 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengkang Hu
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024
Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.
Tree-Planner: Efficient Close-loop Task Planning with Large Language Models
Oct 12, 2023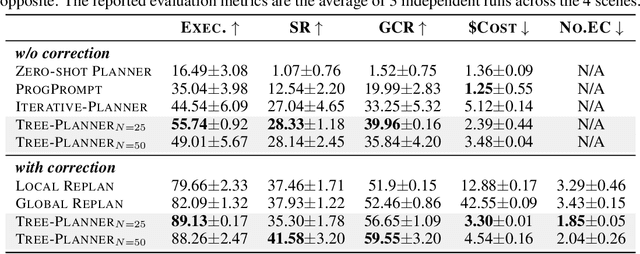
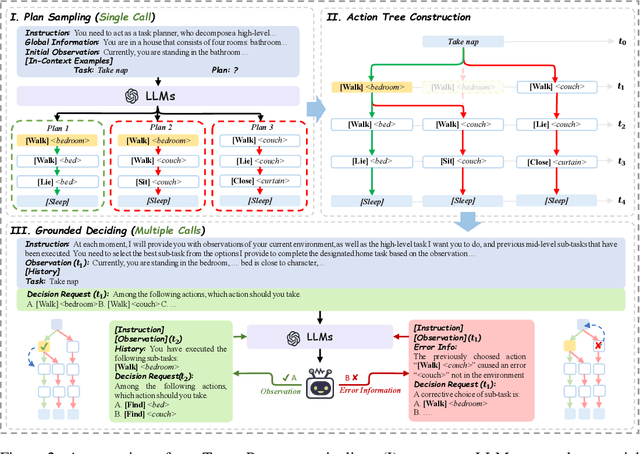
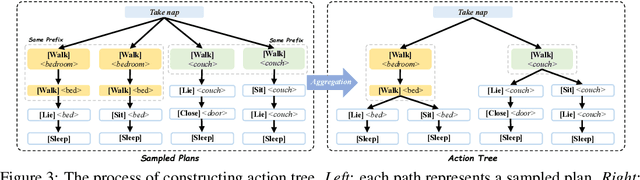

This paper studies close-loop task planning, which refers to the process of generating a sequence of skills (a plan) to accomplish a specific goal while adapting the plan based on real-time observations. Recently, prompting Large Language Models (LLMs) to generate actions iteratively has become a prevalent paradigm due to its superior performance and user-friendliness. However, this paradigm is plagued by two inefficiencies: high token consumption and redundant error correction, both of which hinder its scalability for large-scale testing and applications. To address these issues, we propose Tree-Planner, which reframes task planning with LLMs into three distinct phases: plan sampling, action tree construction, and grounded deciding. Tree-Planner starts by using an LLM to sample a set of potential plans before execution, followed by the aggregation of them to form an action tree. Finally, the LLM performs a top-down decision-making process on the tree, taking into account real-time environmental information. Experiments show that Tree-Planner achieves state-of-the-art performance while maintaining high efficiency. By decomposing LLM queries into a single plan-sampling call and multiple grounded-deciding calls, a considerable part of the prompt are less likely to be repeatedly consumed. As a result, token consumption is reduced by 92.2% compared to the previously best-performing model. Additionally, by enabling backtracking on the action tree as needed, the correction process becomes more flexible, leading to a 40.5% decrease in error corrections. Project page: https://tree-planner.github.io/
EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
May 24, 2023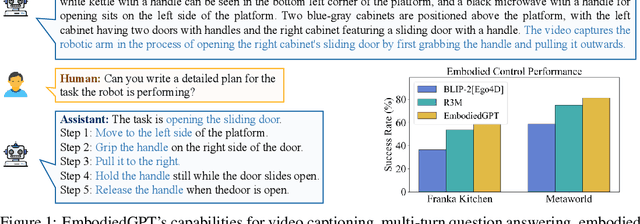

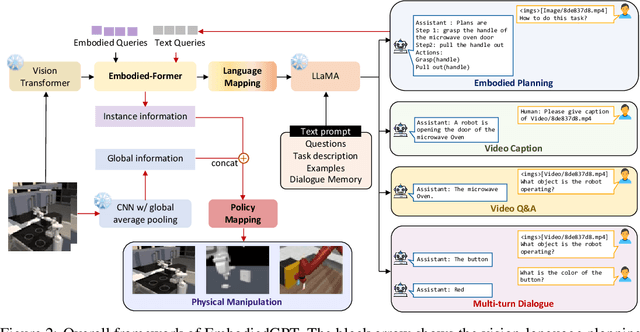
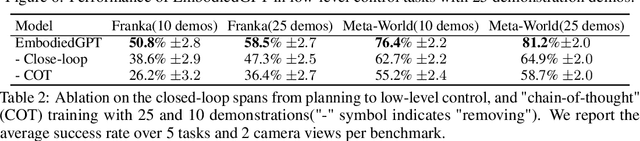
Embodied AI is a crucial frontier in robotics, capable of planning and executing action sequences for robots to accomplish long-horizon tasks in physical environments. In this work, we introduce EmbodiedGPT, an end-to-end multi-modal foundation model for embodied AI, empowering embodied agents with multi-modal understanding and execution capabilities. To achieve this, we have made the following efforts: (i) We craft a large-scale embodied planning dataset, termed EgoCOT. The dataset consists of carefully selected videos from the Ego4D dataset, along with corresponding high-quality language instructions. Specifically, we generate a sequence of sub-goals with the "Chain of Thoughts" mode for effective embodied planning. (ii) We introduce an efficient training approach to EmbodiedGPT for high-quality plan generation, by adapting a 7B large language model (LLM) to the EgoCOT dataset via prefix tuning. (iii) We introduce a paradigm for extracting task-related features from LLM-generated planning queries to form a closed loop between high-level planning and low-level control. Extensive experiments show the effectiveness of EmbodiedGPT on embodied tasks, including embodied planning, embodied control, visual captioning, and visual question answering. Notably, EmbodiedGPT significantly enhances the success rate of the embodied control task by extracting more effective features. It has achieved a remarkable 1.6 times increase in success rate on the Franka Kitchen benchmark and a 1.3 times increase on the Meta-World benchmark, compared to the BLIP-2 baseline fine-tuned with the Ego4D dataset.
TaCube: Pre-computing Data Cubes for Answering Numerical-Reasoning Questions over Tabular Data
May 25, 2022

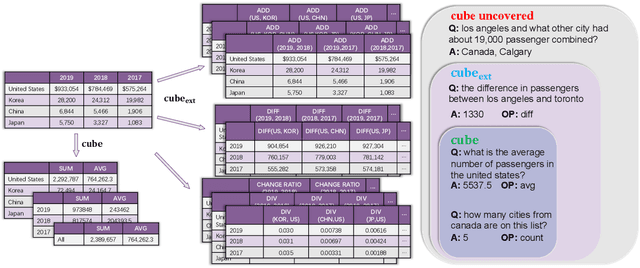
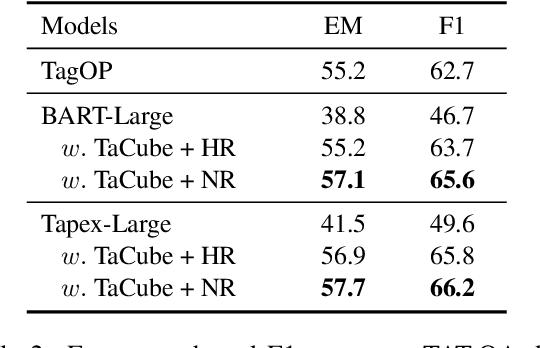
Existing auto-regressive pre-trained language models (PLMs) like T5 and BART, have been well applied to table question answering by UNIFIEDSKG and TAPEX, respectively, and demonstrated state-of-the-art results on multiple benchmarks. However, auto-regressive PLMs are challenged by recent emerging numerical reasoning datasets, such as TAT-QA, due to the error-prone implicit calculation. In this paper, we present TaCube, to pre-compute aggregation/arithmetic results for the table in advance, so that they are handy and readily available for PLMs to answer numerical reasoning questions. TaCube systematically and comprehensively covers a collection of computational operations over table segments. By simply concatenating TaCube to the input sequence of PLMs, it shows significant experimental effectiveness. TaCube promotes the F1 score from 49.6% to 66.2% on TAT-QA and achieves new state-of-the-art results on WikiTQ (59.6% denotation accuracy). TaCube's improvements on numerical reasoning cases are even more notable: on TAT-QA, TaCube promotes the exact match accuracy of BART-large by 39.6% on sum, 52.5% on average, 36.6% on substraction, and 22.2% on division. We believe that TaCube is a general and portable pre-computation solution that can be potentially integrated to various numerical reasoning frameworks