 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKai Fan
AlphaMath Almost Zero: process Supervision without process
May 06, 2024
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.
MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit
Apr 22, 2024Large language models (LLMs) have been explored in a variety of reasoning tasks including solving of mathematical problems. Each math dataset typically includes its own specially designed evaluation script, which, while suitable for its intended use, lacks generalizability across different datasets. Consequently, updates and adaptations to these evaluation tools tend to occur without being systematically reported, leading to inconsistencies and obstacles to fair comparison across studies. To bridge this gap, we introduce a comprehensive mathematical evaluation toolkit that not only utilizes a python computer algebra system (CAS) for its numerical accuracy, but also integrates an optional LLM, known for its considerable natural language processing capabilities. To validate the effectiveness of our toolkit, we manually annotated two distinct datasets. Our experiments demonstrate that the toolkit yields more robust evaluation results compared to prior works, even without an LLM. Furthermore, when an LLM is incorporated, there is a notable enhancement. The code for our method will be made available at \url{https://github.com/MARIO-Math-Reasoning/math_evaluation}.
MARIO: MAth Reasoning with code Interpreter Output -- A Reproducible Pipeline
Jan 16, 2024Large language models (LLMs) have seen considerable advancements in natural language understanding tasks, yet there remains a gap to bridge before attaining true artificial general intelligence, especially concerning shortcomings in mathematical reasoning capabilities. We postulate that the inherent nature of LLM training, which focuses on predicting probabilities of next token, presents challenges in effectively modeling mathematical reasoning that demands exact calculations, both from data-driven and theoretical standpoints. In this paper, we address this challenge by enriching the data landscape and introducing a novel math dataset, enhanced with a capability to utilize a Python code interpreter. This dataset is derived from GSM8K and MATH and has been further refined through a combination of GPT-4 annotations, human review, and self-training processes, where the errors in the original GSM8K training set have been fixed. Additionally, we propose a tentative, easily replicable protocol for the fine-tuning of math-specific LLMs, which has led to a significant improvement in the performance of a 7B-parameter LLM on the GSM8K and MATH datasets. We are committed to advancing the field of mathematical reasoning in LLMs and, to that end, we have made the model checkpoints and will make the dataset publicly available. We hope this will facilitate further research and development within the community.
Adaptive Policy with Wait-$k$ Model for Simultaneous Translation
Oct 23, 2023Simultaneous machine translation (SiMT) requires a robust read/write policy in conjunction with a high-quality translation model. Traditional methods rely on either a fixed wait-$k$ policy coupled with a standalone wait-$k$ translation model, or an adaptive policy jointly trained with the translation model. In this study, we propose a more flexible approach by decoupling the adaptive policy model from the translation model. Our motivation stems from the observation that a standalone multi-path wait-$k$ model performs competitively with adaptive policies utilized in state-of-the-art SiMT approaches. Specifically, we introduce DaP, a divergence-based adaptive policy, that makes read/write decisions for any translation model based on the potential divergence in translation distributions resulting from future information. DaP extends a frozen wait-$k$ model with lightweight parameters, and is both memory and computation efficient. Experimental results across various benchmarks demonstrate that our approach offers an improved trade-off between translation accuracy and latency, outperforming strong baselines.
Neural Machine Translation with Dynamic Graph Convolutional Decoder
May 28, 2023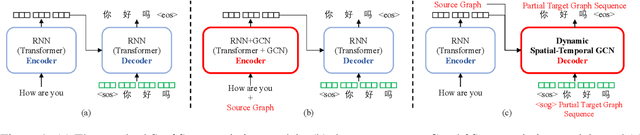
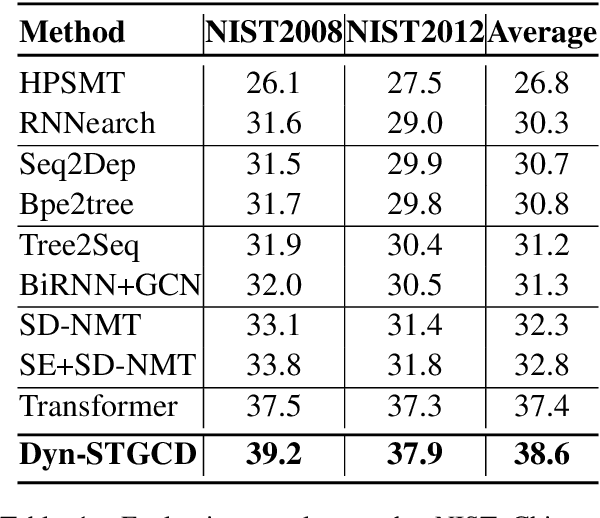
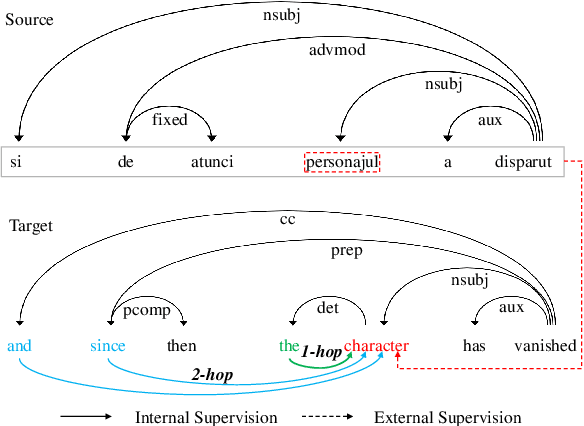
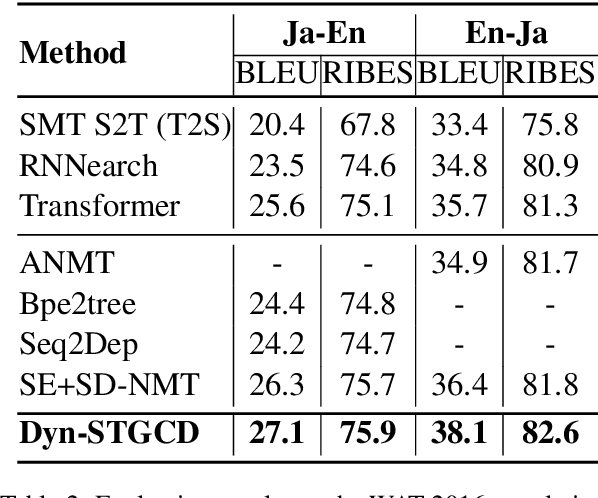
Existing wisdom demonstrates the significance of syntactic knowledge for the improvement of neural machine translation models. However, most previous works merely focus on leveraging the source syntax in the well-known encoder-decoder framework. In sharp contrast, this paper proposes an end-to-end translation architecture from the (graph \& sequence) structural inputs to the (graph \& sequence) outputs, where the target translation and its corresponding syntactic graph are jointly modeled and generated. We propose a customized Dynamic Spatial-Temporal Graph Convolutional Decoder (Dyn-STGCD), which is designed for consuming source feature representations and their syntactic graph, and auto-regressively generating the target syntactic graph and tokens simultaneously. We conduct extensive experiments on five widely acknowledged translation benchmarks, verifying that our proposal achieves consistent improvements over baselines and other syntax-aware variants.
Translate the Beauty in Songs: Jointly Learning to Align Melody and Translate Lyrics
Mar 28, 2023
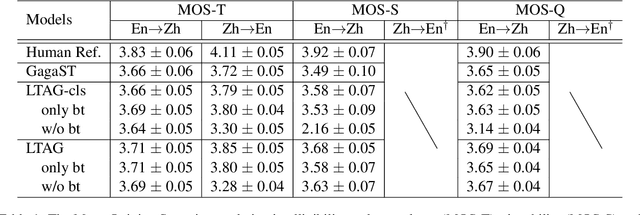
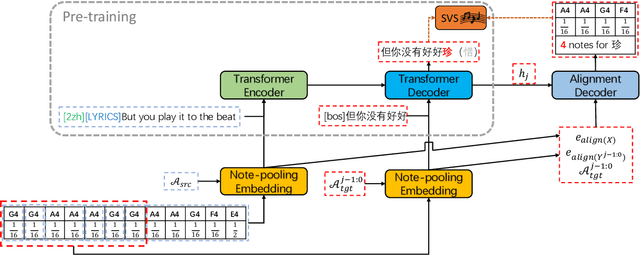
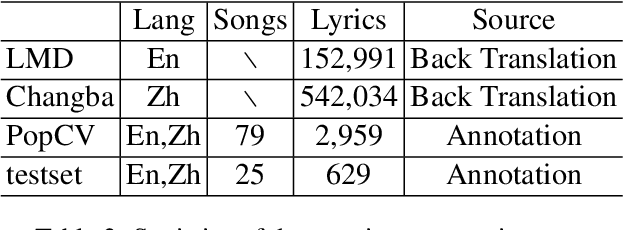
Song translation requires both translation of lyrics and alignment of music notes so that the resulting verse can be sung to the accompanying melody, which is a challenging problem that has attracted some interests in different aspects of the translation process. In this paper, we propose Lyrics-Melody Translation with Adaptive Grouping (LTAG), a holistic solution to automatic song translation by jointly modeling lyrics translation and lyrics-melody alignment. It is a novel encoder-decoder framework that can simultaneously translate the source lyrics and determine the number of aligned notes at each decoding step through an adaptive note grouping module. To address data scarcity, we commissioned a small amount of training data annotated specifically for this task and used large amounts of augmented data through back-translation. Experiments conducted on an English-Chinese song translation data set show the effectiveness of our model in both automatic and human evaluation.
Adapting Offline Speech Translation Models for Streaming with Future-Aware Distillation and Inference
Mar 14, 2023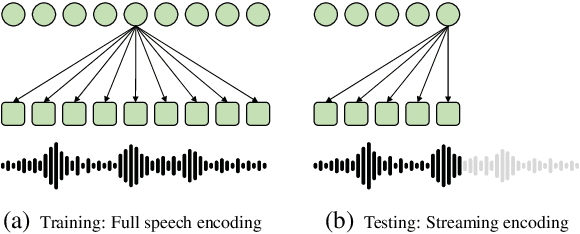
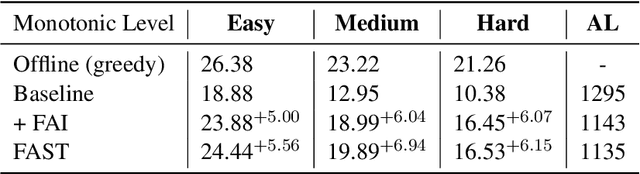
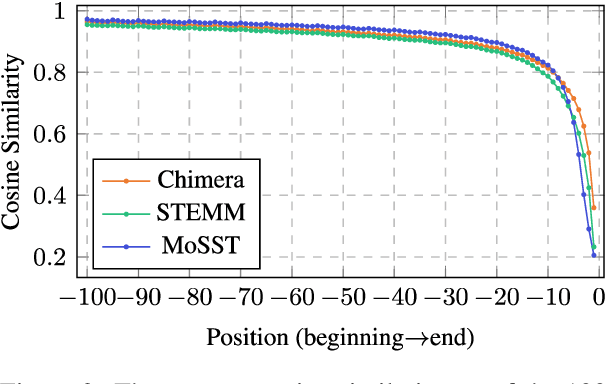
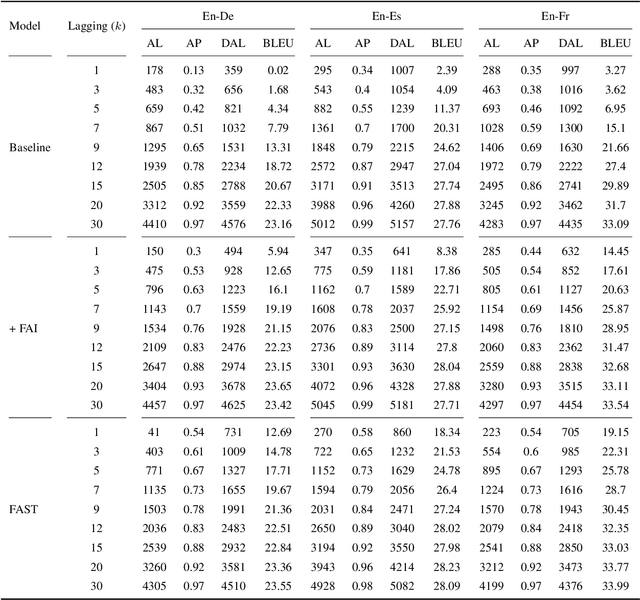
A popular approach to streaming speech translation is to employ a single offline model with a \textit{wait-$k$} policy to support different latency requirements, which is simpler than training multiple online models with different latency constraints. However, there is a mismatch problem in using a model trained with complete utterances for streaming inference with partial input. We demonstrate that speech representations extracted at the end of a streaming input are significantly different from those extracted from a complete utterance. To address this issue, we propose a new approach called Future-Aware Streaming Translation (FAST) that adapts an offline ST model for streaming input. FAST includes a Future-Aware Inference (FAI) strategy that incorporates future context through a trainable masked embedding, and a Future-Aware Distillation (FAD) framework that transfers future context from an approximation of full speech to streaming input. Our experiments on the MuST-C EnDe, EnEs, and EnFr benchmarks show that FAST achieves better trade-offs between translation quality and latency than strong baselines. Extensive analyses suggest that our methods effectively alleviate the aforementioned mismatch problem between offline training and online inference.
Competency-Aware Neural Machine Translation: Can Machine Translation Know its Own Translation Quality?
Nov 25, 2022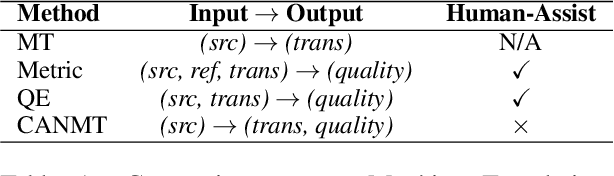
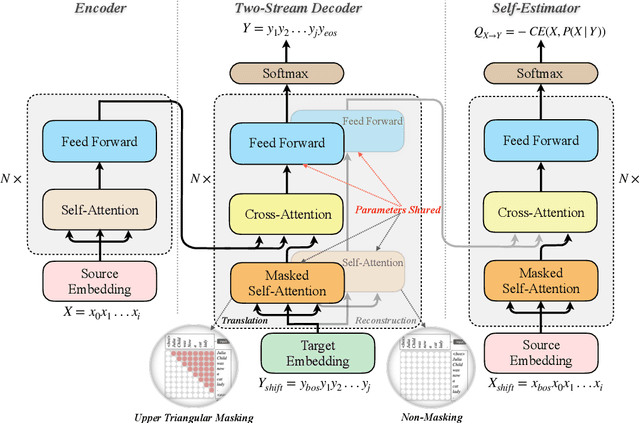
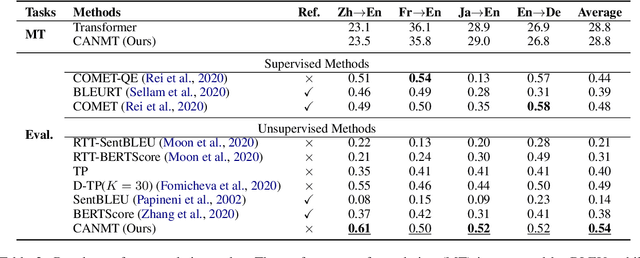

Neural machine translation (NMT) is often criticized for failures that happen without awareness. The lack of competency awareness makes NMT untrustworthy. This is in sharp contrast to human translators who give feedback or conduct further investigations whenever they are in doubt about predictions. To fill this gap, we propose a novel competency-aware NMT by extending conventional NMT with a self-estimator, offering abilities to translate a source sentence and estimate its competency. The self-estimator encodes the information of the decoding procedure and then examines whether it can reconstruct the original semantics of the source sentence. Experimental results on four translation tasks demonstrate that the proposed method not only carries out translation tasks intact but also delivers outstanding performance on quality estimation. Without depending on any reference or annotated data typically required by state-of-the-art metric and quality estimation methods, our model yields an even higher correlation with human quality judgments than a variety of aforementioned methods, such as BLEURT, COMET, and BERTScore. Quantitative and qualitative analyses show better robustness of competency awareness in our model.
A scalable pipeline for COVID-19: the case study of Germany, Czechia and Poland
Aug 27, 2022



Throughout the coronavirus disease 2019 (COVID-19) pandemic, decision makers have relied on forecasting models to determine and implement non-pharmaceutical interventions (NPI). In building the forecasting models, continuously updated datasets from various stakeholders including developers, analysts, and testers are required to provide precise predictions. Here we report the design of a scalable pipeline which serves as a data synchronization to support inter-country top-down spatiotemporal observations and forecasting models of COVID-19, named the where2test, for Germany, Czechia and Poland. We have built an operational data store (ODS) using PostgreSQL to continuously consolidate datasets from multiple data sources, perform collaborative work, facilitate high performance data analysis, and trace changes. The ODS has been built not only to store the COVID-19 data from Germany, Czechia, and Poland but also other areas. Employing the dimensional fact model, a schema of metadata is capable of synchronizing the various structures of data from those regions, and is scalable to the entire world. Next, the ODS is populated using batch Extract, Transfer, and Load (ETL) jobs. The SQL queries are subsequently created to reduce the need for pre-processing data for users. The data can then support not only forecasting using a version-controlled Arima-Holt model and other analyses to support decision making, but also risk calculator and optimisation apps. The data synchronization runs at a daily interval, which is displayed at https://www.where2test.de.
Efficient Cluster-Based k-Nearest-Neighbor Machine Translation
Apr 13, 2022



k-Nearest-Neighbor Machine Translation (kNN-MT) has been recently proposed as a non-parametric solution for domain adaptation in neural machine translation (NMT). It aims to alleviate the performance degradation of advanced MT systems in translating out-of-domain sentences by coordinating with an additional token-level feature-based retrieval module constructed from in-domain data. Previous studies have already demonstrated that non-parametric NMT is even superior to models fine-tuned on out-of-domain data. In spite of this success, kNN retrieval is at the expense of high latency, in particular for large datastores. To make it practical, in this paper, we explore a more efficient kNN-MT and propose to use clustering to improve the retrieval efficiency. Concretely, we first propose a cluster-based Compact Network for feature reduction in a contrastive learning manner to compress context features into 90+% lower dimensional vectors. We then suggest a cluster-based pruning solution to filter out 10%-40% redundant nodes in large datastores while retaining translation quality. Our proposed methods achieve better or comparable performance while reducing up to 57% inference latency against the advanced non-parametric MT model on several machine translation benchmarks. Experimental results indicate that the proposed methods maintain the most useful information of the original datastore and the Compact Network shows good generalization on unseen domains.