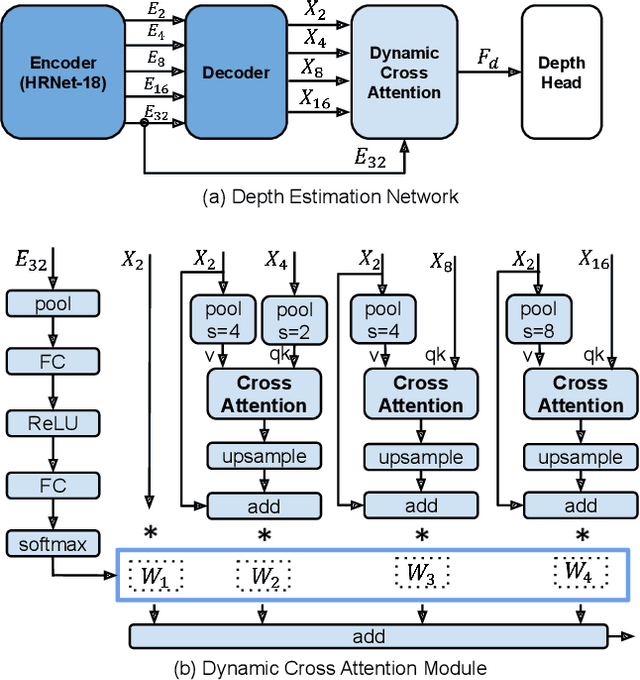
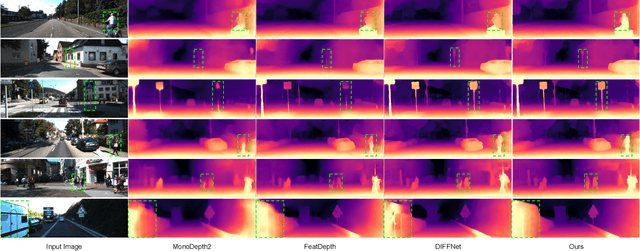
Monocular depth estimation (MDE) in the self-supervised scenario has emerged as a promising method as it refrains from the requirement of ground truth depth. Despite continuous efforts, MDE is still sensitive to scale changes especially when all the training samples are from one single camera. Meanwhile, it deteriorates further since camera movement results in heavy coupling between the predicted depth and the scale change. In this paper, we present a scale-invariant approach for self-supervised MDE, in which scale-sensitive features (SSFs) are detached away while scale-invariant features (SIFs) are boosted further. To be specific, a simple but effective data augmentation by imitating the camera zooming process is proposed to detach SSFs, making the model robust to scale changes. Besides, a dynamic cross-attention module is designed to boost SIFs by fusing multi-scale cross-attention features adaptively. Extensive experiments on the KITTI dataset demonstrate that the detaching and boosting strategies are mutually complementary in MDE and our approach achieves new State-of-The-Art performance against existing works from 0.097 to 0.090 w.r.t absolute relative error. The code will be made public soon.
Real-time Locational Marginal Price Forecasting Using Generative Adversarial Network
Nov 09, 2020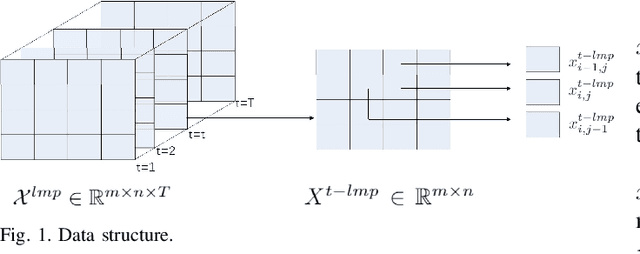
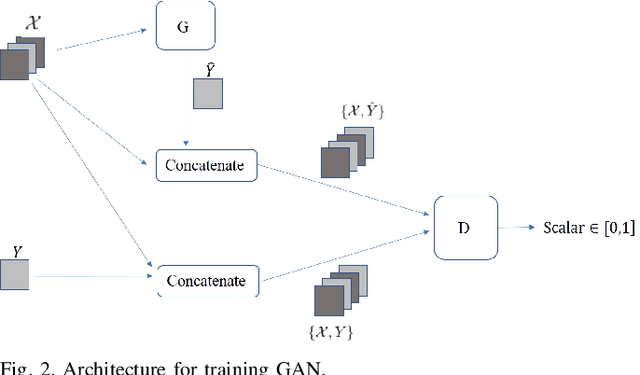
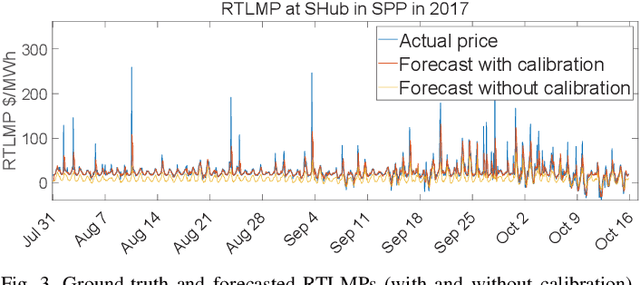
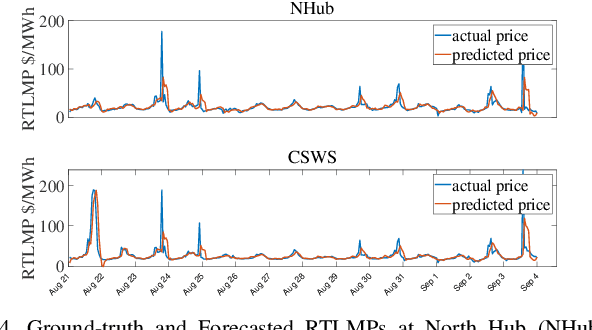
In this paper, we propose a model-free unsupervised learning approach to forecast real-time locational marginal prices (RTLMPs) in wholesale electricity markets. By organizing system-wide hourly RTLMP data into a 3-dimensional (3D) tensor consisting of a series of time-indexed matrices, we formulate the RTLMP forecasting problem as a problem of generating the next matrix with forecasted RTLMPs given the historical RTLMP tensor, and propose a generative adversarial network (GAN) model to forecast RTLMPs. The proposed formulation preserves the spatio-temporal correlations among system-wide RTLMPs in the format of historical RTLMP tensor. The proposed GAN model learns the spatio-temporal correlations using the historical RTLMP tensors and generate RTLMPs that are statistically similar and temporally coherent to the historical RTLMP tensor. The proposed approach forecasts system-wide RTLMPs using only publicly available historical price data, without involving confidential information of system model, such as system parameters, topology, or operating conditions. The effectiveness of the proposed approach is verified through case studies using historical RTLMP data in Southwest Power Pool (SPP).
Predicting Real-Time Locational Marginal Prices: A GAN-Based Video Prediction Approach
Mar 20, 2020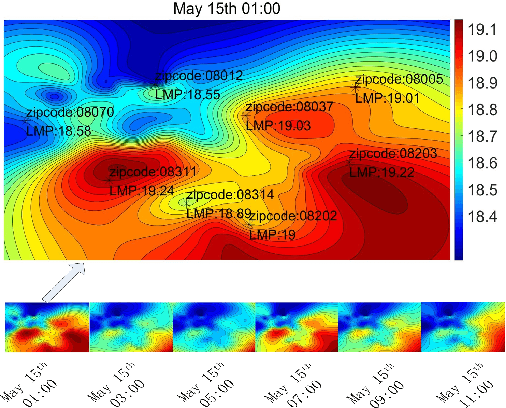

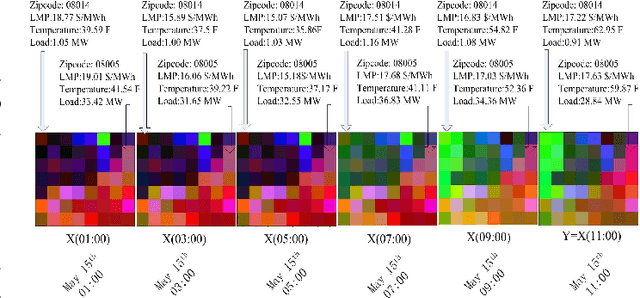
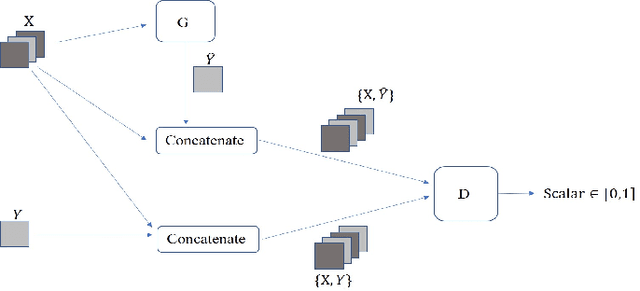
In this paper, we propose an unsupervised data-driven approach to predict real-time locational marginal prices (RTLMPs). The proposed approach is built upon a general data structure for organizing system-wide heterogeneous market data streams into the format of market data images and videos. Leveraging this general data structure, the system-wide RTLMP prediction problem is formulated as a video prediction problem. A video prediction model based on generative adversarial networks (GAN) is proposed to learn the spatio-temporal correlations among historical RTLMPs and predict system-wide RTLMPs for the next hour. An autoregressive moving average (ARMA) calibration method is adopted to improve the prediction accuracy. The proposed RTLMP prediction method takes public market data as inputs, without requiring any confidential information on system topology, model parameters, or market operating details. Case studies using public market data from ISO New England (ISO-NE) and Southwest Power Pool (SPP) demonstrate that the proposed method is able to learn spatio-temporal correlations among RTLMPs and perform accurate RTLMP prediction.
Shield Synthesis for Real: Enforcing Safety in Cyber-Physical Systems
Aug 15, 2019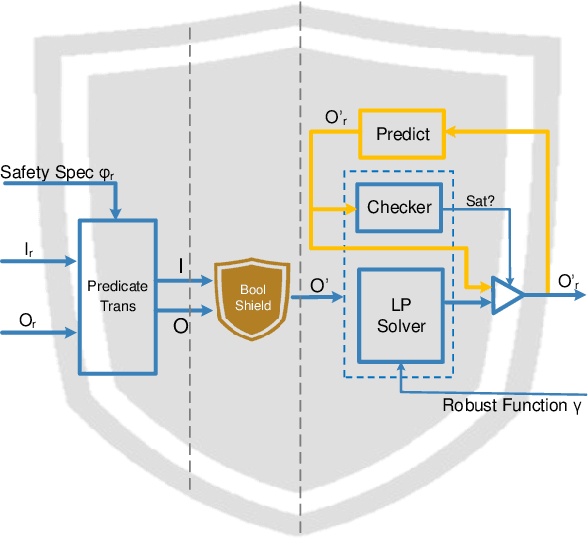
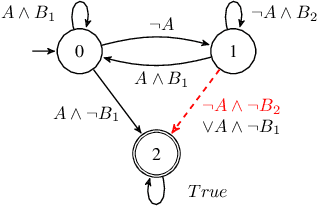
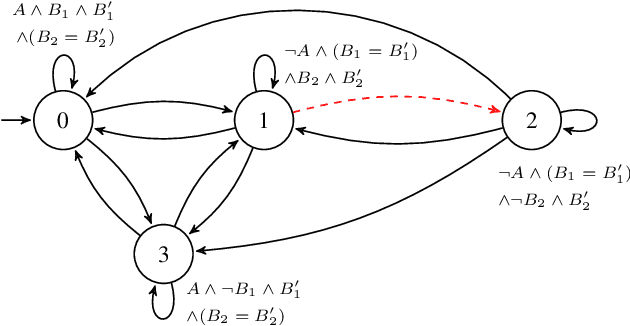
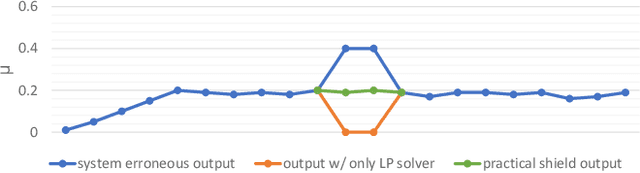
Cyber-physical systems are often safety-critical in that violations of safety properties may lead to catastrophes. We propose a method to enforce the safety of systems with real-valued signals by synthesizing a runtime enforcer called the shield. Whenever the system violates a property, the shield, composed with the system, makes correction instantaneously to ensure that no erroneous output is generated by the combined system. While techniques for synthesizing Boolean shields are well understood, they do not handle real-valued signals ubiquitous in cyber-physical systems, meaning corrections may be either unrealizable or inefficient to compute in the real domain. We solve the realizability and efficiency problems by statically analyzing the compatibility of predicates defined over real-valued signals, and using the analysis result to constrain a two-player safety game used to synthesize the shield. We have implemented the method and demonstrated its effectiveness and efficiency on a variety of applications, including an automotive powertrain control system.
G-flocking: Flocking Model Optimization based on Genetic Framework
Jul 27, 2019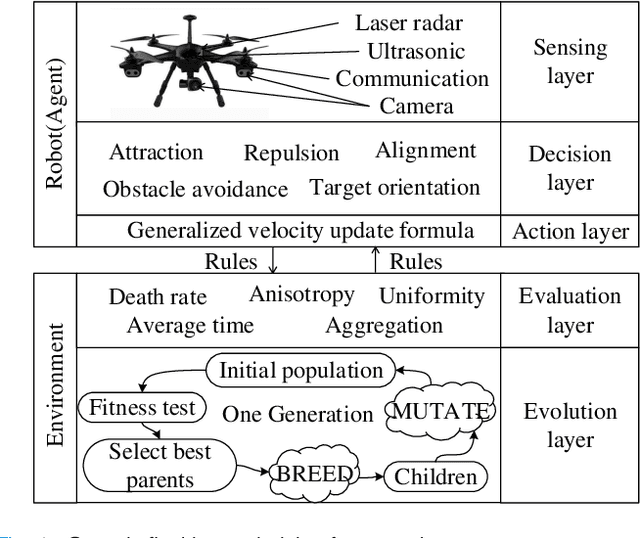

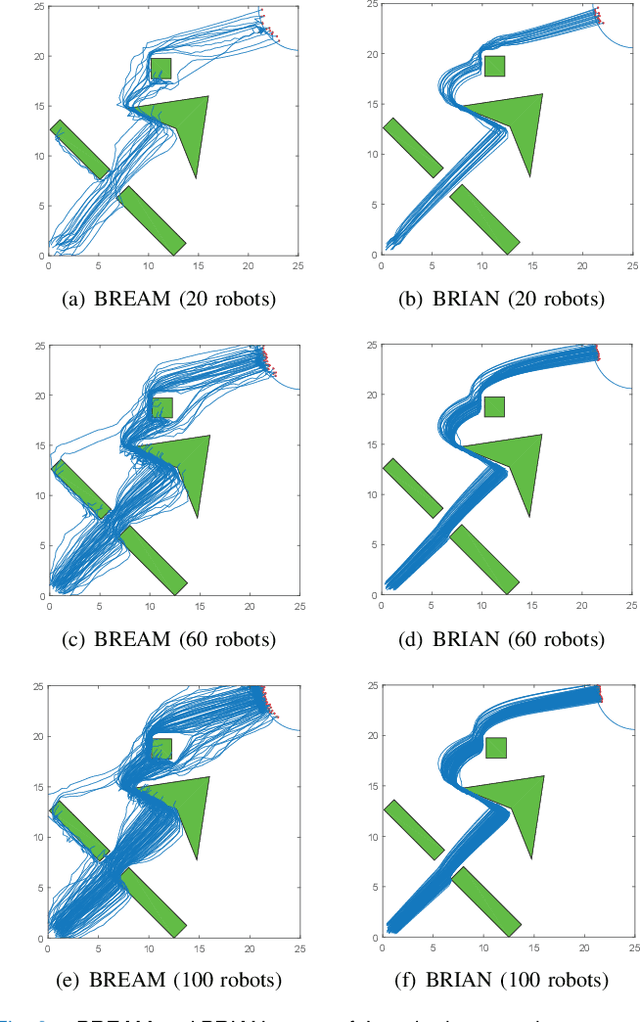
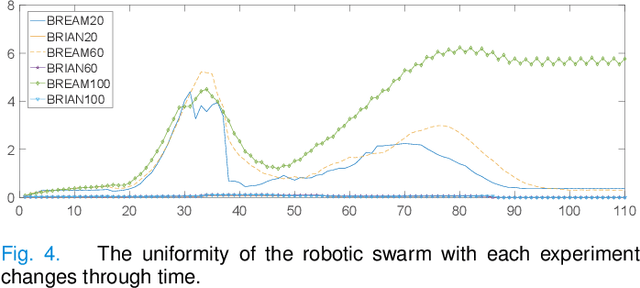
Flocking model has been widely used to control robotic swarm. However, with the increasing scalability, there exist complex conflicts for robotic swarm in autonomous navigation, brought by internal pattern maintenance, external environment changes, and target area orientation, which results in poor stability and adaptability. Hence, optimizing the flocking model for robotic swarm in autonomous navigation is an important and meaningful research domain.