 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinpeng Liao
AlphaMath Almost Zero: process Supervision without process
May 06, 2024
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.
MARIO: MAth Reasoning with code Interpreter Output -- A Reproducible Pipeline
Jan 16, 2024Large language models (LLMs) have seen considerable advancements in natural language understanding tasks, yet there remains a gap to bridge before attaining true artificial general intelligence, especially concerning shortcomings in mathematical reasoning capabilities. We postulate that the inherent nature of LLM training, which focuses on predicting probabilities of next token, presents challenges in effectively modeling mathematical reasoning that demands exact calculations, both from data-driven and theoretical standpoints. In this paper, we address this challenge by enriching the data landscape and introducing a novel math dataset, enhanced with a capability to utilize a Python code interpreter. This dataset is derived from GSM8K and MATH and has been further refined through a combination of GPT-4 annotations, human review, and self-training processes, where the errors in the original GSM8K training set have been fixed. Additionally, we propose a tentative, easily replicable protocol for the fine-tuning of math-specific LLMs, which has led to a significant improvement in the performance of a 7B-parameter LLM on the GSM8K and MATH datasets. We are committed to advancing the field of mathematical reasoning in LLMs and, to that end, we have made the model checkpoints and will make the dataset publicly available. We hope this will facilitate further research and development within the community.
BLSP: Bootstrapping Language-Speech Pre-training via Behavior Alignment of Continuation Writing
Sep 02, 2023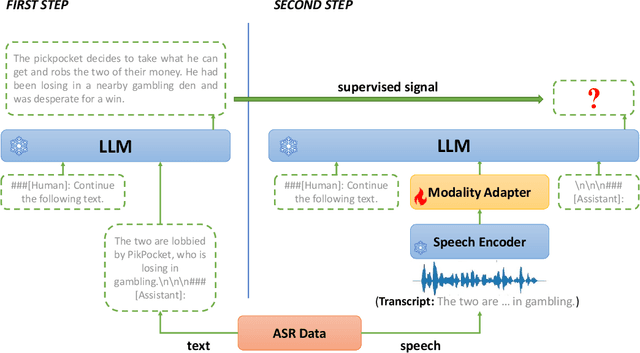


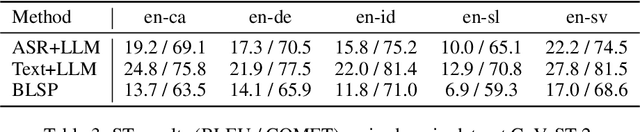
The emergence of large language models (LLMs) has sparked significant interest in extending their remarkable language capabilities to speech. However, modality alignment between speech and text still remains an open problem. Current solutions can be categorized into two strategies. One is a cascaded approach where outputs (tokens or states) of a separately trained speech recognition system are used as inputs for LLMs, which limits their potential in modeling alignment between speech and text. The other is an end-to-end approach that relies on speech instruction data, which is very difficult to collect in large quantities. In this paper, we address these issues and propose the BLSP approach that Bootstraps Language-Speech Pre-training via behavior alignment of continuation writing. We achieve this by learning a lightweight modality adapter between a frozen speech encoder and an LLM, ensuring that the LLM exhibits the same generation behavior regardless of the modality of input: a speech segment or its transcript. The training process can be divided into two steps. The first step prompts an LLM to generate texts with speech transcripts as prefixes, obtaining text continuations. In the second step, these continuations are used as supervised signals to train the modality adapter in an end-to-end manner. We demonstrate that this straightforward process can extend the capabilities of LLMs to speech, enabling speech recognition, speech translation, spoken language understanding, and speech conversation, even in zero-shot cross-lingual scenarios.
Adapting Offline Speech Translation Models for Streaming with Future-Aware Distillation and Inference
Mar 14, 2023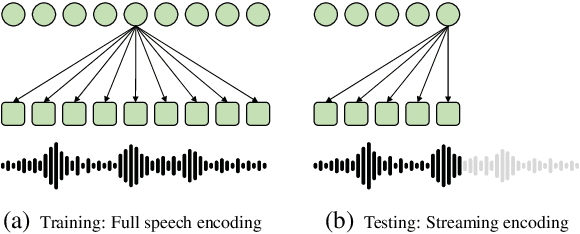
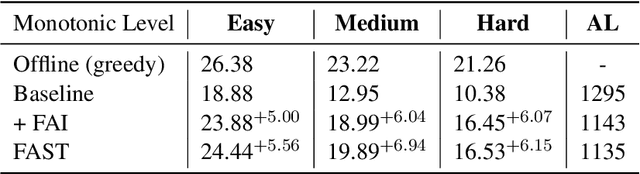
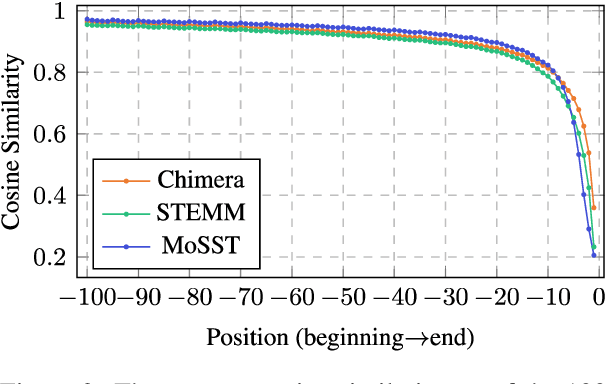
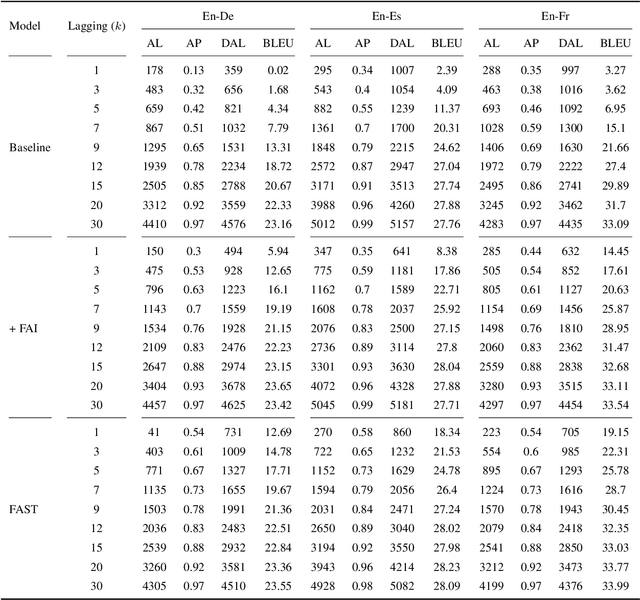
A popular approach to streaming speech translation is to employ a single offline model with a \textit{wait-$k$} policy to support different latency requirements, which is simpler than training multiple online models with different latency constraints. However, there is a mismatch problem in using a model trained with complete utterances for streaming inference with partial input. We demonstrate that speech representations extracted at the end of a streaming input are significantly different from those extracted from a complete utterance. To address this issue, we propose a new approach called Future-Aware Streaming Translation (FAST) that adapts an offline ST model for streaming input. FAST includes a Future-Aware Inference (FAI) strategy that incorporates future context through a trainable masked embedding, and a Future-Aware Distillation (FAD) framework that transfers future context from an approximation of full speech to streaming input. Our experiments on the MuST-C EnDe, EnEs, and EnFr benchmarks show that FAST achieves better trade-offs between translation quality and latency than strong baselines. Extensive analyses suggest that our methods effectively alleviate the aforementioned mismatch problem between offline training and online inference.